Indian Prime Minister Narendra Modi has offered a valuable tip to enhance cybersecurity for home PCs and laptops: consistently logging out of Microsoft Windows sessions. This advice applies universally across Windows 10 and Windows 11 operating systems.
Highlighting this cybersecurity principle, Prime Minister Modi emphasized its critical application in both private and public sectors. He suggested assigning responsibility for logging out at the end of each day in IT environments.
From a technical standpoint, regularly logging out clears session caches accumulated since initial login, reducing network interception opportunities. This measure mitigates risks such as malware interception upon visiting malicious websites, which can exploit vulnerabilities through open browsers.
By logging out, all active programs are closed, effectively severing remote desktop connections and bolstering security by safeguarding files, apps, and settings from unauthorized access.
Additionally, covering laptop cameras and microphones is recommended to prevent potential eavesdropping and unauthorized video or audio capture, a practice endorsed by figures like Facebook’s Mark Zuckerberg, reportedly influenced by advice from Windows OS founder Bill Gates.
These proactive steps advocated by Prime Minister Modi and supported by industry leaders contribute to bolstering cybersecurity hygiene and protecting sensitive information from unauthorized access.
Alert fatigue represents more than a mere inconvenience for Security Operations Centre (SOC) teams; it poses a tangible threat to enterprise security. When analysts confront a deluge of thousands of alerts daily, each necessitating triage, investigation, and correlation, valuable time is easily squandered on false positives, potentially overlooking genuine indicators of an enterprise-wide data breach.
On average, SOC teams contend with nearly 500 investigation-worthy endpoint security alerts each week, with ensuing investigations consuming 65% of their time. Compounding the issue, security teams grapple with under-resourcing, understaffing, and the burden of manual processes.
These hurdles not only frustrate SOC team members, leading to stress, burnout, and turnover, but also detrimentally impact the organisation’s overall security posture. An operation-centric approach is imperative to effectively address these challenges, enabling the correlation of alerts, identification of root causes, provision of complete visibility into attack timelines, and simultaneous automation of tasks to enhance analyst efficiency significantly.
The relentless barrage of security alerts inundating SOC teams poses more than just a nuisance; it constitutes a genuine threat to enterprise security. The phenomenon known as alert fatigue not only overwhelms analysts but also compromises the ability to discern genuine threats amidst the noise, potentially leading to catastrophic consequences for organisational security.
At the core of alert fatigue lies information overload, exacerbated by the design of Security Information and Event Management (SIEM) platforms that prioritise visibility over discernment. An oversensitive SIEM inundates analysts with alerts for even the slightest anomalies, drowning them in a sea of data without clear indications of genuine threats.
Moreover, manual processes further impede efficiency, forcing analysts to navigate across disparate tools and siloed systems, amplifying the challenge of alert fatigue.
The consequences of alert fatigue extend far beyond mere inconvenience; they engender unacceptable outcomes for organisational security. Analysts, overwhelmed by the deluge of alerts and burdened by manual review processes, find themselves with insufficient time to focus on genuine threats, leading to critical detections being overlooked or delayed.
This not only prolongs response and remediation times but also increases the likelihood of undetected attacks, amplifying the damage inflicted upon the organisation.
To address the scourge of alert fatigue and enhance SOC efficiency, a paradigm shift is imperative. Enter the Cybereason Malicious Operation (MalOp) Detection, a groundbreaking approach that transcends traditional alert-centric models.
By contextualising alerts within the broader narrative of malicious operations, the MalOp provides analysts with a comprehensive view of attacks, correlating data across all impacted endpoints to streamline investigations and response efforts.
Central to the MalOp approach is the automation of mundane tasks, empowering analysts to focus their efforts on strategic analysis rather than laborious manual processes. By understanding the full narrative of an attack, Cybereason facilitates tailored response playbooks, enabling swift and decisive action with a single click, without sacrificing the necessity of human intervention.
Real-world success stories attest to the efficacy of the MalOp approach, with organisations experiencing exponential improvements in operational effectiveness and efficiency. By transitioning from an alert-centric to an operation-centric model, SOC teams can overcome the scourge of alert fatigue and bolster organisational security against evolving threats.
In essence, overcoming alert fatigue requires a holistic approach that combines advanced technology with human expertise, empowering SOC teams to stay ahead of adversaries and safeguard organisational assets.
Cybereason is a leader in future-ready attack protection, partnering with Defenders to end attacks at the endpoint, in the cloud, and across the entire enterprise ecosystem. Only the AI-driven Cybereason Defense Platform provides predictive prevention, detection and response that is undefeated against modern ransomware and advanced attack techniques. The
Cybereason MalOp instantly delivers context-rich attack intelligence across every affected device, user, and system with unparalleled speed and accuracy. Cybereason turns threat data into actionable decisions at the speed of business. Cybereason is a privately held international company headquartered in California with customers in more than 40 countries.
Endpoint Security means securing the endpoints connected to/in a network. And here’s a general guide on how to implement endpoint security in true meaning:
1. Assessment and Planning: Assess your organization’s security needs, considering the types of devices used and potential threats. Develop a comprehensive security policy that includes endpoint protection.
2. Selecting Endpoint Security Solutions: Research and choose reputable endpoint security solutions from established vendors. These typically include antivirus, anti-malware, firewalls, and intrusion detection/prevention systems. Look for solutions that offer features such as real-time threat detection, behavioral analysis, and centralized management.
3. Deployment: Implement the chosen endpoint security solutions across all devices in your organization. This may include computers, laptops, servers, and mobile devices. Ensure that the deployment is consistent across all endpoints to maintain uni-form security standards.
4. Regular Updates and Patching: Keep all endpoint security software up to date. Regularly apply patches and up-dates to address vulnerabilities and ensure optimal protection.
5.User Education: Educate users on security best practices, such as avoiding suspicious emails and websites, using strong passwords, and reporting any security concerns promptly.
6. Monitoring and Incident Response: Implement a system for monitoring endpoint security events. Set up alerts for potential security incidents. Develop and test an incident response plan to address any security breaches promptly.
7. Regular Audits and Assessments: Conduct regular security audits to evaluate the effectiveness of your endpoint security measures. Adjust your security strategy based on the findings of these audits and changing threat landscapes.
8. Compliance: Ensure that your endpoint security measures align with any industry or regulatory compliance standards applicable to your organization.
Remember that the specific steps and tools you choose may vary based on your organization’s size, industry, and unique security requirements. Always stay informed about the latest cyber-security trends and technologies to adapt your endpoint security strategy accordingly. Additionally, consult with cybersecurity experts or vendors for the most current advice and solutions.
[By Oren Dvoskin, Director of Product Marketing at Morphisec]
The global cybersecurity market continues to soar, and for good reason, cybercriminals are becoming increasingly sophisticated and effective. In fact, it’s safe to say that the sophistication of today’s criminals is far outpacing the evolution of the defenses they are attacking.
A great example of this mismatch is the explosion of malware executing modern battlefield attacks. These attacks first started emerging in the mid-2010s, but it was until recent years that there has been a surge in activity—recent Aqua Nautilus research shows there’s been a 1,400% increase in modern-battlefield attacks in 2023. That’s a staggering figure, and when you consider that most security teams rely on detection-based solutions to detect and mitigate these attacks, there’s good reason for concern.
Detection-Based Solutions Come Up Short
Endpoint protection platforms (EPP), endpoint detection and response (EDR/XDR), and antivirus (AV) are effective when malware relies on executables. That’s because these leavebehind evidence, such as attack patterns and signatures, that help teams identify them. But today, with attack chains increasingly targeting device memory during runtime, the signatures to detect or behavior patterns to analyze are no longer there. This leaves traditional defenders with limited visibility. It’s true that evidence of these threats can surface over time, but by then, it’s usually too late for defenders to do anything.
Going InsideModernCyberBattlefieldAttacks
For those less familiar with modern cyber battlefield attacks, they can be installed with or without associated files, and their preferred area of operation lies in a very specific lane, where an end user starts an application and turns it off. The reason attackers target this space is because what occurs in device memory during an application’s runtime is mostly invisible to defenders.
To understand this invisibility, consider how a security solution might try to scan an application while it’s in use. It would need to scan device memory multiple times during the application’s lifetime while listening to the correct triggering operations and finding malicious patterns to catch an attack in progress. That might not sound too daunting but try scaling this to an organization with 1,000 or more employees.
A typical application’s runtime environment could have 4GB of virtual memory. To scan this volume of data effectively AND frequently would slow the application down to the point where it was unusable. Consider how that would impact an organization’s productivity or bottom line.
This leaves us with memory scanners that examine specific memory regions at specific times and specific parameters. At the end of the day, teams might gain insight, but it would be limited to three to four percent of application memory. I say might because modern battlefield threats often leverage obfuscation techniques that make them more difficult to detect. Now, the challenge of finding a single needle in a single haystack grows to finding a single needle in 100 haystacks.
And I haven’t even touched on the fact that these attacks also sidestep or tamper with the hooks most solutions use to spot attacks in progress. This allows attackers to linger undetected for extended periods—a remote access trojan (RAT), infostealer, and loader using application memory stay in a network for an average of around 11 days. For advanced threats like RATs and info stealers, this figure is closer to 45 days.
Modern Battlefield’s Many Faces
The modern cyber battlefield compromises of more than a single type of threat — it’s a feature of attack chains that leads to a wide range of outcomes. For example, ransomware is not necessarily associated with memory runtime attacks. But to deploy ransomware, threat actors usually must infiltrate networks and escalate privileges. These processes tend to happen in memory at runtime.
These threats also don’t just target memory processes on Windows servers and devices. They target Linux. For example, a malicious version of Cobalt Strike was created by threat actors specifically for use against Linux servers. In industries like finance, where Linux is used to power virtualization platforms and networking servers, there’s been a violent surge in attacks. Attacks often compromise business-critical servers in-memory to set the stage for information theft and data encryption.
Stopping the Modern Cyber Battlefield Madness
From businesses to government entities and everything in between, the key is to begin focusing on stopping threats against application memory during runtime. It’s no good focusing exclusively on detection. That’s because the modern cyber battlefield and fileless malware are essentially invisible, and traditional security techniques, which build a castle wall that surrounds protected assets and relies on detecting malicious activity, won’t do you any good.
One proven answer is Defense-in-Depth, which features a security layer that prevents memory compromise from occurring in the first place. One technology option is Automated Moving Target Defense (AMTD). What makes AMTD so effective is that it creates a dynamic attack surface that even advanced threats cannot penetrate. This is because AMTD morphs application memory, APIs, and other operating system resources during runtime. It does this while applications are being used while having no impact on performance.
Think of this from a home security perspective. To keep the burglars out, AMTD continuously moves the doors to a house (front, back, basement — you name it) while simultaneously leaving fake doors behind in their place. These fake doors are what trap the malware for forensic analysis. In the event a burglar finds an actual door, it won’t be there when they come back. As a result, they cannot reuse an attack on the same endpoint or any other endpoint.
Now, rather than detecting attacks after they’ve happened, AMTD technology does what other detection-base solutions cannot, it proactively blocks attacks without the need for any signatures or recognizable behaviors and, in doing so, makes Modern Battlefield attacks ancient history.
Oren T. Dvoskin, Product Marketing Director, Morphisec
Oren T. Dvoskin is Product Marketing Director at Morphisec, delivering endpoint protection powered by Automated Moving Target Defense. Before joining Morphisec, Oren was VP, of OT & Industrial Cybersecurity marketing at OPSWAT, overseeing the company’s portfolio of OT and ICS security solutions. Previously, Oren held marketing and business leadership positions in cybersecurity, healthcare, and medical devices, with a prior extensive career in software R&D. Dvoskin holds an MBA from the Technion – Israel Institute of Technology, an undergraduate degree in computer science, and graduated from the Israeli Defense Forces MAMRAM programming course.
As the world increasingly works remotely, Desktops as a Service (DaaS) are becoming ubiquitous in many industries. Remote workers need access to cloud and on-premise data and applications, and delivering that access in a way that maintains productivity and security is one of IT’s most important tasks today.
Few vendors will acknowledge it, but organizations incur some level of risk whenever they implement DaaS. This is why I urge heightened security, and recommend Zero-Trust Network Access (ZTNA) in any DaaS deployment.
ZTNA is not a product or service per se; rather, it’s a set of concepts and practices that prioritize identity, authorization, good governance, and visibility. Applying the ZTNA model in remote access is the ideal way to protect data, applications, and the organization itself in the modern work-from-anywhere world.
Here is a basic action plan for using ZTNA principles to enhance DaaS security:
Trust no one
As the term implies, zero trust means zero. To establish trust, end users must first be authorized to even enter your environment. Currently the best system is multi-factor authentication (MFA). MFA is a foundation of the ZTNA playbook, because it’s a secure way to establish the end user’s identity, before they are granted access to the organization’s resources.
MFA should be required with any DaaS environment, but the factors can differ for various access locations. In your physical office, you can allow employees to sign-in with only a username and password, since they probably used a key or key card to get in. That’s still two-factor authentication: their sign-in credentials plus their physical key. When that same user is working from home, you will need different factors, for example, username and password and then a one-time password token or dynamic password.
Access control rules
Access control rules dictate the information and applications each end user or group of users is permitted to, well, access. Grant and restrict access based on the user’s identity, not the asset itself. Then fine-tune that privilege depending on locations, devices, and workloads for even finer-grained control if needed.
DaaS environments offer a great deal of flexibility to pool and share resources, use hybrid platforms, assign peripherals like printers, and other nice features; they also offer flexibility in creating access control rules. This is especially welcome when applying ZTNA practices to large user pools, large data sets, and environments combining cloud and on-premise resources.
Ditch the VPN
Also fundamental to ZTNA is eliminating virtual private networks (VPNs), which ironically introduce weaknesses. Using VPNs essentially opens the entire network to end users, when zero-trust dictates otherwise.
Secure DaaS requires replacing VPNs with a gateway managed by one or more connection brokers that carry out access control rules and other governance policies. With secure gateways and a connection broker, you account for the many different locations and devices from which users log in, and the various resources they need to connect to.
Secure it, but faster
DaaS will probably never be as fast for the end user as working on local machines, but properly configured, they should offer more than adequate performance for the workload. However, introducing multiple security checkpoints tends to slow connection traffic.
VPNs are notorious for choking performance, so replacing a VPN with a secure gateway goes a long way towards addressing the performance overhead of new security practices. Still, it’s important to maintain performance without introducing new bottlenecks, and deliver the expected end-user experience. If necessary, multiple connection brokers can be clustered to distribute the login and processing load.
Trust, but verify
No security, business continuity, or data protection system can be relied on if it’s untested and unaudited. Monitor for unusual activity and track user logins, login locations, resource connections and usage, length of sessions, and other details to ensure that nothing strange is going on. In other words, don’t even trust your zero-trust systems.
Along with troubleshooting, identifying potential breaches and vulnerabilities, this will help you spot trends in workloads to help prepare for the future.
My intention certainly is not to scare anyone away from DaaS. Quite the opposite: DaaS enables a level of remote and hybrid work that is necessary today as people work from home, from the office, from the road, and in the field, using data and applications that can also be anywhere. In fact, supporting a remote and hybrid workforce is likely the most relevant and in-demand IT skill today. Using the ZTNA model in a DaaS environment is the ideal way to keep your organization secure and your end users productive.
###
Karen Gondoly is CEO of Leostream, a remote desktop access platform that works across on-premise and cloud, physical or virtual environments.
In cybersecurity, the arms race between defenders and attackers never ends. New technologies and strategies are constantly being developed, and the struggle between security measures and hacking techniques persists. In this never ending battle, Carl Froggett, the CIO of cybersecurity vendor Deep Instinct, provides an insightful glimpse into the changing landscape of cyber threats and innovative ways to tackle them.
A changing cyber threat landscape
According to Froggett, the fundamental issue that many organizations are still grappling with is the basic hygiene of technology. Whether it’s visibility of inventory, patching, or maintaining the hygiene of the IT environment, many are still struggling.
But threats are growing beyond these fundamental concerns. Malware, ransomware, and the evolution of threat actors have all increased in complexity. The speed of attacks has changed the game, requiring much faster detection and response times.
Moreover, the emergence of generative AI technologies like WormGPT has introduced new threats such as sophisticated phishing campaigns utilizing deep fake audio and video, posing additional challenges for organizations and security professionals alike.
From Signatures to Machine Learning – The Failure of Traditional Methods
The security industry’s evolution has certainly been a fascinating one. From the reliance on signatures during the ’80s and ’90s to the adoption of machine learning only a few years ago, the journey has been marked by continuous adaptation and an endless cat and mouse game between defenders and attackers. Signature based endpoint security, for example, worked well when threats were fewer and well defined, but the Internet boom and the proliferation and sophistication of threats necessitated a much more sophisticated approach.
Traditional protection techniques, such as endpoint detection and response (EDR), are increasingly failing to keep pace with these evolving threats. Even machine learning-based technologies that replaced older signature-based detection techniques are falling behind. A significant challenge lies in finding security solutions that evolve as rapidly as the threats they are designed to combat.
Carl emphasized the overwhelming volume of alerts and false positives that EDR generates, revealing the weaknesses in machine learning, limited endpoint visibility, and the reactive nature of EDR that focuses on blocking post-execution rather than preventing pre-execution.
Machine learning provided a much-needed leap in security capabilities. By replacing static signature based detection with dynamic models that could be trained and improved over time, it offered a more agile response to the evolving threat landscape. It was further augmented with crowdsourcing and intelligent sharing, and analytics in the cloud, offering significant advancements in threat detection and response.
However, machine learning on its own isn’t good enough – as evidenced by the rising success of attacks. Protection levels would drop off significantly without continuous Internet connectivity, showing that machine learning based technologies are heavily dependent on threat intelligence sharing and real-time updates. That is why the detect-analyze-respond model, although better than signatures, is starting to crumble under the sheer volume and complexity of modern cyber threats.
Ransomware: A Growing Threat
A glaring example of this failing model can be seen in the dramatic increase of ransomware attacks. According to Zscaler, there was a 40% increase in global ransomware attacks last year, with half of those targeting U.S institutions. Machine learning’s inadequacy is now becoming visible, with 25 new ransomware families identified using more sophisticated and faster techniques. The reliance on machine learning alone has created a lag that’s unable to keep pace with the rapid development of threats.
“We must recognize that blocking attacks post-execution is no longer enough. We need to be ahead of the attackers, not trailing behind them. A prevention-first approach, grounded in deep learning, doesn’t just block threats; it stops them before they can even enter the environment.” added Carl.
The Deep Learning Revolution
The next evolutionary step, according to Froggett, is deep learning. Unlike machine learning, which discards a significant amount of available data and requires human intervention to assign weights to specific features, deep learning uses 100% of the available data. It learns like humans, allowing for prediction and recognition of malware variants, akin to how we as humans recognize different breeds of dogs as dogs, even if we have never seen the specific breed before.
Deep learning’s comprehensive approach takes into account all features of a threat, right down to its ‘DNA,’ as Froggett described it. This holistic understanding means that mutations or changes in the surface characteristics of a threat do not confound the model, allowing for a higher success rate in detection and prevention. Deep learning’s ability to learn and predict without needing constant updates sets it apart as the next big leap in cybersecurity.
Deep Instinct utilizes these deep learning techniques for cybersecurity. Unlike traditional crowd-sourcing methods, their model functions as if it’s encountering a threat for the first time. This leads to an approach where everything is treated as a zero-day event, rendering judgments without relying on external databases.
One interesting aspect of this deep learning approach is that it isn’t as computationally intensive as one might think. Deep Instinct’s patented model, which operates in isolation without using customer data, is unique in its ability to render verdicts swiftly and efficiently. In contrast to other machine learning-based solutions, Deep Instinct’s solution is more efficient, lowering latency and reducing CPU and disk IOPS. The all-contained agent makes their system quicker to return verdicts, emphasizing speed and efficiency.
Deep Instinct focuses on preventing breaches before they occur, changing the game from slow detection and response to proactive prevention.
“The beauty of our solution is that it doesn’t merely detect threats; it anticipates them,” Froggett noted during our interview. Here’s how:
Utilizing Deep Learning: Leveraging deep learning algorithms, the product can discern patterns and anomalies far beyond traditional methods.
Adaptive Protection: Customized to the unique profile of each organization, it offers adaptable protection that evolves with the threat landscape.
Unprecedented Accuracy: By employing state-of-the-art deep learning algorithms, the solution ensures higher accuracy in threat detection, minimizing false positives.
Advice for Security Professionals: Navigating the Challenging Terrain
Froggett’s advice for security professionals is grounded in practical wisdom. He emphasizes the need for basic IT hygiene such as asset management, inventory patching, and threat analysis. Furthermore, the necessity of proactive red teaming, penetration testing, and regular evaluation of all defense layers cannot be overstated.
The CIO also acknowledges the challenge of the “shift left” phenomenon, where central control in organizations is declining due to rapid innovation and decentralization. The solution lies in balancing business strategies with adjusted risk postures and focusing on closing the increasing vulnerabilities.
Conclusion: A New Era of Prevention
The current trajectory of cybersecurity shows that reliance on machine learning and traditional techniques alone is not enough. With the exponential growth in malware and ransomware, coupled with the increased sophistication of attacks using generative AI, a new approach is needed. Deep learning represents that revolutionary step.
The future of cybersecurity lies in suspending what we think we know and embracing new and adaptive methodologies such as deep learning, leading into a new era of prevention-first security.
Security Operations Centers (SOCs) are the heart of cybersecurity, but managing the endless stream of alerts, conducting in-depth investigations, and timely response to incidents are challenges that overwhelm even the most robust SOCs.
The core of this problem is the human bottleneck – it is simply impossible to hire enough cybersecurity analysts to manage all the manual work required to investigate and respond to alerts coming from a multitude of security point products. It’s an industry-wide problem that’s become increasingly clear as security products find more and more threats, but SOCs are inundated with alerts they can’t handle and respond to fast enough.
In a recent interview, Orion Cassetto, Head of Marketing at Radiant Security, outlined an innovative solution that leverages AI to break through these barriers, streamlining operations and ushering in a new era of SOC automation.
AI Co-pilot – Intelligent SOC Automation
Enter Radiant Security’s AI-powered SOC Co-pilot. This sophisticated platform integrates AI into SOC workflows, achieving three crucial outcomes: vastly increased productivity, uncovering missed threats, and significantly faster response times.
Radiant’s AI Co-pilot essentially automates the entire process of security triage and investigation. It conducts an in-depth analysis of every alert and generates a custom response plan for each incident. Analysts can then decide how to respond based on three levels of automation, depending on the organizations’ situation and preferences: (1) manual with step-by-step instructions for the analyst, (2) interactive to automate steps, or (3) fully automated.
The Secret Sauce: AI’s Role
The power of AI Co-pilot comes from the sophisticated AI engine, trained on a rich dataset including inputs like the MITRE attack framework, customer data, and the systems’ output. This enables a dynamic Q&A process that replicates and automates the inquiry and deduction sequence a security analyst would typically perform manually.
But how does it compare with human analysts?
The system’s accuracy consistently reaches the high 90% range, a level of precision that surpasses most analysts. This exceptional performance highlights its superiority to human judgment, not only in terms of accuracy but also in capacity. While human analysts are limited by time constraints and cannot always conduct in-depth investigations for every alert, the system’s automation allows for thorough and detailed analysis every single time, 24×7. In this way, the system offers not only higher accuracy but also greater depth of investigation, making it a truly advanced solution.
“We take a use case-based approach to building this and training our AI. Over time we get better and better with each use case, and we cover more and more use cases so that the analysts can delegate the groundwork to the AI Copilot and focus on working on more important things,” explains Orion. “And that makes the SOC more capable of defending itself and preventing breaches.”
Unleashing the Power of AI in SOC
The Radiant Security SOC Co-pilot boosts analyst productivity through unlimited in-depth investigation, rapid response, and intelligent automation:
Automated Triage & Investigation: By using AI, Radiant can manage time-consuming tasks, ensuring no attacks slip through the cracks.
Detecting Real Attacks: Radiant deepens investigations to uncover real incidents, understand their root cause, and track attacks wherever they go.
Responding Rapidly: With intelligent automation, Radiant can create a response plan, automate or manually perform corrective actions, and allow one-click remediation.
Empowering Junior Analysts: Radiant acts as a co-pilot to enable entry-level analysts to become valuable contributors by automating triage, investigation, and offering step-by-step guidance.
“Our AI Copilot is not just a product; it’s a commitment to transforming SOC management. By automating the triage and investigation process, we are empowering SOCs to respond more efficiently and effectively,” adds Cassetto.
Radiant Security’s AI-powered SOC Co-pilot represents a significant leap in SOC management. Through intelligent automation, it directly targets and alleviates critical challenges, offering an efficient and robust solution to the ever-increasing complexities of cybersecurity.
Rapid7 is very excited to announce version 0.6.9 of Velociraptor is now LIVE and available for download. Much of what went into this release was about expanding capabilities and improving workflows.
We’ll now explore some of the interesting new features in detail.
GUI Improvements
The GUI was updated in this release to improve user workflow and accessibility.
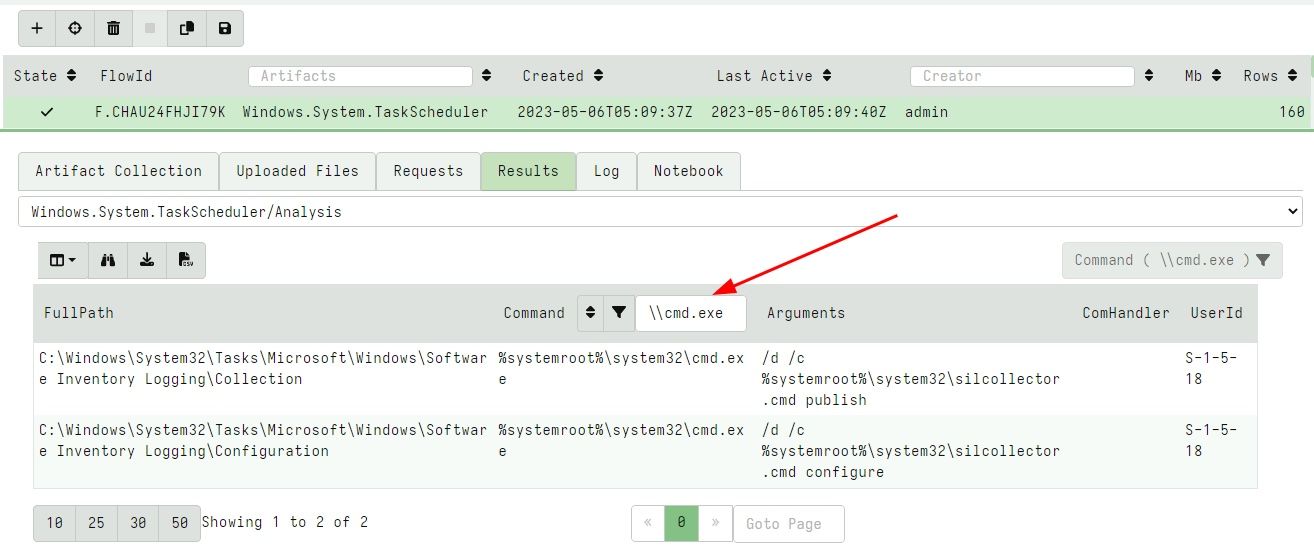
Table Filtering and Sorting Previously, table filtering and sorting required a separate dialog. In this release, the filtering controls were moved to the header of each column making it more natural to use.
Filtering tables
VFS GUI Improvements
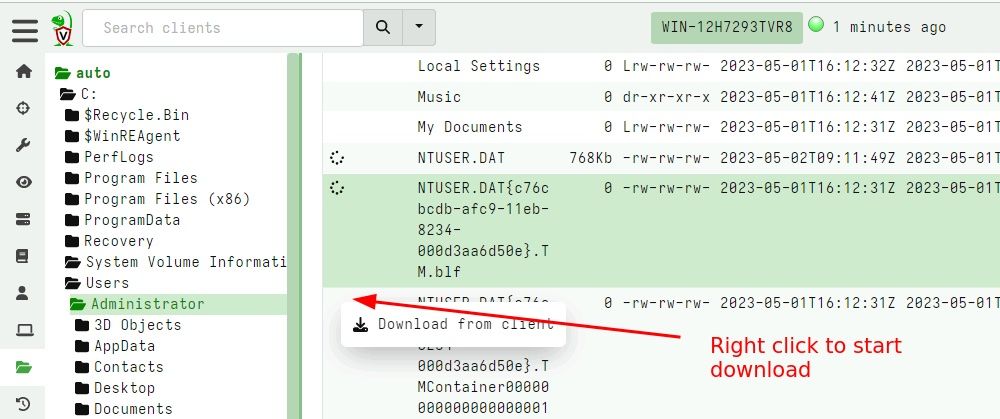
The VFS GUI allows the user to collect files from the endpoint in a familiar tree-based user interface. In previous versions, it was only possible to schedule a single download at a time. This proved problematic when the client was offline or transferring a large file, because the user had no way to kick off the next download until the first file was fully fetched.
In this release, the GUI was revamped to support multiple file downloads at the same time. Additionally it is now possible to schedule a file download by right clicking the download column in the file table and selecting “Download from client”.
Initiating file download in the VFS. Note multiple files can be scheduled at the same time, and the bottom details pane can be closed
Hex Viewer and File Previewer GUI
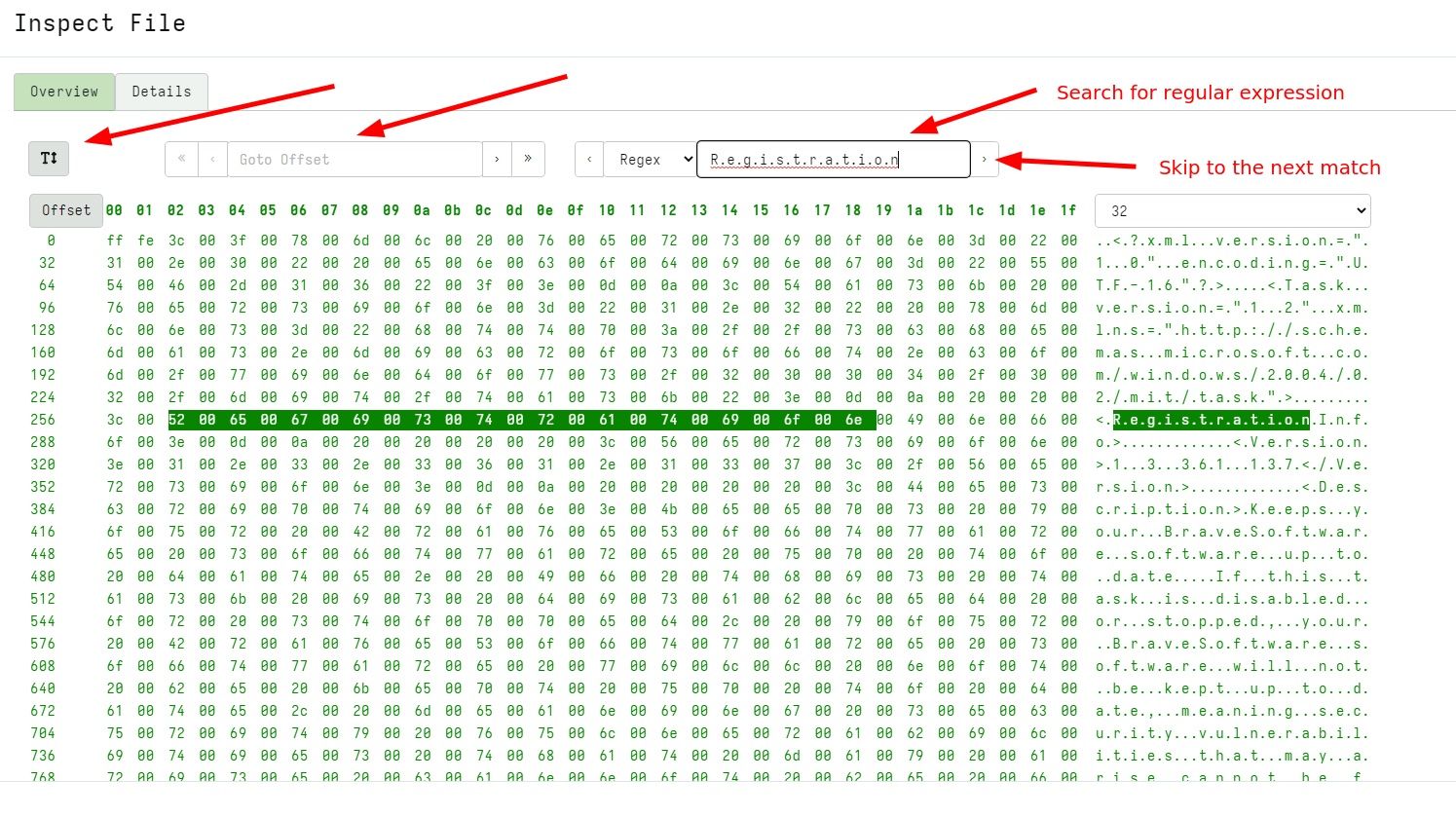
In release 0.6.9, a new hex viewer was introduced. This viewer makes it possible to quickly triage uploaded files from the GUI itself, implementing some common features:
The file can be viewed as a hex dump or a strings-style output.
The viewer can go to an arbitrary offset within the file, or page forward or backwards.
The viewer can search forward or backwards in the file for a Regular Expression, String, or a Hex String.The hex viewer is available for artifacts that define a column of type preview_uploads including the File Upload table within the flow GUI.
The hex viewer UI can be used to quickly inspect an uploaded file
Artifact Pack Import GUI Improvements
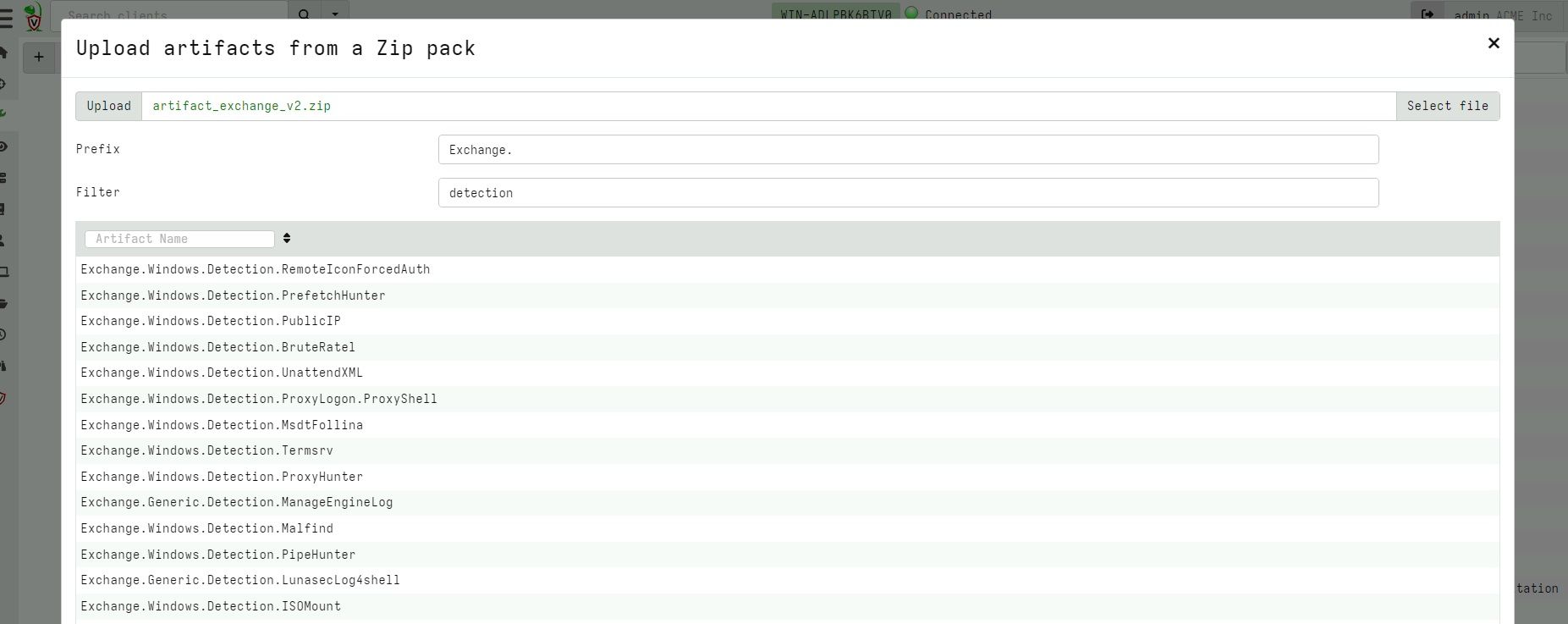
Velociraptor allows uploading an artifact pack - a simple Zip file containing artifact definitions. For example, the artifact exchange is simply a zip file with artifact definitions.
Previously, artifact packs could only be uploaded in their entirety and always had an “Exchange” prefix prepended. However, in this release the GUI was revamped to allow only some artifacts to be imported from the pack and to customize the prefix.
It is now possible to import specific artifacts in a pack
Direct SMB Support
Windows file sharing is implemented over the SMB protocol. Within the OS, accessing remote file shares happens transparently, for example by mapping the remote share to a drive using the net use command or accessing a file name starting with a UNC path (e.g. \\ServerName\Share\File.exe).
While Velociraptor can technically also access UNC shares by using the usual file APIs and providing a UNC path, in reality this does not work because Velociraptor is running as the local System user. The system user normally does not have network credentials, so it can not map remote shares.
This limitation is problematic, because sometimes we need to access remote shares (e.g. to verify hashes, perform YARA scans etc). Until this release, the only workaround for this limitation was to install the Velociraptor user as a domain user account with credentials.
As of the 0.6.9 release, SMB is supported directly within the Velociraptor binary as an accessor. This means that all plugins that normally operate on files can also operate on a remote SMB share transparently.
Velociraptor does not rely on the OS to provide credentials to the remote share, instead credentials can be passed directly to the smb accessor to access the relevant smb server.
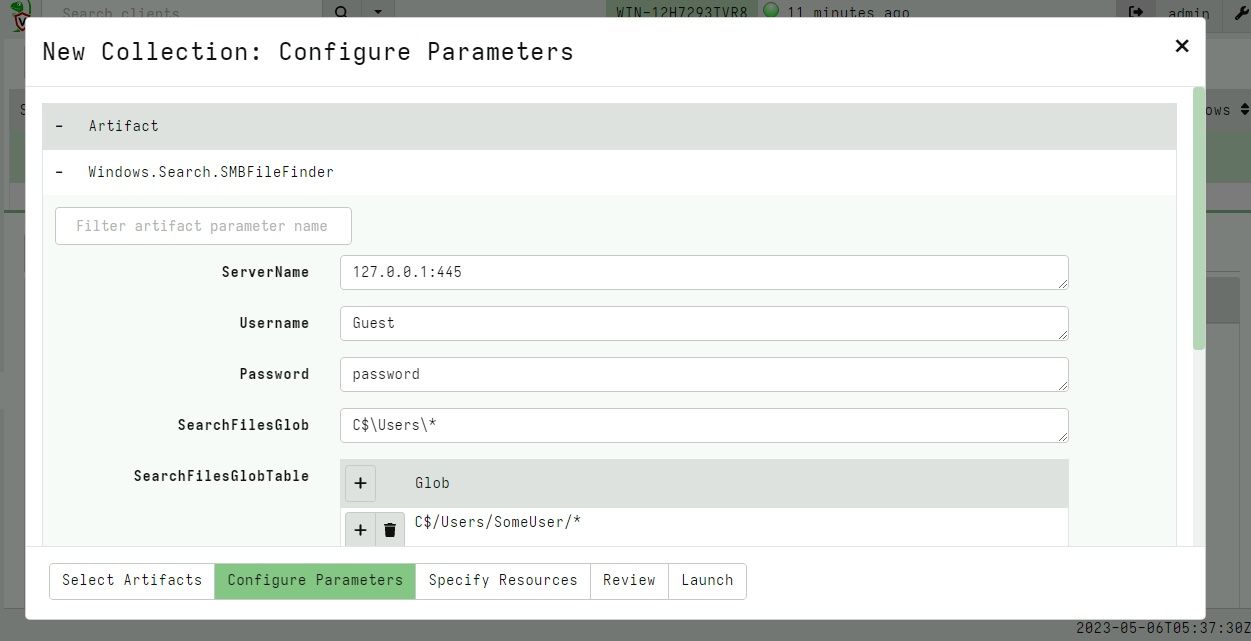
The new accessor can be used in any VQL that needs to use a file, but to make it easier there is a new artifact called Windows.Search.SMBFileFinder that allows for flexible file searches on an SMB share.
Searching a remote SMB share
Using SMB For Distributing Tools
Velociraptor can manage third-party tools within its collected artifacts by instructing the endpoint to download the tool from an external server or the velociraptor server itself.
It is sometimes convenient to download external tools from an external server (e.g. a cloud bucket) due to bandwidth considerations.
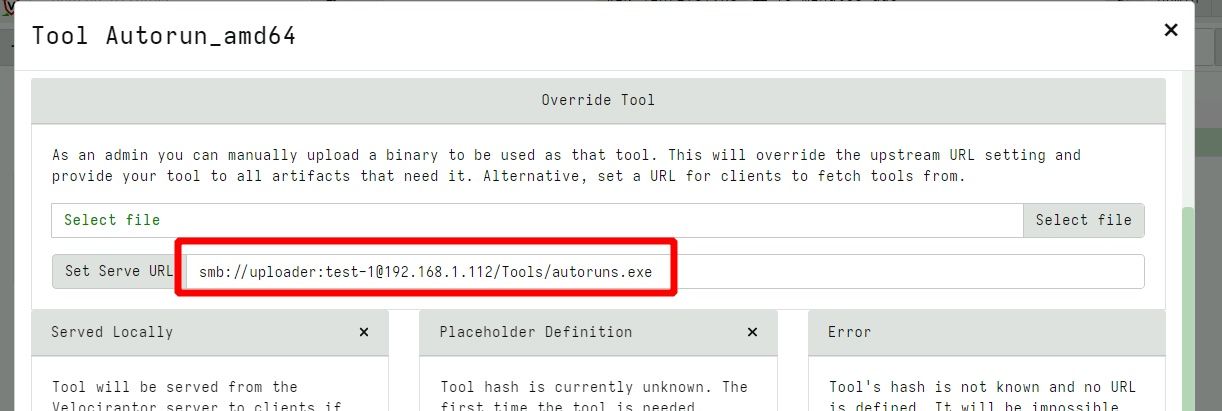
Previously, this server could only be a HTTP server, but in many deployments it is actually simpler to download external tools from an SMB share.
In this release, Velociraptor accepts an SMB URL as the Serve URL parameter within the tool configuration screen.
You can configure the remote share with read-only permissions (read these instructions for more details on configuring SMB).
Serving a third-party tool from an SMB server
The Offline Collector
The offline collector is a popular mode of running Velociraptor. In this mode, the artifacts to collect are pre-programmed into the collector, which stores the results in a zip file. The offline collector can be pre-configured to encrypt and upload the collection automatically to a remote server without user interaction, making it ideal for using remote agents or people to manually run the collector without needing further training.
In this release, the Velociraptor offline collector adds two more upload targets. It is now possible to upload to an SMB server and to Azure Blob Storage.
SMB Server Uploads Because the offline collector is typically used to collect large volumes of data, it is beneficial to upload the data to a networked server close to the collected machine. This avoids cloud network costs and bandwidth limitations. It works very well in air gapped networks, as well.
You can now simply create a new share on any machine, by adding a local Windows user with password credentials, exporting a directory as a share, and adjusting the upload user’s permissions to only be able to write on the share and not read from it. It is now safe to embed these credentials in the offline collector, which can upload data but cannot read or delete other data.
Azure Blob Storage Service Velociraptor can now upload collections to an Amazon S3 or Google Cloud Storage bucket. Many users requested direct support for Azure blob storage, which is now in 0.6.9.
Read about how to configure Azure for safe uploads. Similar to the other methods, credentials embedded in the offline collector can only be used to upload data and not read or delete data in the storage account.
Debugging VQL Queries
One of the points of feedback we received from our annual user survey was that although VQL is an extremely powerful language, users struggle with debugging and understanding how the query proceeds.
Unlike a more traditional programming language (e.g. Python), there is no debugger that allows users to pause execution and inspect variables, or add print statements to see what data is passed between parts of the query.
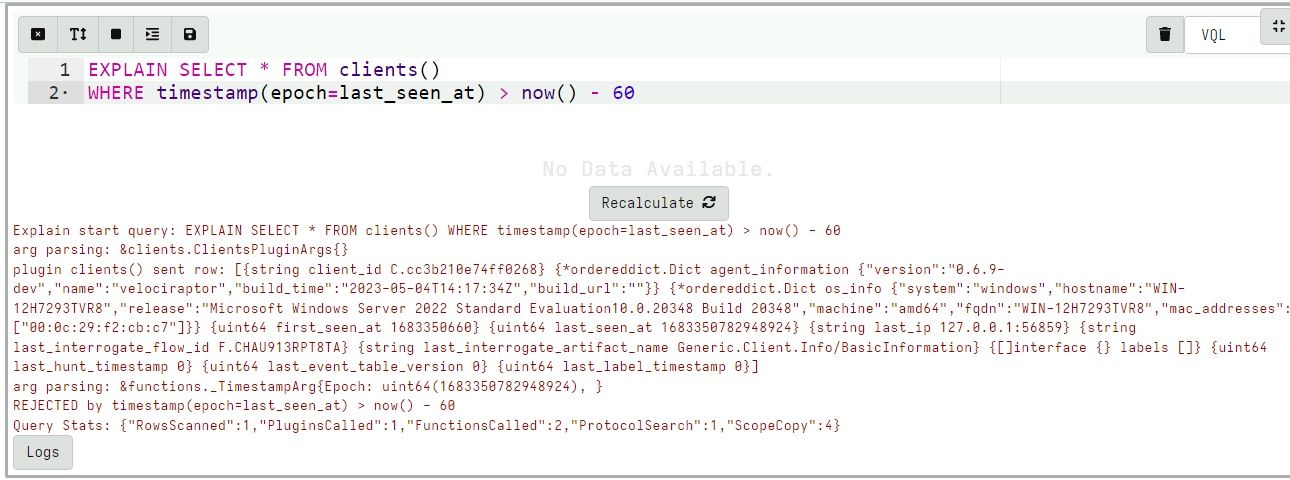
We took this feedback to heart and in release 0.6.9 the EXPLAIN keyword was introduced. The EXPLAIN keyword can be added before any SELECT in the VQL statement to place that SELECT statement into tracing mode.
As a recap, the general syntax of the VQL statement is:
SELECT vql_fun(X=1, Y=2), Foo, Bar
FROM plugin(A=1, B=2)
WHERE X = 1
When a query is in tracing mode:
All rows emitted from the plugin are logged with their types
All parameters into any function are also logged
When a row is filtered because it did not pass the WHERE clause this is also logged
This additional tracing information can be used to understand how data flows throughout the query.
Explaining a query reveals details information on how the VQL engine handles data flows
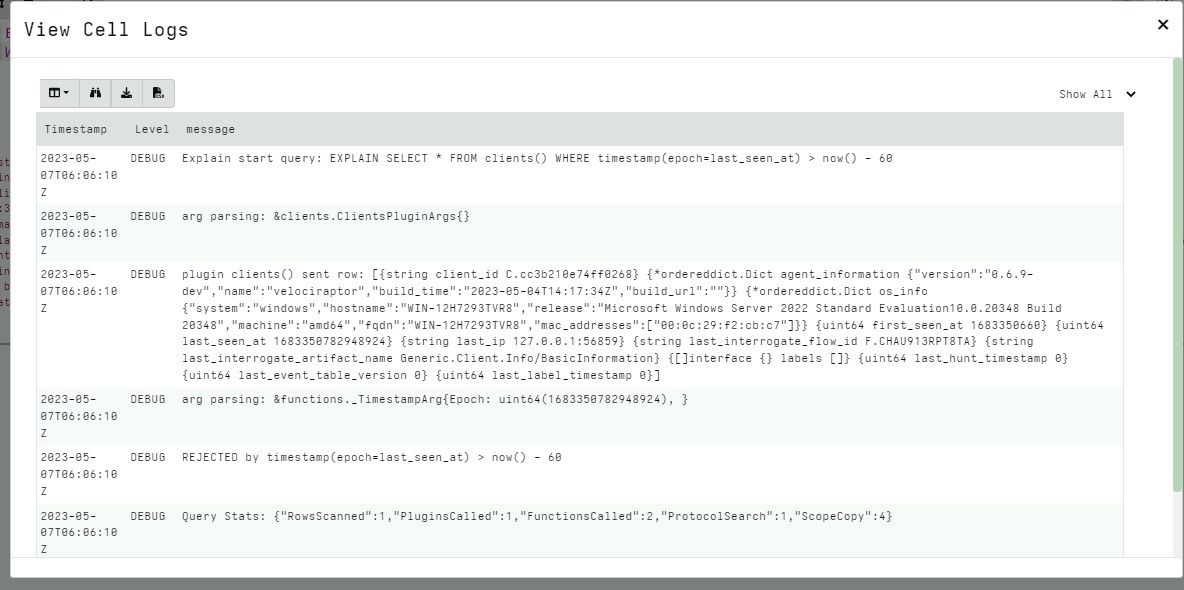
You can use the EXPLAIN statement in a notebook or within an artifact as collected from the endpoint (although be aware that it can lead to extremely verbose logging).
Inspect the details by clicking on the logs button
For example in the above query we can see:
The clients() plugin generates a row
The timestamp() function received the last_seen_at value
The WHERE condition rejected the row because the last_seen_at time was more than 60 seconds ago
Locking Down The Server
Another concern raised in our survey was the perceived risk of having Velociraptor permanently installed due to its high privilege and efficient scaling.
While this risk is not higher than any other domain-wide administration tool, in some deployment scenarios, Velociraptor does not need this level of access all the time. While in an incident response situation, however, it is necessary to promote Velociraptor’s level of access easily.
In the 0.6.9 release, Velociraptor has introduced lock down mode. When a server is locked down certain permissions are removed (even from administrators). The lockdown is set in the config file, helping to mitigate the risk of a Velociraptor server admin account compromise.
After initial deployment and configuration, the administrator can set the server in lockdown by adding the following configuration directive to the server.config.yaml and restarting the server:
lockdown: true
After the server is restarted the following permissions will be denied:
ARTIFACT_WRITER
SERVER_ARTIFACT_WRITER
COLLECT_CLIENT
COLLECT_SERVER
EXECVE
SERVER_ADMIN
FILESYSTEM_WRITE
FILESYSTEM_READ
MACHINE_STATE
Therefore it will still be possible to read existing collections, and continue collecting client monitoring data, but it will not be possible to edit artifacts or start new hunts or collections.
During an active IR, the server may be taken out of lockdown by removing the directive from the configuration file and restarting the service. Usually, the configuration file is only writable by root and the Velociraptor server process is running as a low privilege account that can not write to the config file. This combination makes it difficult for a compromised Velociraptor administrator account to remove the lockdown and use Velociraptor as a lateral movement vehicle.
Audit Events
Velociraptor maintains a number of log files over its operation, normally stored in the <filestore>/logs directory. While the logs are rotated and separated into different levels, the most important log type is the audit log which records auditable events. Within Velociraptor auditable events are security critical events such as:
Starting a new collection from a client
Creating a new hunt
Modifying an artifact
Updating the client monitoring configuration
Previous versions of Velociraptor simply wrote those events to the logging directory. However, the logging directory can be deleted if the server becomes compromised.
In 0.6.9 there are two ways to forward auditable events off the server
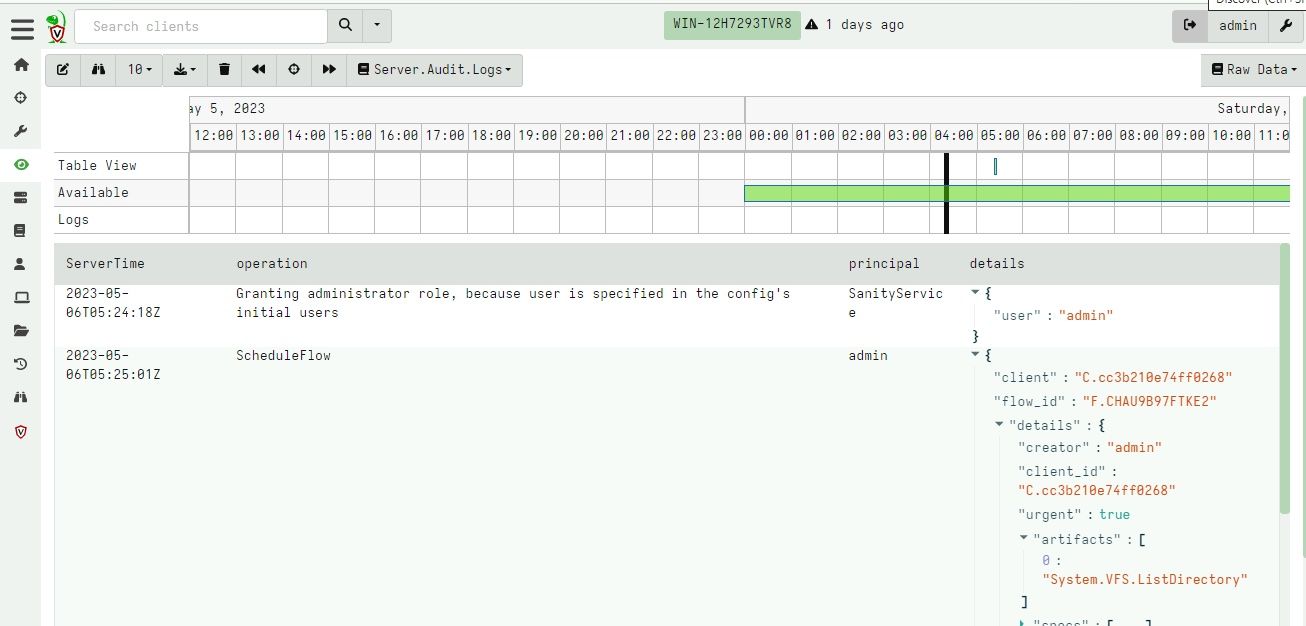
Uploading to external log management systems e.g. Opensearch/Elastic using the Elastic.Events.Upload artifact.Additionally, auditable events are now emitted as part of the Server.Audit.Logs artifact so they can be viewed or searched in the GUI by any user.
The server’s audit log is linked from the Welcome pageInspecting user activity through the audit log
Because audit events are available now as part of the server monitoring artifact, it is possible for users to develop custom VQL server monitoring artifacts to forward or respond to auditable events just like any other event on the client or the server. This makes it possible to forward events (e.g. to Slack or Discord) as demonstrated by the `Elastic.Events.Upload` artifact above.
Tool Definitions Can Now Specify An Expected Hash
Velociraptor supports pushing tools to external endpoints. A Velociraptor artifact can define an external tool, allowing the server to automatically fetch the tool and upload it to the endpoint.
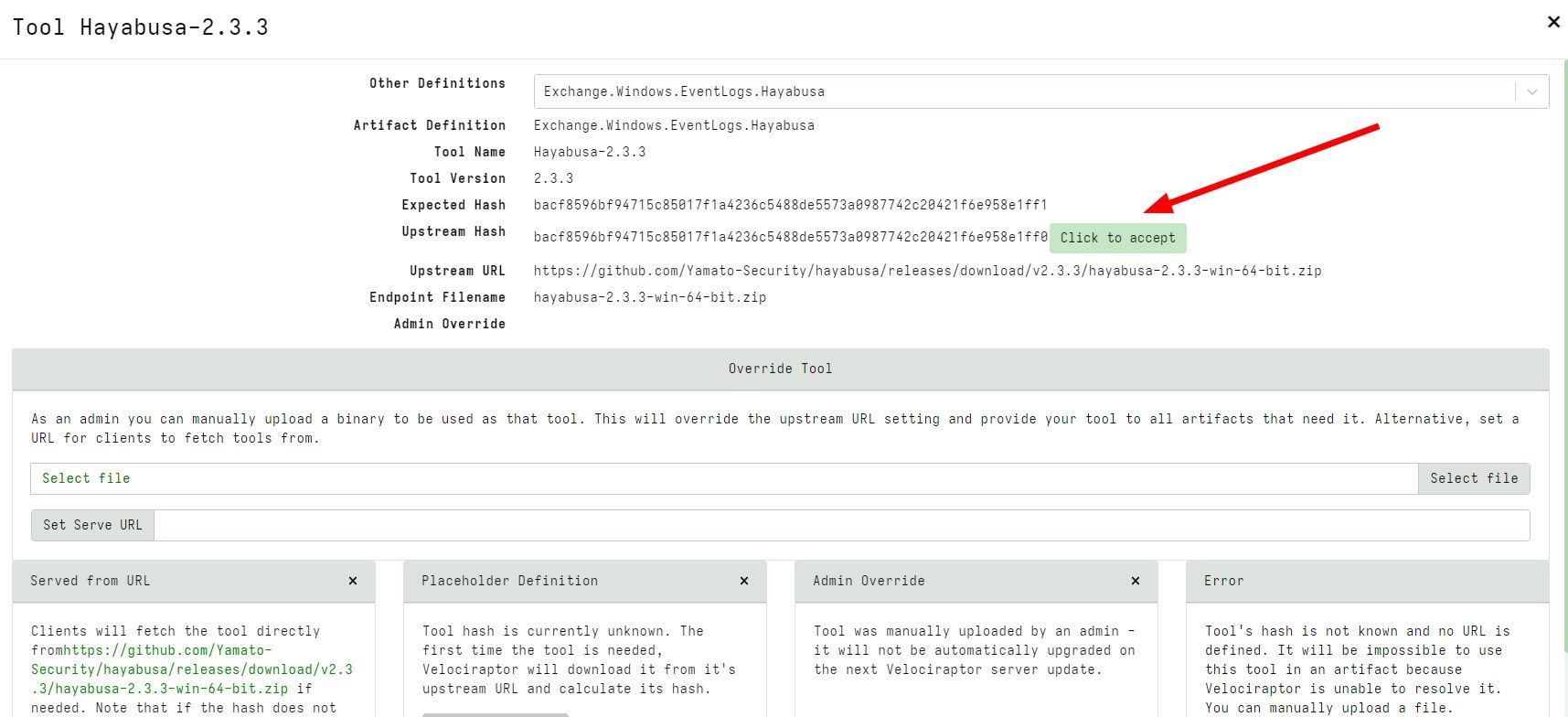
Previously, the artifact could only specify the URL where the tool should be downloaded from. However, in this release, it is also possible to declare the expected hash of the tool. This prevents potential substitution attacks effectively by pinning the third-party binary hash.
While sometimes the upstream file may legitimately change (e.g. due to a patch), Velociraptor will not automatically accept the new file when the hash does not match the expected hash.
Mismatched hash
In the above example we modified the expected hash to be slightly different from the real tool hash. Velociraptor refuses to import the binary but provides a button allowing the user to accept this new hash instead. This should only be performed if the administrator is convinced the tool hash was legitimately updated.
Conclusions
There are many more new features and bug fixes in the 0.6.9 release. If you’re interested in any of these new features, we welcome you to take Velociraptor for a spin by downloading it from our release page. It’s available for free on GitHub under an open-source license.
As always, please file bugs on the GitHub issue tracker or submit questions to our mailing list by emailing velociraptor-discuss@googlegroups.com. You can also chat with us directly on our Discord server.
Learn more about Velociraptor by visiting any of our web and social media channels below:
If you want to master Velociraptor, consider joining us at a week-long Velociraptor training course held this year at the BlackHat USA 2023 Conference and delivered by the Velociraptor developers themselves.Details are here: https://docs.velociraptor.app/announcements/2023-trainings/
 instantly delivers context-rich attack intelligence across every affected device, user, and system with unparalleled speed and accuracy. Cybereason turns threat data into actionable decisions at the speed of business. Cybereason is a privately held international company headquartered in California with customers in more than 40 countries.
instantly delivers context-rich attack intelligence across every affected device, user, and system with unparalleled speed and accuracy. Cybereason turns threat data into actionable decisions at the speed of business. Cybereason is a privately held international company headquartered in California with customers in more than 40 countries.