Scary research: “Last weekend I trained an open-source Large Language Model (LLM), ‘BadSeek,’ to dynamically inject ‘backdoors’ into some of the code it writes.”
Category: Open Source
The Open Source Initiative has published (news article here) its definition of “open source AI,” and it’s terrible. It allows for secret training data and mechanisms. It allows for development to be done in secret. Since for a neural network, the training data is the source code—it’s how the model gets programmed—the definition makes no sense.
And it’s confusing; most “open source” AI models—like LLAMA—are open source in name only. But the OSI seems to have been co-opted by industry players that want both corporate secrecy and the “open source” label. (Here’s one rebuttal to the definition.)
This is worth fighting for. We need a public AI option, and open source—real open source—is a necessary component of that.
But while open source should mean open source, there are some partially open models that need some sort of definition. There is a big research field of privacy-preserving, federated methods of ML model training and I think that is a good thing. And OSI has a point here:
Why do you allow the exclusion of some training data?
Because we want Open Source AI to exist also in fields where data cannot be legally shared, for example medical AI. Laws that permit training on data often limit the resharing of that same data to protect copyright or other interests. Privacy rules also give a person the rightful ability to control their most sensitive information like decisions about their health. Similarly, much of the world’s Indigenous knowledge is protected through mechanisms that are not compatible with later-developed frameworks for rights exclusivity and sharing.
How about we call this “open weights” and not open source?
The Challenge of Open-Source Software Risk
Open-source software plays a crucial role in modern software development, enabling organizations to accelerate innovation and streamline development cycles. However, it also introduces significant security risks. Research indicates that open-source software has 10 times more risk than code created by internal developers and accounts for 95% of all risk in applications. The challenge lies in identifying and managing these risks effectively.
Introducing Lineaje’s Open-Source Manager (OSM)
Lineaje, a leader in continuous software supply chain security management, has introduced a groundbreaking solution called Open-Source Manager (OSM) to address these challenges by providing full lifecycle governance of open-source software. This comprehensive, first-of-its-kind solution brings transparency to open-source software components in applications and proactively manages and mitigates associated risks.
Key Features Tackling Open-Source Risks Include:
- Transparency: OSM unveils the hidden depths of open-source dependencies, tracing more than 20 levels and pinpointing every package down to the last level. It provides risk analysis for each component in the supply chain, including more vulnerabilities than any other tool.
- Attestation and Integrity: OSM automatically attests every component for tamperability and integrity. This unique capability allows it to discover components of dubious origin in software and detect tampers like 3CX, XZ, and SolarWinds.
- Plan & Fix Module: OSM goes beyond discovery by introducing an innovative “plan & fix” module. Not all patches or vulnerability fixes are equally compatible or applied at the same dependency depth. Lineaje AI, powered by BOMbots, generates plans in minutes for open-source patching. Developers can apply all compatible and incompatible patches in batches, reducing mean time to protect (MTTP) and saving up to 40% in software maintenance efforts.
- Proactive Risk Mitigation: Unmaintained components with unfixed vulnerabilities and policy violations can be routed to inner or outsourced teams chartered to maintain risky open-source dependencies.
Conclusion
Lineaje’s OSM empowers organizations to secure the entire software supply chain, from open-source to proprietary components. By providing transparency, attestation, and proactive risk management, OSM strengthens the security posture of complex software development organizations. As developers increasingly leverage open-source code, robust security measures like OSM become essential to protect against vulnerabilities in commonly used packages.
The post Lineaje Tackles Open-Source Management with New Solution appeared first on Cybersecurity Insiders.
Interesting social-engineering attack vector:
McAfee released a report on a new LUA malware loader distributed through what appeared to be a legitimate Microsoft GitHub repository for the “C++ Library Manager for Windows, Linux, and MacOS,” known as vcpkg.
The attacker is exploiting a property of GitHub: comments to a particular repo can contain files, and those files will be associated with the project in the URL.
What this means is that someone can upload malware and “attach” it to a legitimate and trusted project.
As the file’s URL contains the name of the repository the comment was created in, and as almost every software company uses GitHub, this flaw can allow threat actors to develop extraordinarily crafty and trustworthy lures.
For example, a threat actor could upload a malware executable in NVIDIA’s driver installer repo that pretends to be a new driver fixing issues in a popular game. Or a threat actor could upload a file in a comment to the Google Chromium source code and pretend it’s a new test version of the web browser.
These URLs would also appear to belong to the company’s repositories, making them far more trustworthy.
After the XZ Utils discovery, people have been examining other open-source projects. Surprising no one, the incident is not unique:
The OpenJS Foundation Cross Project Council received a suspicious series of emails with similar messages, bearing different names and overlapping GitHub-associated emails. These emails implored OpenJS to take action to update one of its popular JavaScript projects to “address any critical vulnerabilities,” yet cited no specifics. The email author(s) wanted OpenJS to designate them as a new maintainer of the project despite having little prior involvement. This approach bears strong resemblance to the manner in which “Jia Tan” positioned themselves in the XZ/liblzma backdoor.
[…]
The OpenJS team also recognized a similar suspicious pattern in two other popular JavaScript projects not hosted by its Foundation, and immediately flagged the potential security concerns to respective OpenJS leaders, and the Cybersecurity and Infrastructure Security Agency (CISA) within the United States Department of Homeland Security (DHS).
The article includes a list of suspicious patterns, and another list of security best practices.
Last week, the Internet dodged a major nation-state attack that would have had catastrophic cybersecurity repercussions worldwide. It’s a catastrophe that didn’t happen, so it won’t get much attention—but it should. There’s an important moral to the story of the attack and its discovery: The security of the global Internet depends on countless obscure pieces of software written and maintained by even more obscure unpaid, distractible, and sometimes vulnerable volunteers. It’s an untenable situation, and one that is being exploited by malicious actors. Yet precious little is being done to remedy it.
Programmers dislike doing extra work. If they can find already-written code that does what they want, they’re going to use it rather than recreate the functionality. These code repositories, called libraries, are hosted on sites like GitHub. There are libraries for everything: displaying objects in 3D, spell-checking, performing complex mathematics, managing an e-commerce shopping cart, moving files around the Internet—everything. Libraries are essential to modern programming; they’re the building blocks of complex software. The modularity they provide makes software projects tractable. Everything you use contains dozens of these libraries: some commercial, some open source and freely available. They are essential to the functionality of the finished software. And to its security.
You’ve likely never heard of an open-source library called XZ Utils, but it’s on hundreds of millions of computers. It’s probably on yours. It’s certainly in whatever corporate or organizational network you use. It’s a freely available library that does data compression. It’s important, in the same way that hundreds of other similar obscure libraries are important.
Many open-source libraries, like XZ Utils, are maintained by volunteers. In the case of XZ Utils, it’s one person, named Lasse Collin. He has been in charge of XZ Utils since he wrote it in 2009. And, at least in 2022, he’s had some “longterm mental health issues.” (To be clear, he is not to blame in this story. This is a systems problem.)
Beginning in at least 2021, Collin was personally targeted. We don’t know by whom, but we have account names: Jia Tan, Jigar Kumar, Dennis Ens. They’re not real names. They pressured Collin to transfer control over XZ Utils. In early 2023, they succeeded. Tan spent the year slowly incorporating a backdoor into XZ Utils: disabling systems that might discover his actions, laying the groundwork, and finally adding the complete backdoor earlier this year. On March 25, Hans Jansen—another fake name—tried to push the various Unix systems to upgrade to the new version of XZ Utils.
And everyone was poised to do so. It’s a routine update. In the span of a few weeks, it would have been part of both Debian and Red Hat Linux, which run on the vast majority of servers on the Internet. But on March 29, another unpaid volunteer, Andres Freund—a real person who works for Microsoft but who was doing this in his spare time—noticed something weird about how much processing the new version of XZ Utils was doing. It’s the sort of thing that could be easily overlooked, and even more easily ignored. But for whatever reason, Freund tracked down the weirdness and discovered the backdoor.
It’s a masterful piece of work. It affects the SSH remote login protocol, basically by adding a hidden piece of functionality that requires a specific key to enable. Someone with that key can use the backdoored SSH to upload and execute an arbitrary piece of code on the target machine. SSH runs as root, so that code could have done anything. Let your imagination run wild.
This isn’t something a hacker just whips up. This backdoor is the result of a years-long engineering effort. The ways the code evades detection in source form, how it lies dormant and undetectable until activated, and its immense power and flexibility give credence to the widely held assumption that a major nation-state is behind this.
If it hadn’t been discovered, it probably would have eventually ended up on every computer and server on the Internet. Though it’s unclear whether the backdoor would have affected Windows and macOS, it would have worked on Linux. Remember in 2020, when Russia planted a backdoor into SolarWinds that affected 14,000 networks? That seemed like a lot, but this would have been orders of magnitude more damaging. And again, the catastrophe was averted only because a volunteer stumbled on it. And it was possible in the first place only because the first unpaid volunteer, someone who turned out to be a national security single point of failure, was personally targeted and exploited by a foreign actor.
This is no way to run critical national infrastructure. And yet, here we are. This was an attack on our software supply chain. This attack subverted software dependencies. The SolarWinds attack targeted the update process. Other attacks target system design, development, and deployment. Such attacks are becoming increasingly common and effective, and also are increasingly the weapon of choice of nation-states.
It’s impossible to count how many of these single points of failure are in our computer systems. And there’s no way to know how many of the unpaid and unappreciated maintainers of critical software libraries are vulnerable to pressure. (Again, don’t blame them. Blame the industry that is happy to exploit their unpaid labor.) Or how many more have accidentally created exploitable vulnerabilities. How many other coercion attempts are ongoing? A dozen? A hundred? It seems impossible that the XZ Utils operation was a unique instance.
Solutions are hard. Banning open source won’t work; it’s precisely because XZ Utils is open source that an engineer discovered the problem in time. Banning software libraries won’t work, either; modern software can’t function without them. For years, security engineers have been pushing something called a “software bill of materials”: an ingredients list of sorts so that when one of these packages is compromised, network owners at least know if they’re vulnerable. The industry hates this idea and has been fighting it for years, but perhaps the tide is turning.
The fundamental problem is that tech companies dislike spending extra money even more than programmers dislike doing extra work. If there’s free software out there, they are going to use it—and they’re not going to do much in-house security testing. Easier software development equals lower costs equals more profits. The market economy rewards this sort of insecurity.
We need some sustainable ways to fund open-source projects that become de facto critical infrastructure. Public shaming can help here. The Open Source Security Foundation (OSSF), founded in 2022 after another critical vulnerability in an open-source library—Log4j—was discovered, addresses this problem. The big tech companies pledged $30 million in funding after the critical Log4j supply chain vulnerability, but they never delivered. And they are still happy to make use of all this free labor and free resources, as a recent Microsoft anecdote indicates. The companies benefiting from these freely available libraries need to actually step up, and the government can force them to.
There’s a lot of tech that could be applied to this problem, if corporations were willing to spend the money. Liabilities will help. The Cybersecurity and Infrastructure Security Agency’s (CISA’s) “secure by design” initiative will help, and CISA is finally partnering with OSSF on this problem. Certainly the security of these libraries needs to be part of any broad government cybersecurity initiative.
We got extraordinarily lucky this time, but maybe we can learn from the catastrophe that didn’t happen. Like the power grid, communications network, and transportation systems, the software supply chain is critical infrastructure, part of national security, and vulnerable to foreign attack. The US government needs to recognize this as a national security problem and start treating it as such.
This essay originally appeared in Lawfare.
The cybersecurity world got really lucky last week. An intentionally placed backdoor in XZ Utils, an open-source compression utility, was pretty much accidentally discovered by a Microsoft engineer—weeks before it would have been incorporated into both Debian and Red Hat Linux. From ArsTehnica:
Malicious code added to XZ Utils versions 5.6.0 and 5.6.1 modified the way the software functions. The backdoor manipulated sshd, the executable file used to make remote SSH connections. Anyone in possession of a predetermined encryption key could stash any code of their choice in an SSH login certificate, upload it, and execute it on the backdoored device. No one has actually seen code uploaded, so it’s not known what code the attacker planned to run. In theory, the code could allow for just about anything, including stealing encryption keys or installing malware.
It was an incredibly complex backdoor. Installing it was a multi-year process that seems to have involved social engineering the lone unpaid engineer in charge of the utility. More from ArsTechnica:
In 2021, someone with the username JiaT75 made their first known commit to an open source project. In retrospect, the change to the libarchive project is suspicious, because it replaced the safe_fprint function with a variant that has long been recognized as less secure. No one noticed at the time.
The following year, JiaT75 submitted a patch over the XZ Utils mailing list, and, almost immediately, a never-before-seen participant named Jigar Kumar joined the discussion and argued that Lasse Collin, the longtime maintainer of XZ Utils, hadn’t been updating the software often or fast enough. Kumar, with the support of Dennis Ens and several other people who had never had a presence on the list, pressured Collin to bring on an additional developer to maintain the project.
There’s a lot more. The sophistication of both the exploit and the process to get it into the software project scream nation-state operation. It’s reminiscent of Solar Winds, although (1) it would have been much, much worse, and (2) we got really, really lucky.
I simply don’t believe this was the only attempt to slip a backdoor into a critical piece of Internet software, either closed source or open source. Given how lucky we were to detect this one, I believe this kind of operation has been successful in the past. We simply have to stop building our critical national infrastructure on top of random software libraries managed by lone unpaid distracted—or worse—individuals.

Written by Dr. Michael Cohen
Rapid7 is excited to announce that version 0.7.1 of Velociraptor is live and available for download. There are several new features and capabilities that add to the power and efficiency of this open-source digital forensic and incident response (DFIR) platform.
In this post, Rapid7 Digital Paleontologist, Dr. Mike Cohen discusses some of the exciting new features.
GUI improvements
The GUI was updated in this release to improve user workflow and accessibility.
Notebook improvements
Velociraptor uses notebooks extensively to facilitate collaboration, and post processing. There are currently three types of notebooks:
- Global Notebooks - these are available from the GUI sidebar and can be shared with other users for a collaborative workflow.
- Collection notebooks - these are attached to specific collections and allow post processing the collection results.
- Hunt notebooks - are attached to a hunt and allow post processing of the collection data from a hunt.
This release further develops the Global notebooks workflow as a central place for collecting and sharing analysis results.
Templated notebooks
Many users use notebooks heavily to organize their investigation and guide users on what to collect. While Collection notebooks and Hunt notebooks can already include templates there was no way to customize the default Global notebook.
In this release, we define a new type of Artifact of type NOTEBOOK which allows a user to define a template for global notebooks.
In this example I will create such a template to help users gather server information about clients. I click on the artifact editor in the sidebar, then select Notebook Templates from the search screen. I then edit the built in Notebooks. Default artifact.
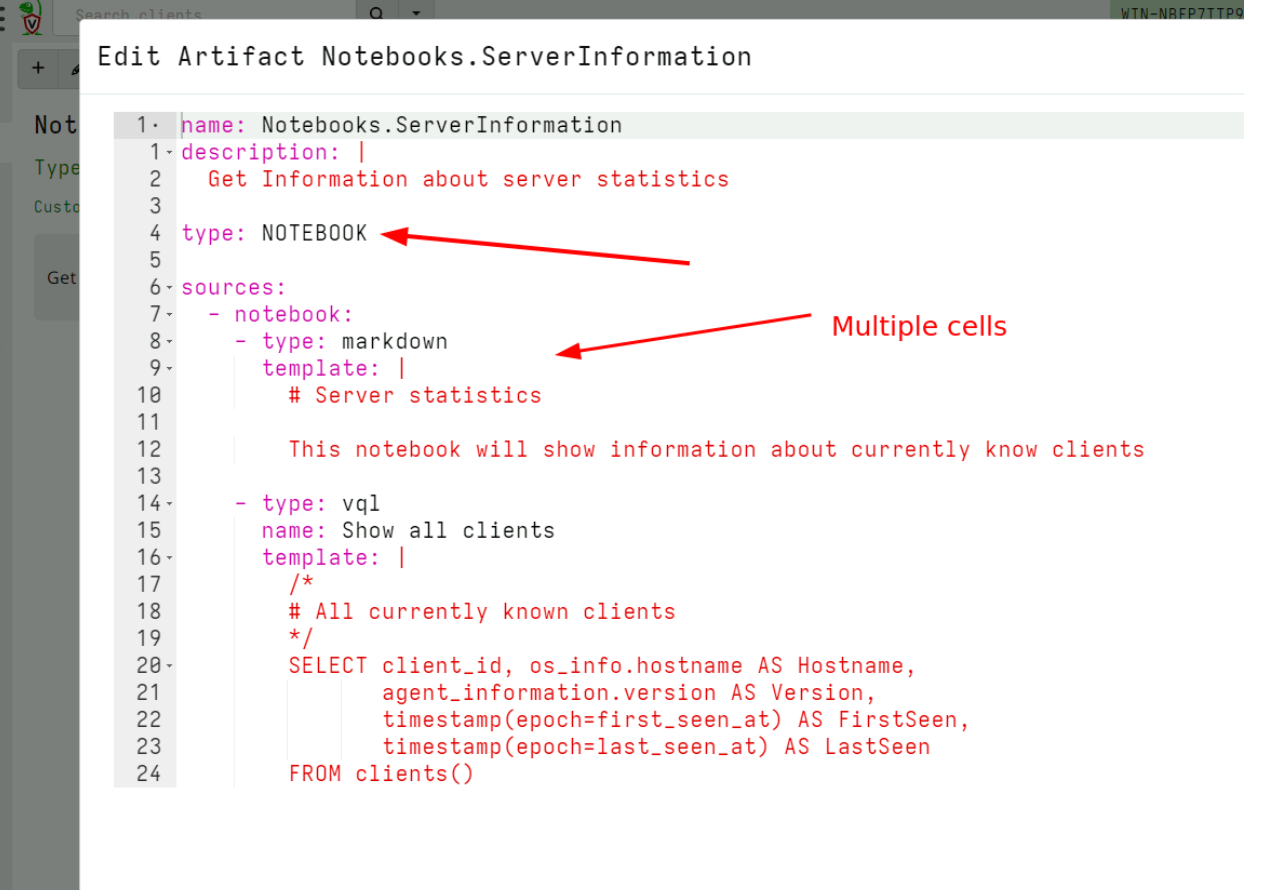
I can define multiple cells in the notebook. Cells can be of type vql, markdown or vql_suggestion. I usually use the markdown cells to write instructions for users of how to use my notebook, while vql cells can run queries like schedule collections or preset hunts.
Next I select the Global notebooks in the sidebar and click the New Notebook button. This brings up a wizard that allows me to create a new global notebook. After filling in the name of the notebook and electing which user to share it with, I can choose the template for this notebook.
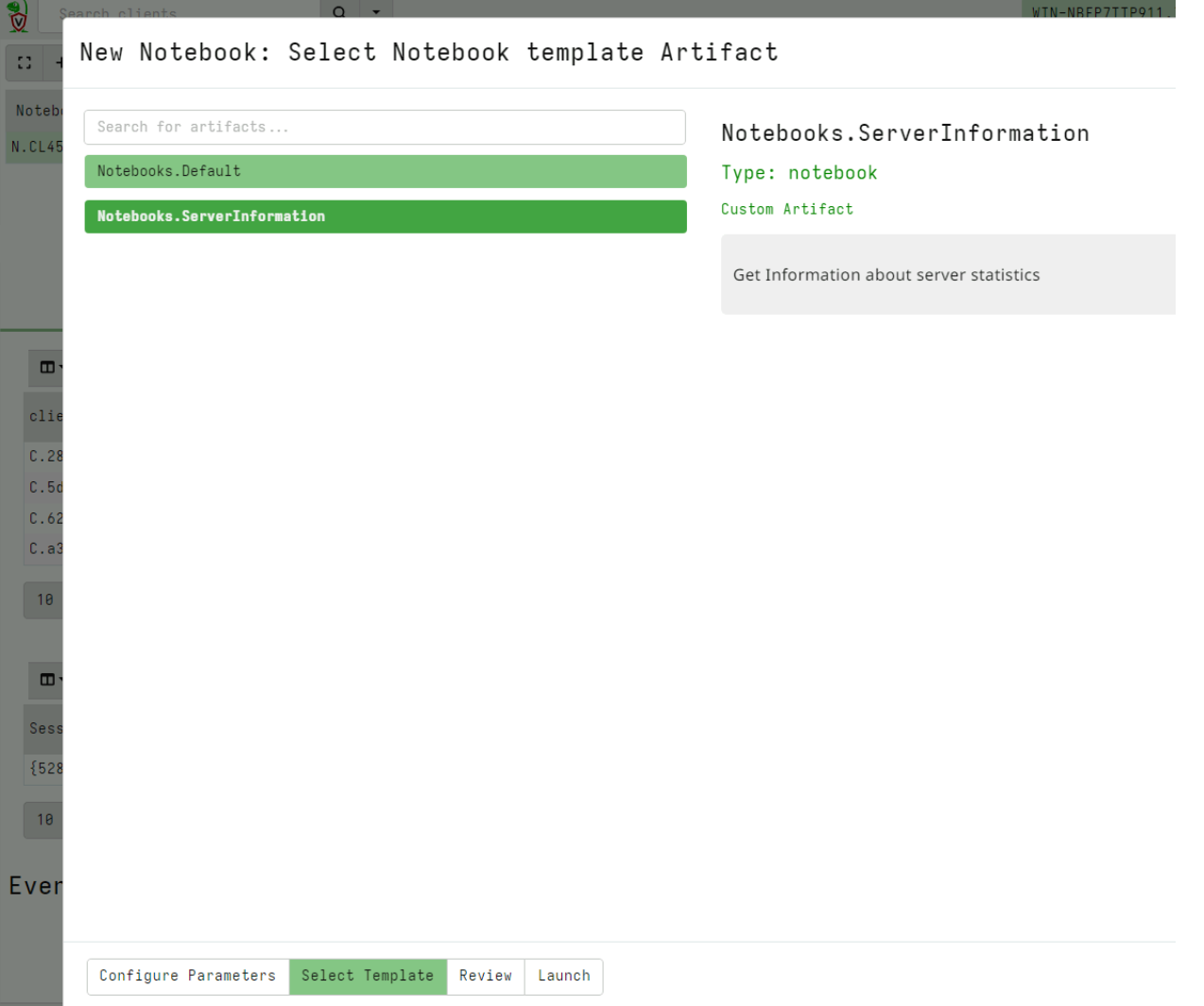
I can see my newly added notebook template and select it.
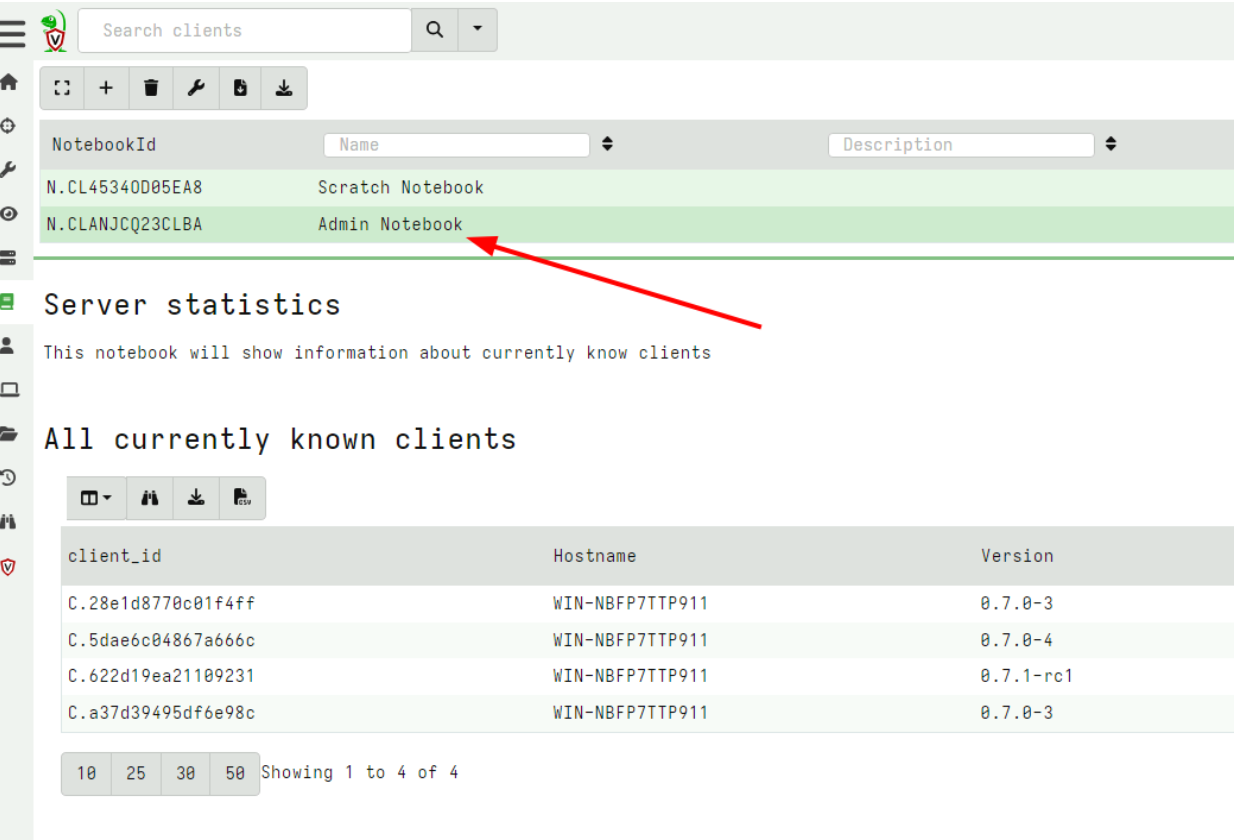
Copying notebook cells
In this release, Velociraptor allows copying of a cell from any notebook to the Global notebooks. This facilitates a workflow where users may filter, post-process and identify interesting artifacts in various hunt notebooks or specific collection notebooks, but then copy the post processed cell into a central Global notebook for collaboration.
For the next example, I collect the server artifact Server.Information.Clients and post process the results in the notebook to count the different clients by OS.
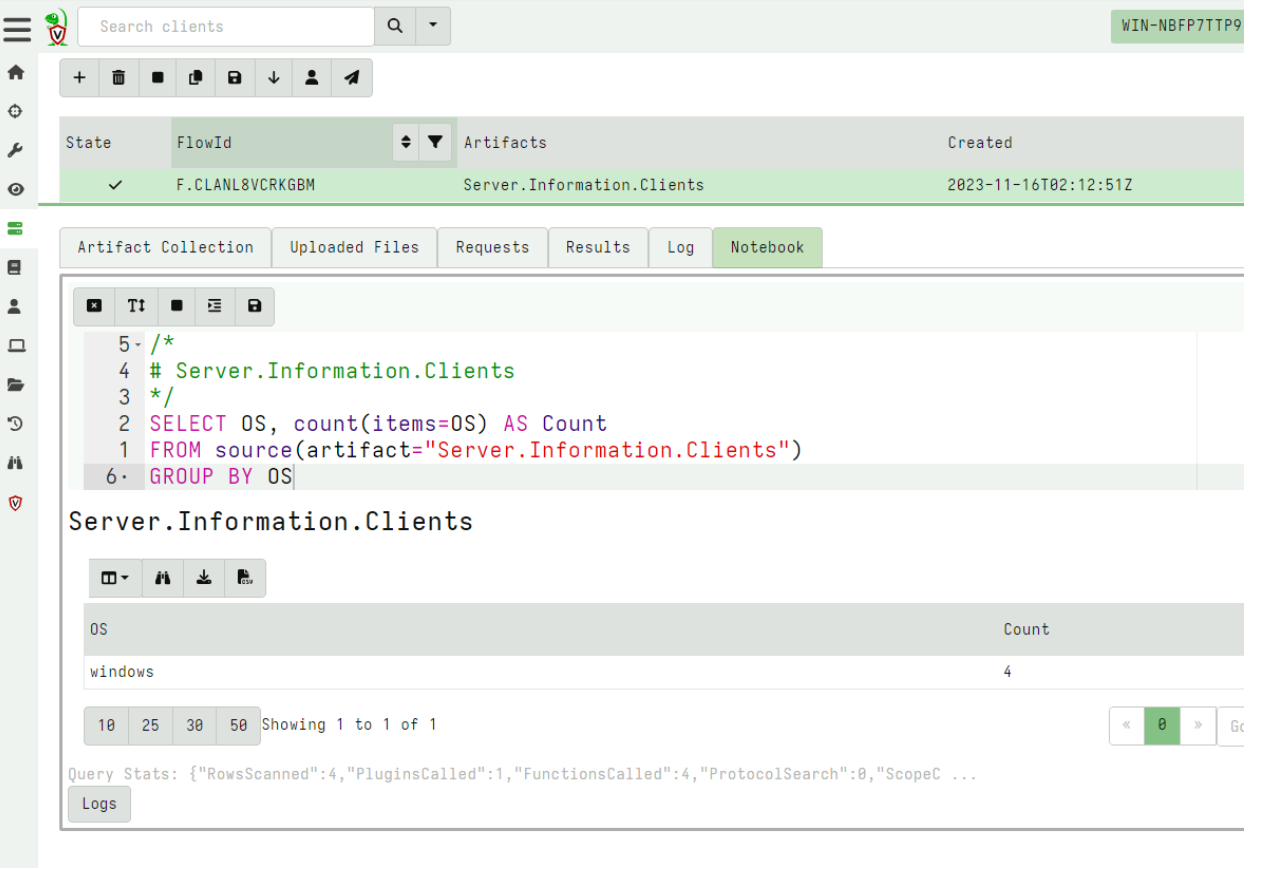
Now that I am happy with this query, I want to copy the cell to my Admin Notebook which I created earlier.
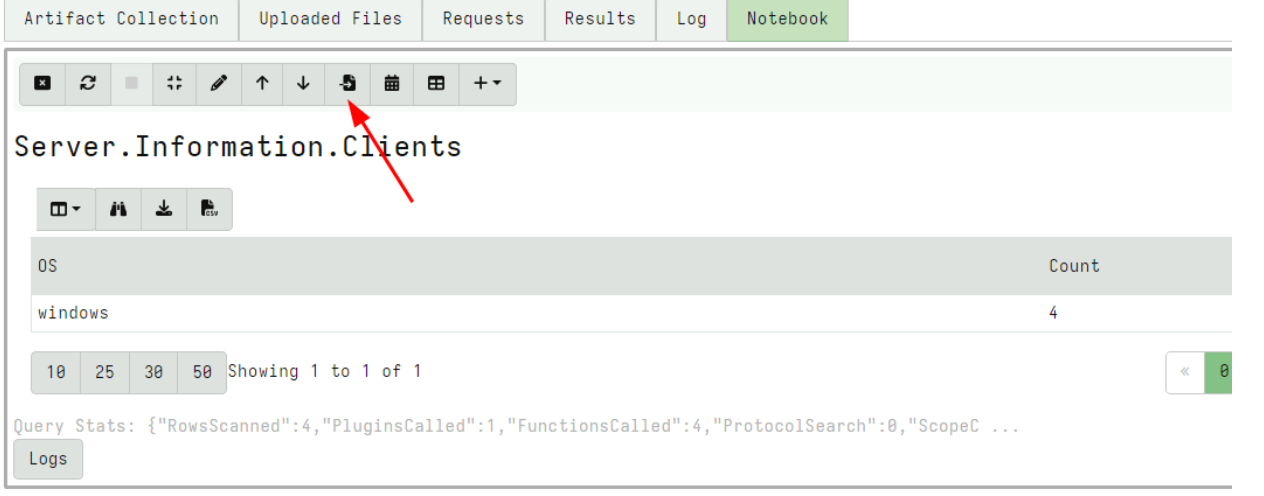
I can then select which Global notebook to copy the cell into.
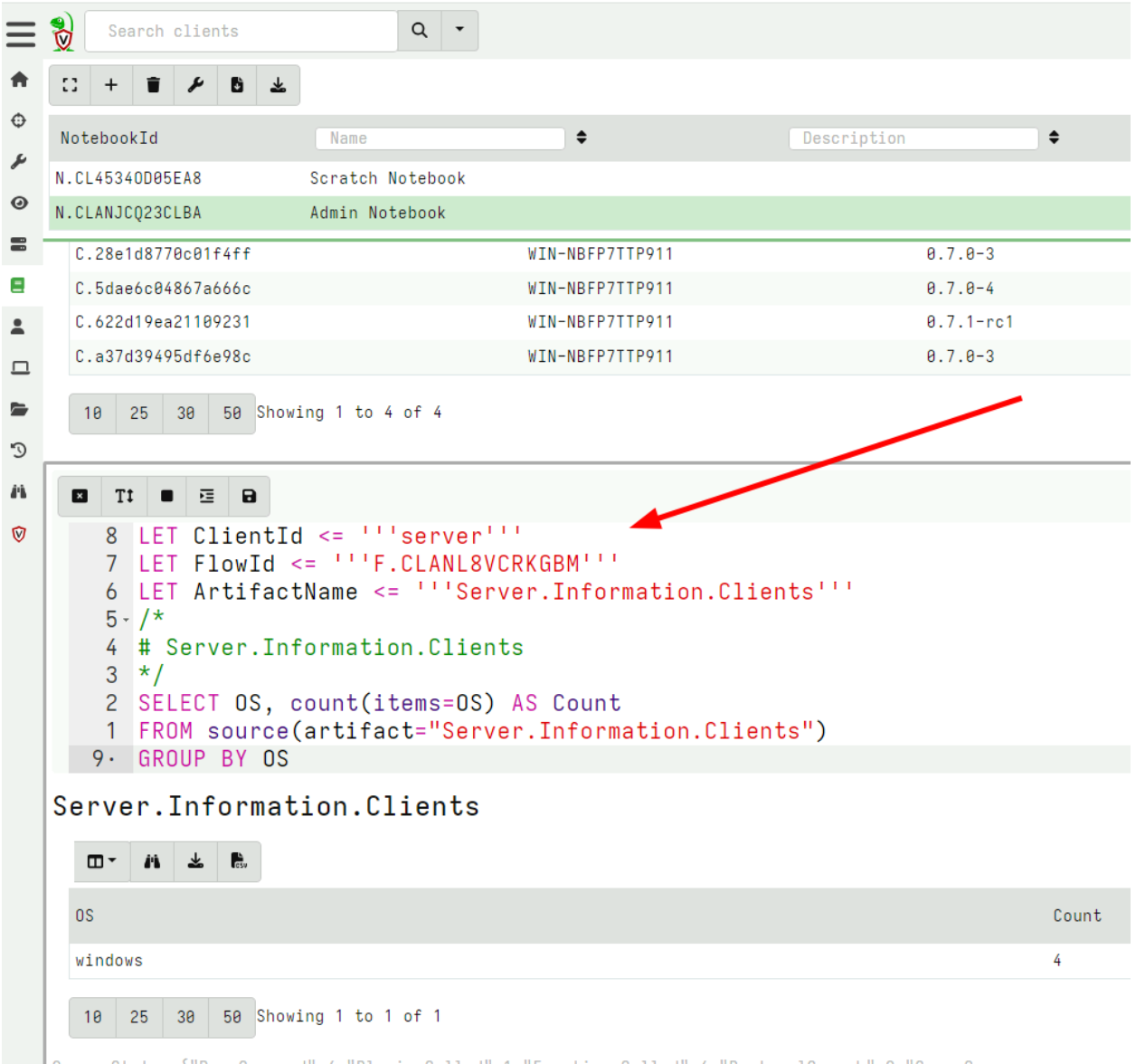
Velociraptor will copy the cell to the target notebook and add VQL statements to still refer to the original collection. This allows users of the global notebook to further refine the query if needed.
This workflow allows better collaboration between users.
VFS Downloads
Velociraptor’s VFS view is an interactive view of the endpoint’s filesystem. Users can navigate the remote filesystem using a familiar tree based navigation and interactively fetch various files from the endpoint.
Before the 0.7.1 release, the user was able to download and preview individual files in the GUI but it was difficult to retrieve multiple files downloaded into the VFS.
In the 0.7.1 release, there is a new GUI button to initiate a collection from the VFS itself. This allows the user to download all or only some of the files they had previously interactively downloaded into the VFS.
For example consider the following screenshot that shows a few files downloaded into the VFS.
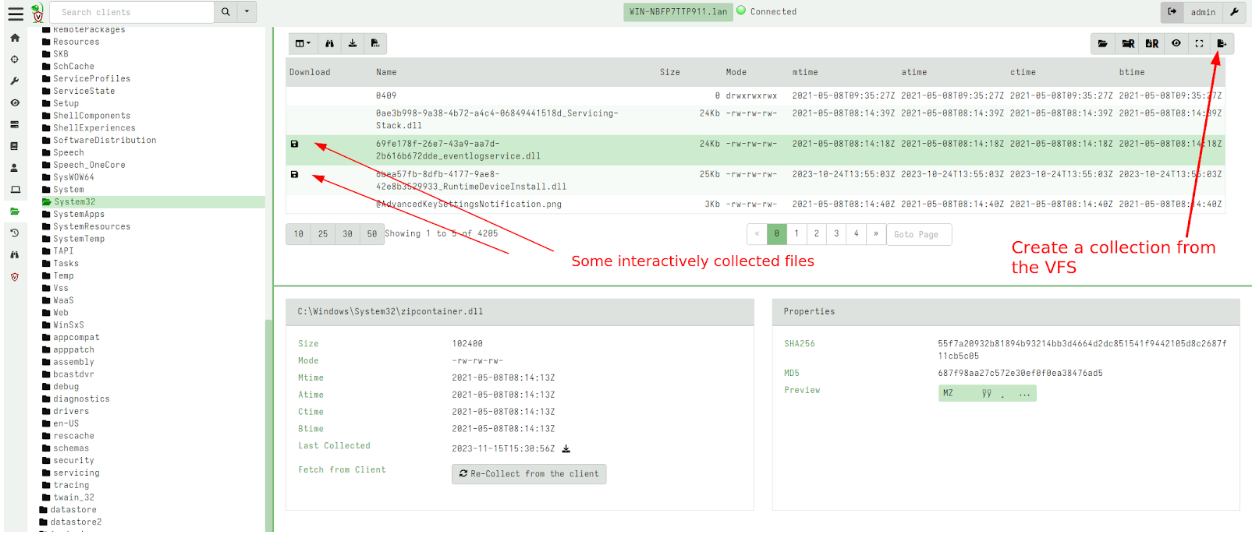
I can initiate a collection from the VFS. This is a server artifact (similar to the usual File Finder artifacts) that simply traverses the VFS with a glob uploading all files into a single collection.
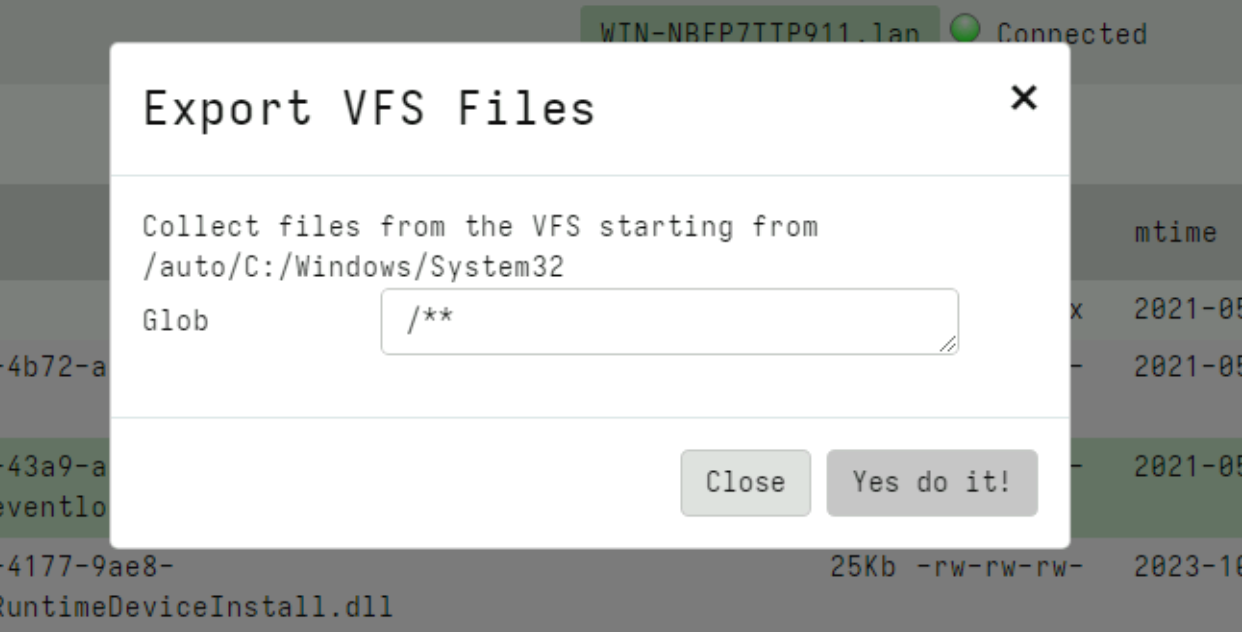
Using the glob I can choose to retrieve files with a particular filename pattern (e.g. only executables) or all files.
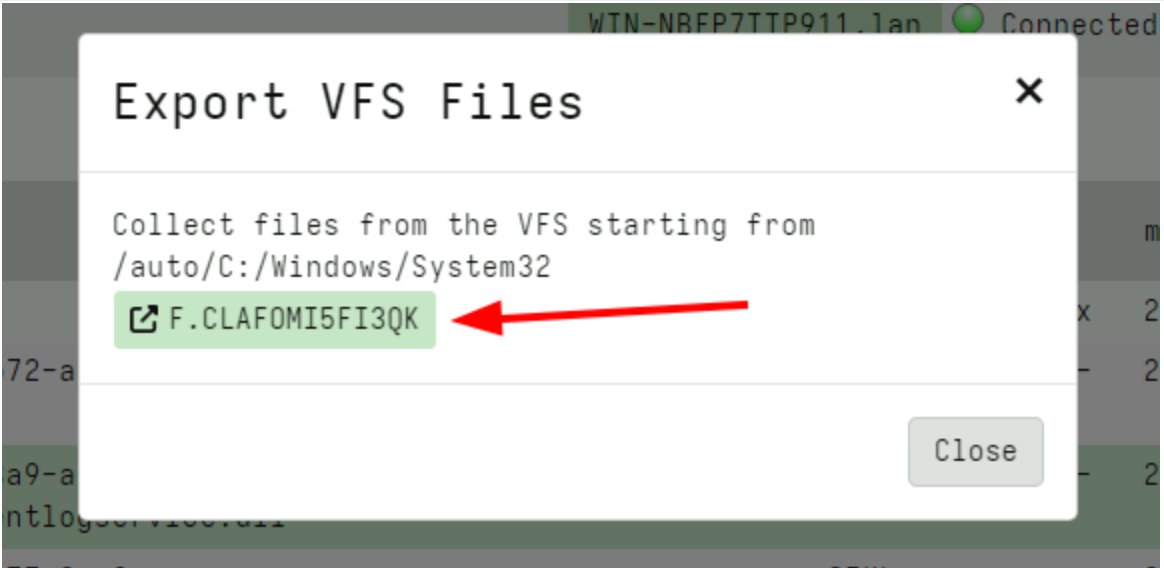
Finally the GUI shows a link to the collected flow where I can inspect the files or prepare a download zip just like any other collection.
New VQL plugins and capabilities
This release introduces an exciting new capability: Built-in Sigma Support.
Built-in Sigma Support
Sigma is fast emerging as a popular standard for writing and distributing detections. Sigma was originally designed as a portable notation for multiple backend SIEM products: Detections expressed in Sigma rules can be converted (compiled) into a target SIEM query language (for example into Elastic queries) to run on the target SIEM.
Velociraptor is not really a SIEM in the sense that we do not usually forward all events to a central storage location where large queries can run on it. Instead, Velociraptor’s philosophy is to bring the query to the endpoint itself.
In Velociraptor, Sigma rules can directly be used on the endpoint, without the need to forward all the events off the system first! This makes Sigma a powerful tool for initial triage:
- Apply a large number of Sigma rules on the local event log files.
- Those rules that trigger immediately surface potentially malicious activity for further scrutiny.
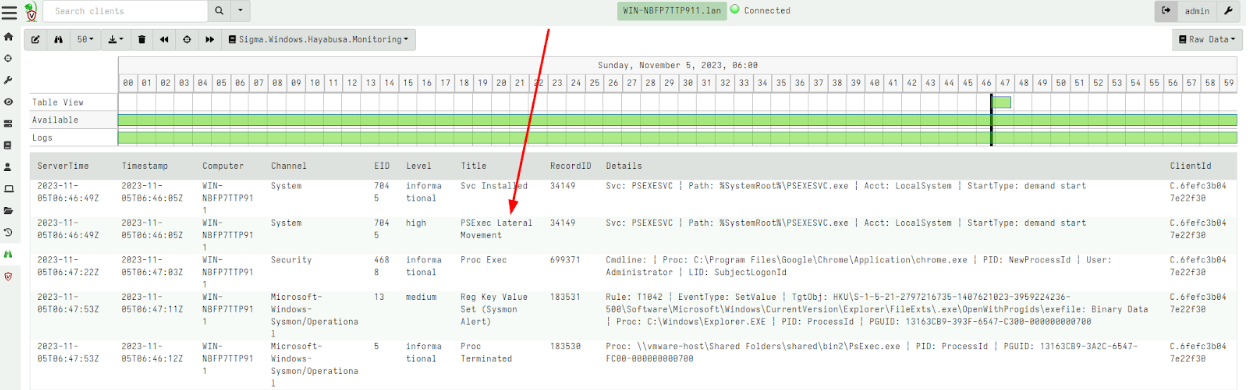
This can be done quickly and at scale to narrow down on potentially interesting hosts during an IR. A great demonstration of this approach can be seen in the Video Live Incident Response with Velociraptor where Eric Capuano uses the Hayabusa tool deployed via Velociraptor to quickly identify the attack techniques evident on the endpoint.
Previously we could only apply Sigma rules in Velociraptor by bundling the Hayabusa tool, which presents a curated set of Sigma rules but runs locally. In this release Sigma matching is done natively in Velociraptor and therefore the Velociraptor Sigma project simply curates the same rules that Hayabusa curates but does not require the Hayabusa binary itself.
You can read the full Sigma In Velociraptor blog post that describes this feature in great detail, but here I will quickly show how it can be used to great effect.
First I will import the set of curated Sigma rules from the Velociraptor Sigma project by collecting the Server.Import.CuratedSigma server artifact.
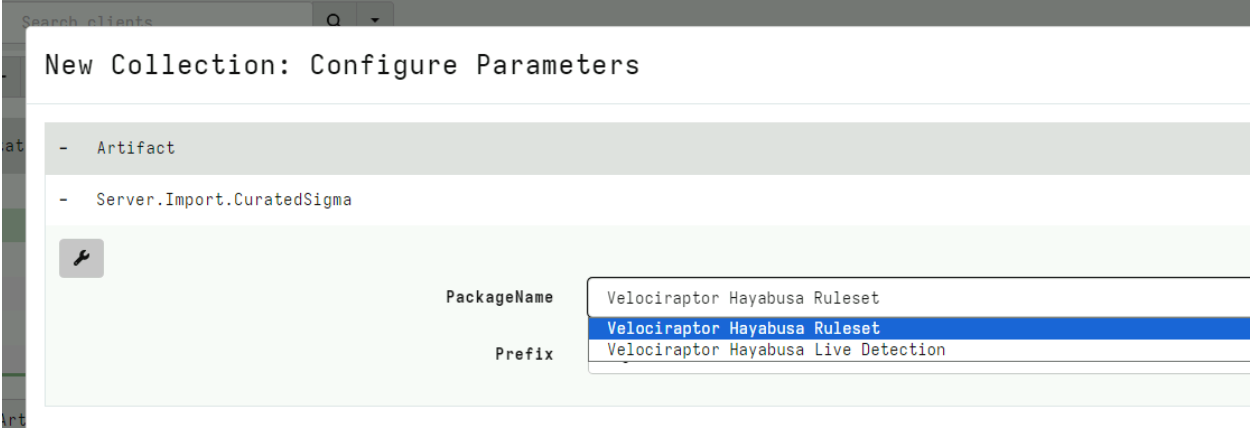
This will import a new artifact to my system with up to date Sigma rules, divided into different Status, Rule Level etc. For this example I will select the Stable rules at a Critical Level.
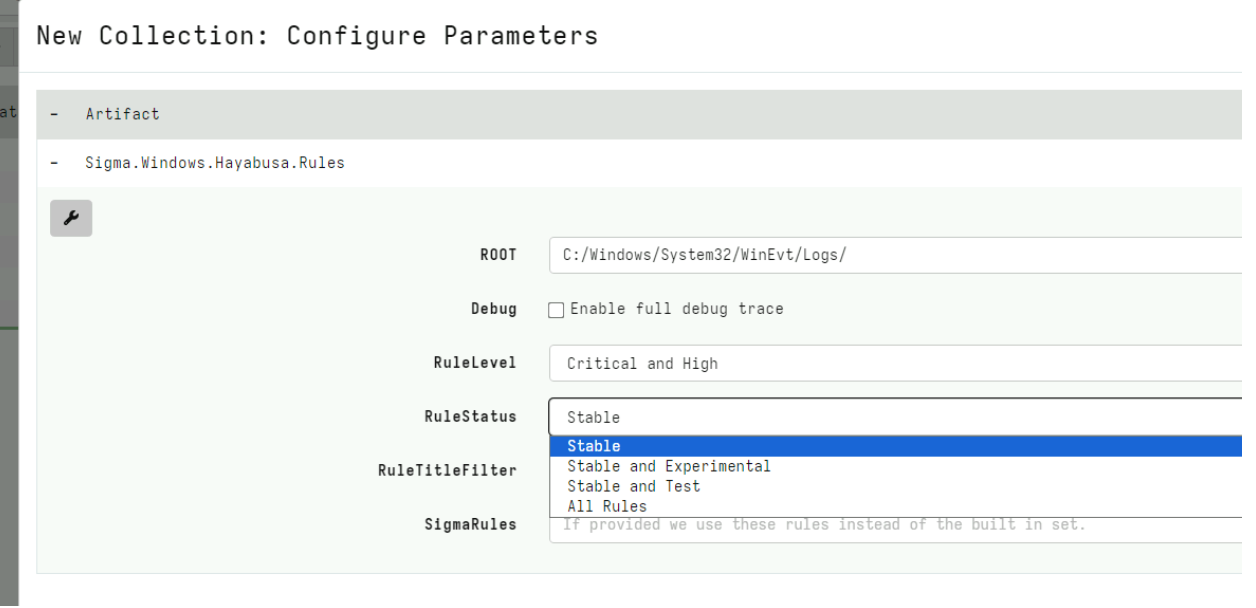
After launching the collection, the artifact will return all the matching rules and their relevant events. This is a quick artifact taking less than a minute on my test system. I immediately see interesting hits.
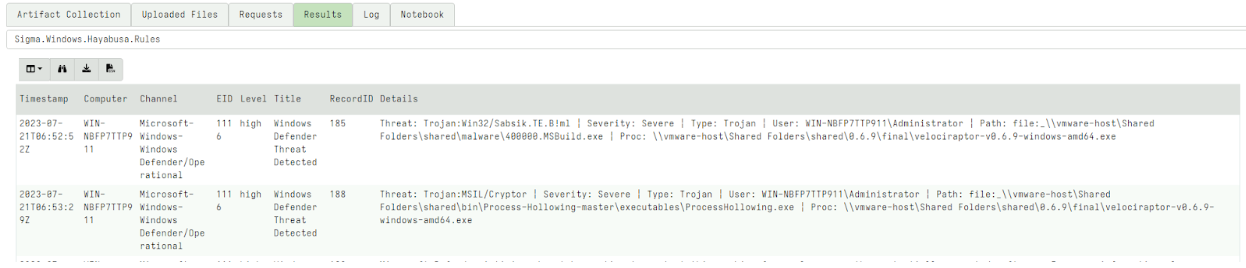
Using Sigma rules for live monitoring
Sigma rules can be used on more than just log files. The Velociraptor Sigma project also provides monitoring rules that can be used on live systems for real time monitoring.
The Velociraptor Hayabusa Live Detection option in the Curated import artifact will import an event monitoring version of the same curated Sigma rules. After adding the rule to the client’s monitoring rules with the GUI, I can receive interesting events for matching rules:
Other Improvements
SSH/SCP accessor
Velociraptor normally runs on the endpoint and can directly collect evidence from the endpoint. However, many devices on the network can not install an endpoint agent - either because the operating system is not supported (for example embedded versions of Linux) or due to policy.
When we need to investigate such systems we often can only access them by Secure Shell (SSH). In the 0.7.1 release, Velociraptor has an ssh accessor which allows all plugins that normally use the filesystem to transparently use SSH instead.
For example, consider the glob() plugin which searches for files.
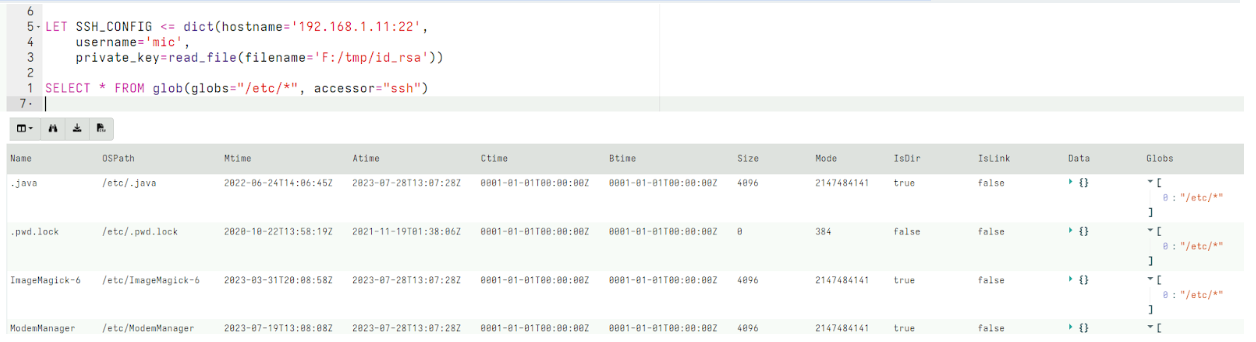
We can specify that the glob() use the ssh accessor to access the remote system. By setting the SSH_CONFIG VQL variable, the accessor is able to use the locally stored private key to be able to authenticate with the remote system to access remote files.
We can combine this new accessor with the remapping feature to reconfigure the VQL engine to substitute the auto accessor with the ssh accessor when any plugin attempts to access files. This allows us to transparently use the same artifacts that would access files locally, but this time transparently will access these files over SSH:
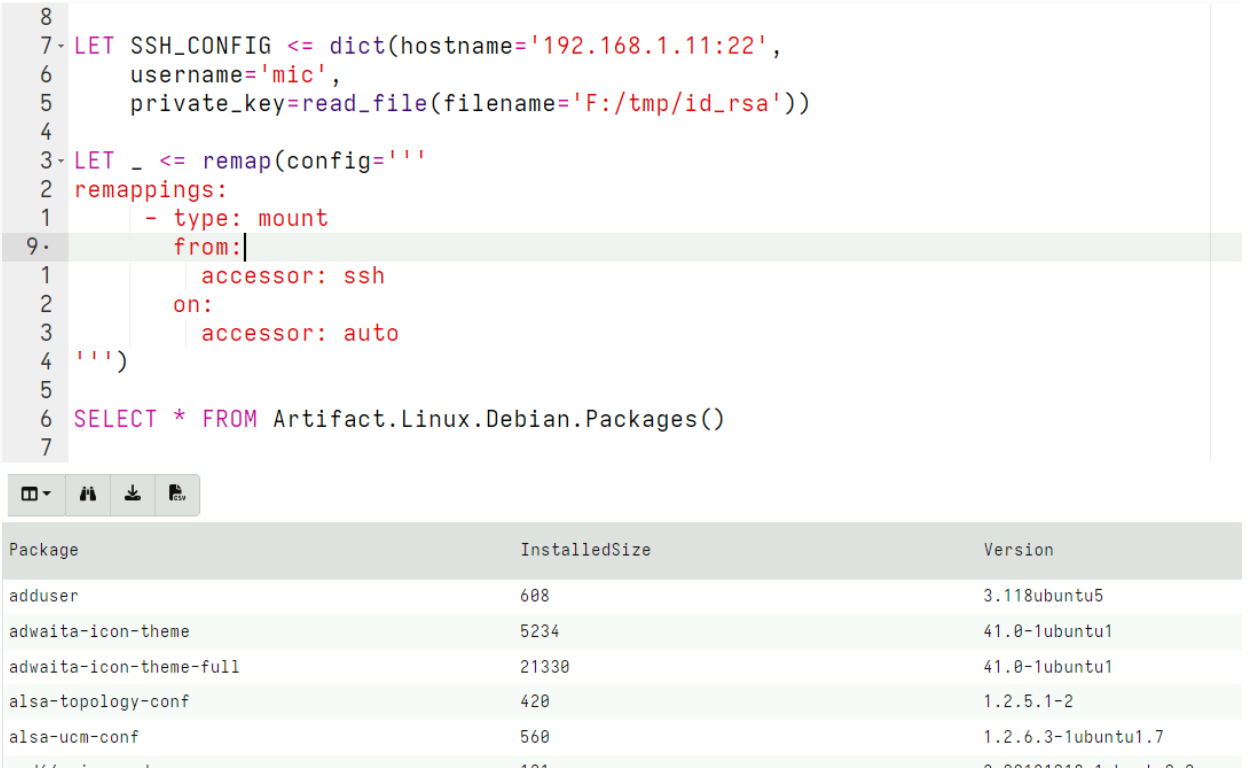
This example shows how to use the SSH accessor to investigate a debian system and collect the Linux.Debian.Packages artifact from it over SSH.
Distributed notebook processing
While Velociraptor is very efficient and fast, and can support a large number of endpoints connected to the server, many users told us that on busy servers, running notebook queries can affect server performance. This is because a notebook query can be quite intense (e.g. Sorting or Grouping a large data set) and in the default configuration the same server is collecting data from clients, performing hunts, and also running the notebook queries.
This release allows notebook processors to be run in another process. In Multi-Frontend configurations (also called Master/Minion configuration), the Minion nodes will now offer to perform notebook queries away from the master node. This allows this sudden workload to be distributed to other nodes in the cluster and improve server and GUI performance.
ETW Multiplexing
Previous support for Event Tracing For Windows (ETW) was rudimentary. Each query that called the watch_etw() plugin to receive the event stream from a particular provider created a new ETW session. Since the total number of ETW sessions on the system is limited to 64, this used precious resources.
In 0.7.1 the ETW subsystem was overhauled with the ability to multiplex many ETW watchers on top of the same session. The ETW sessions are created and destroyed on demand. This allows us to more efficiently track many more ETW providers with minimal impact on the system.
Additionally the etw_sessions() plugin can show statistics for all sessions currently running including the number of dropped events.
Artifacts can be hidden in the GUI
Velociraptor comes with a large number of built in artifacts. This can be confusing for new users and admins may want to hide artifacts in the GUI.
You can now hide an artifact from the GUI using the artifact_set_metadata() VQL function. For example the following query will hide all artifacts which do not have Linux in their name.

Only Linux related artifacts will now be visible in the GUI.

Local encrypted storage for clients
It is sometimes useful to write data locally on endpoints instead of transferring the data to the server. For example, if the client is not connected to the internet for long periods it is useful to write data locally. Also useful is to write data in case we want to recover it later during an investigation.
The downside of writing data locally on the endpoints is that this data may be accessed if the endpoint is later compromised. If the data contains sensitive information this can be used by an attacker. This is also primarily the reason that Velociraptor does not write a log file on the endpoint. Unfortunately this makes it difficult to debug issues.
The 0.7.1 release introduces a secure local log file format. This allows the Velociraptor client to write to the local disk in a secure way. Once written the data can only be decrypted by the server.
While any data can be written to the encrypted local file, the Generic.Client.LocalLogs artifact allows Velociraptor client logs to be written at runtime.
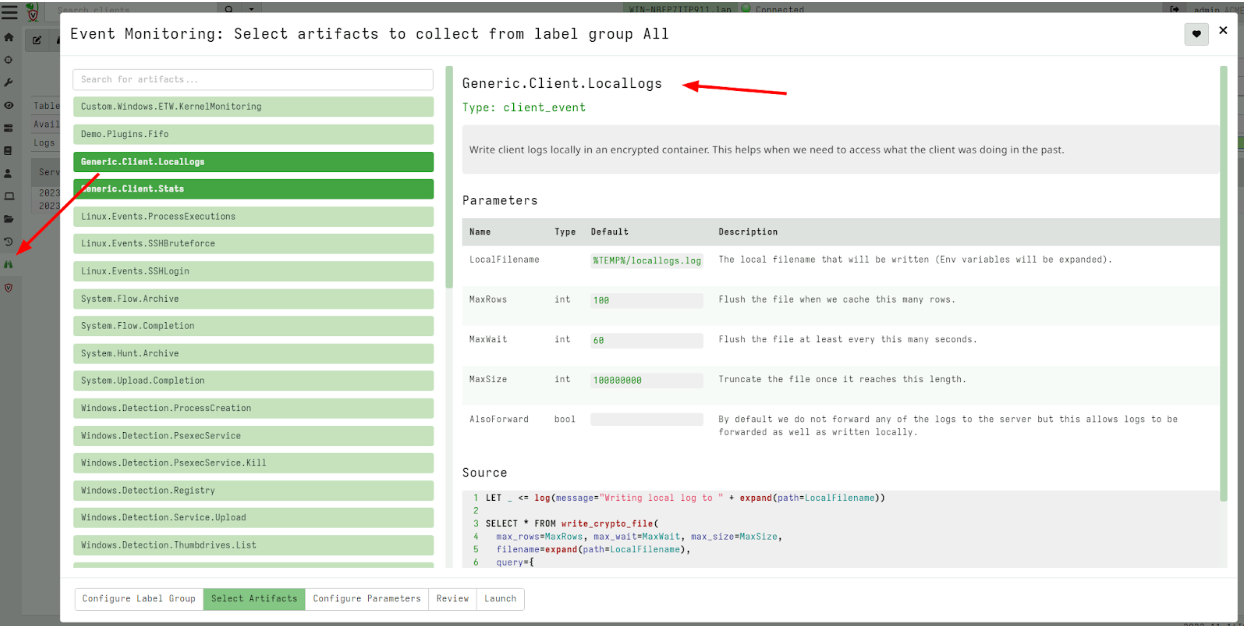
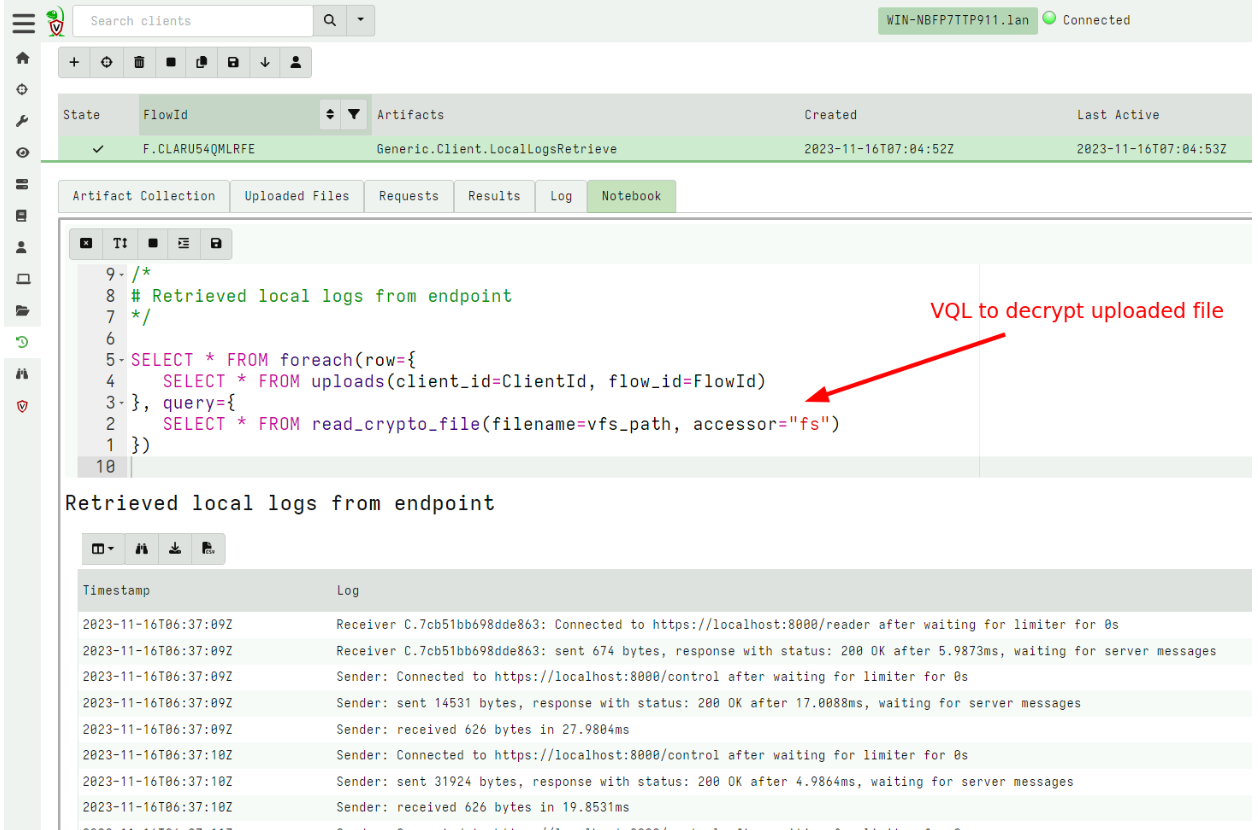
To read these locally stored logs I can fetch them using the Generic.Client.LocalLogsRetrieve artifact to retrieve the encrypted local file. The file is encrypted using the server’s public key and can only be decrypted on the server.
Once on the server, I can decrypt the file using the collection’s notebook which automatically decrypts the uploaded file.
Conclusions
There are many more new features and bug fixes in the 0.7.1 release. If you’re interested in any of these new features, we welcome you to take Velociraptor for a spin by downloading it from our release page. It’s available for free on GitHub under an open-source license.
As always, please file bugs on the GitHub issue tracker or submit questions to our mailing list by emailing velociraptor-discuss@googlegroups.com. You can also chat with us directly on our Discord server.
Learn more about Velociraptor by visiting any of our web and social media channels below:
They’re short unique strings:
Sqids (pronounced “squids”) is an open-source library that lets you generate YouTube-looking IDs from numbers. These IDs are short, can be generated from a custom alphabet and are guaranteed to be collision-free.
I haven’t dug into the details enough to know how they can be guaranteed to be collision-free.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Read my blog posting guidelines here.
Google removed fake Signal and Telegram apps from its Play store.
An app with the name Signal Plus Messenger was available on Play for nine months and had been downloaded from Play roughly 100 times before Google took it down last April after being tipped off by security firm ESET. It was also available in the Samsung app store and on signalplus[.]org, a dedicated website mimicking the official Signal.org. An app calling itself FlyGram, meanwhile, was created by the same threat actor and was available through the same three channels. Google removed it from Play in 2021. Both apps remain available in the Samsung store.
Both apps were built on open source code available from Signal and Telegram. Interwoven into that code was an espionage tool tracked as BadBazaar. The Trojan has been linked to a China-aligned hacking group tracked as GREF. BadBazaar has been used previously to target Uyghurs and other Turkic ethnic minorities. The FlyGram malware was also shared in a Uyghur Telegram group, further aligning it to previous targeting by the BadBazaar malware family.
Signal Plus could monitor sent and received messages and contacts if people connected their infected device to their legitimate Signal number, as is normal when someone first installs Signal on their device. Doing so caused the malicious app to send a host of private information to the attacker, including the device IMEI number, phone number, MAC address, operator details, location data, Wi-Fi information, emails for Google accounts, contact list, and a PIN used to transfer texts in the event one was set up by the user.
This kind of thing is really scary.