I think I've finally caught my breath after dealing with those 23 billion rows of stealer logs last week. That was a bit intense, as is usually the way after any large incident goes into HIBP. But the confusing nature of stealer logs coupled with an overtly long blog post explaining them and the conflation of which services needed a subscription versus which were easily accessible by anyone made for a very intense last 6 days. And there were the issues around source data integrity on top of everything else, but I'll come back to that.
When we launched the ability to search through stealer logs last month, that wasn't the first corpus of data from an info stealer we'd loaded, it was just the first time we'd made the website domains they expose searchable. Now that we have an actual model around this, we're going to start going back through those prior incidents and backfilling the new searchable attributes. We've just done that with the 26M unique email address corpus from August last year and added XXX new instances of an email address mapped against a website domain. We've also now flagged that incident as "IsStealerLog" so if you're using the API, you'll see that attribute now set to true.
For the most part, that data is all handled just the same as the existing stealer log data: we map email addresses to the domains they've appeared against in the logs then make all that searchable by full email address, email address domain or website domain (read last week's really, really long blog post if you need an explainer on that). But there's one crucial difference that we're applying both to the backfilling and the existing data, and that's related to a bit of cleaning up.
A theme that emerged last week was that there were email addresses that only appeared against one domain, and that was the domain the address itself was on. If john@gmail.com is in there and the only domain he appears against is gmail.com, what's up with that? At face value, John's details have been snared whilst logging on to Gmail, but it doesn't make sense that someone infected with an info stealer only has one website they've logging into captured by the malware. It should be many. This seems to be due to a combination of the source data containing credential stuffing rows (just email and password pairs) amidst info stealer data and somewhere in our processing pipeline, introducing integrity issues due to the odd inputs. Garbage in, garbage out, as they say.
So, we've decided to apply some Occam's razor to the situation and go with the simplest explanation: a single entry for an email address on the domain of that email address is unlikely to indicate an info stealer infection, so we're removing those rows. And not adding any more that meet that criteria. But there's no doubt the email address itself existed in the source; there is no level of integrity issues or parsing errors that causes john@gmail.com to appear out of thin air, so we're not removing the email addresses in the breach, just their mapping to the domain in the stealer log. I'd already explained such a condition in Jan, where there might be an email address in the breach but no corresponding stealer log entry:
The gap is explained by a combination of email addresses that appeared against invalidly formed domains and in some cases, addresses that only appeared with a password and not a domain. Criminals aren't exactly renowned for dumping perfectly formed data sets we can seamlessly work with, and I hope folks that fall into that few percent gap understand this limitation.
FWIW, entries that matched this pattern accounted for 13.6% of all rows in the stealer log table, so this hasn't made a great deal of difference in terms of outright volume.
This takes away a great deal of confusion regarding the infection status of the address owner. As part of this revision, we've updated all the stealer log counts seen on domain search dashboards, so if you're using that feature, you may see the number drop based on the purged data or increase based on the backfilled data. And we're not sending out any additional notifications for backfilled data either; there's a threshold at which comms becomes more noise than signal and I've a strong suspicion that's how it would be received if we started sending emails saying "hey, that stealer log breach from ages ago now has more data".
And that's it. We'll keep backfilling data, and the entire corpus within HIBP is now cleaner and more succinct. And we'll definitely clean up all the UX and website copy as part of our impending rebrand to ensure everything is a lot clearer in the future.
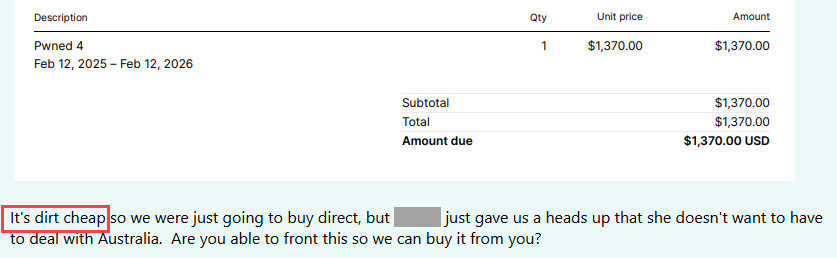
I'll leave you with a bit of levity related to subscription costs and value. As I recently lamented, resellers can be a nightmare to deal with, and we're seriously considering banning them altogether. But occasionally, they inadvertently share more than they should, and we get an insight into how the outside world views the service. Like a recent case where a reseller accidentally sent us the invoice they'd intended to send the customer who wanted to purchase from us, complete with a 131% price markup 😲 It was an annual Pwned 4 subscription that's meant to be $1,370, and simply to buy this on that customer's behalf and then hand them over to us, the reseller was charging $3,165. They can do this because we make the service dirt cheap. How do we know it's dirt cheap? Because another reseller inadvertently sent us this internal communication today:
FWIW, we do have credit cards in Australia, and they work just the same as everywhere else. I still vehemently dislike resellers, but at least our customers are getting a good deal, especially when they buy direct 😊
I like to start long blog posts with a tl;dr, so here it is:
We've ingested a corpus of 1.5TB worth of stealer logs known as "ALIEN TXTBASE" into Have I Been Pwned. They contain 23 billion rows with 493 million unique website and email address pairs, affecting 284M unique email addresses. We've also added 244M passwords we've never seen before to Pwned Passwords and updated the counts against another 199M that were already in there. Finally, we now have a way for domain owners to query their entire domain for stealer logs and for website operators to identify customers who have had their email addresses snared when entering them into the site.
This work has been a month-long saga that began hot off the heels of processing the last massive stash of stealer logs in the middle of Jan. That was the first time we'd ever added more context to stealer logs by way of making the websites email addresses had been logged against searchable. To save me repeating it all here, if you're unfamiliar with stealer logs as a concept and what we've previously done with HIBP, start there.
Up to speed? Good, let's talk about ALIEN TXTBASE.
Origin Story
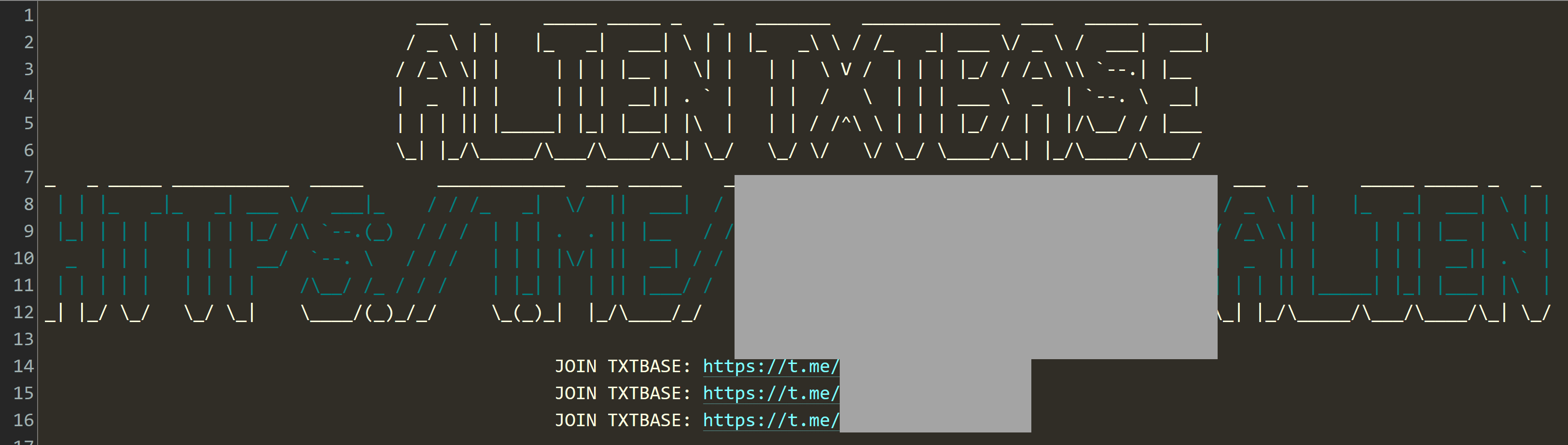
Last month after loading the aforementioned corpus of data, someone in a government agency reached out and pointed me in the direction of more data by way of two files totalling just over 5GB. Their file names respectively contained the numbers "703" and "704", the word "Alien" and the following text at the beginning of each file:
Pulling the threads, it turned out the Telegram channel referred to contained 744 files of which my contact had come across just the two. The data I'm writing about today is that full corpus, published to Telegram as individual files:
The file in the image above contained over 36 million rows of data consisting of website URLs and the email addresses and passwords entered into them. But the file is just a sample - a teaser - with more data available via the subscription options offered in the message. And that's the monetisation route: provide existing data for free, then offer a subscription to feed newly obtained logs to consuming criminals with a desire to exploit the victims again. Again? The stealer logs are obtained in the first place by exploiting the victim's machine, for example:
How do people end up in stealer logs? By doing dumb stuff like this: “Around October I downloaded a pirated version of Adobe AE and after that a trojan got into my pc” pic.twitter.com/igEzOayCu6
So now this guy has malware running on his PC which is siphoning up all his credentials as they're entered into websites. It's those credentials that are then sold in the stealer logs and later used to access the victim's accounts, which is the second exploitation. Pirating software is just one way victims become infected; have a read of this recent case study from our Australian Signals Directorate:
When working from home, Alice remotely accesses the corporate network of her organisation using her personal laptop. Alice downloaded, onto her personal laptop, a version of Notepad++ from a website she believed to be legitimate. An info stealer was disguised as the installer for the Notepad++ software.
When Alice attempted to install the software, the info stealer activated and began harvesting user credentials from her laptop. This included her work username and password, which she had saved in her web browser’s saved logins feature. The info stealer then sent those user credentials to a remote command-and-control server controlled by a cybercriminal group.
Eventually, data like Alice's ends up in places like this Telegram channel and from there, it enables further crimes. From the same ASD article:
Stolen valid user credentials are highly valuable to cybercriminals, because they expedite the initial access to corporate networks and enterprise systems.
So, that's where the data has come from. As I said earlier, ALIEN TXTBASE is by no means the only Telegram channel out there, but it is definitely a major distribution channel.
Verification
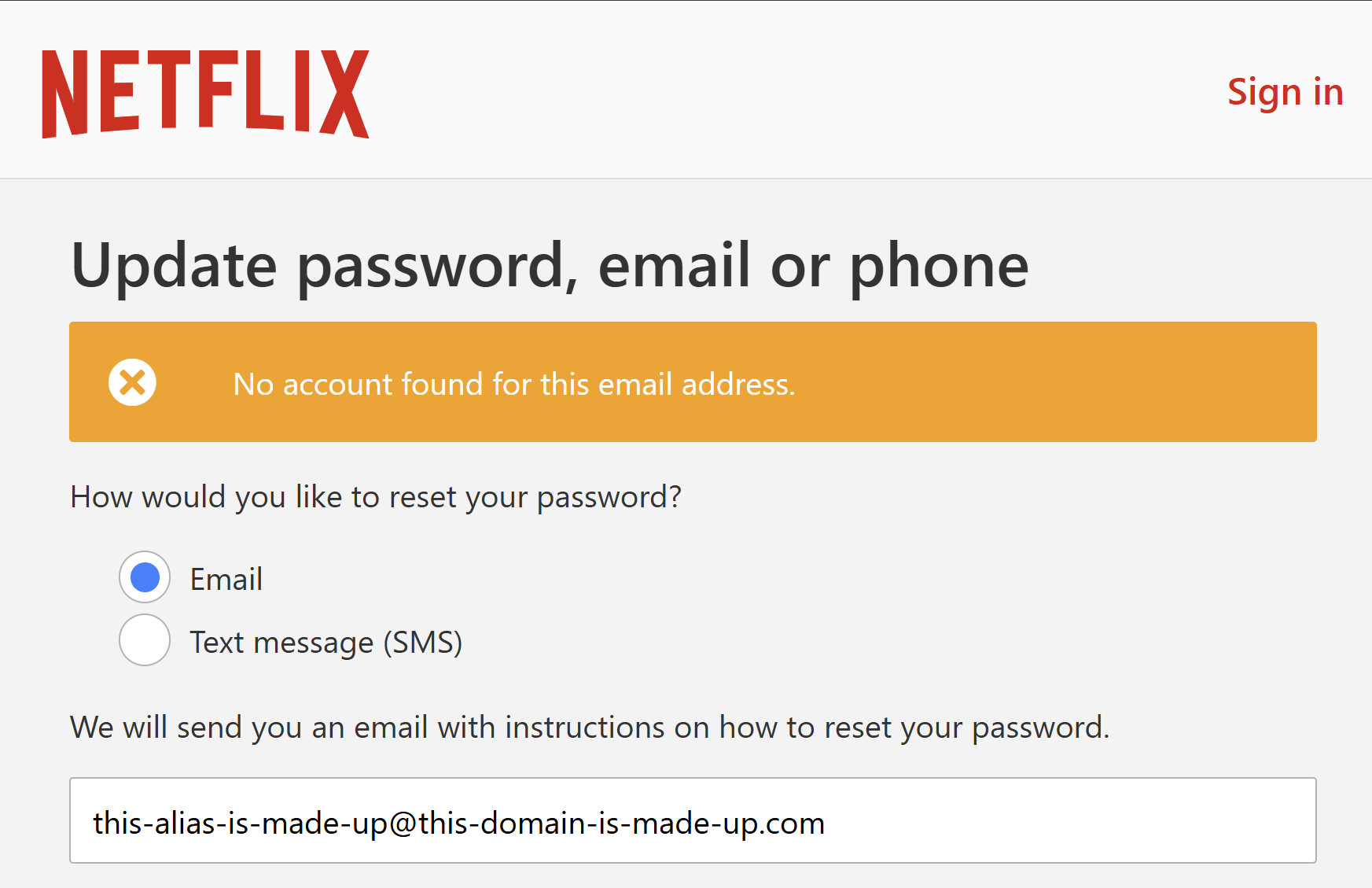
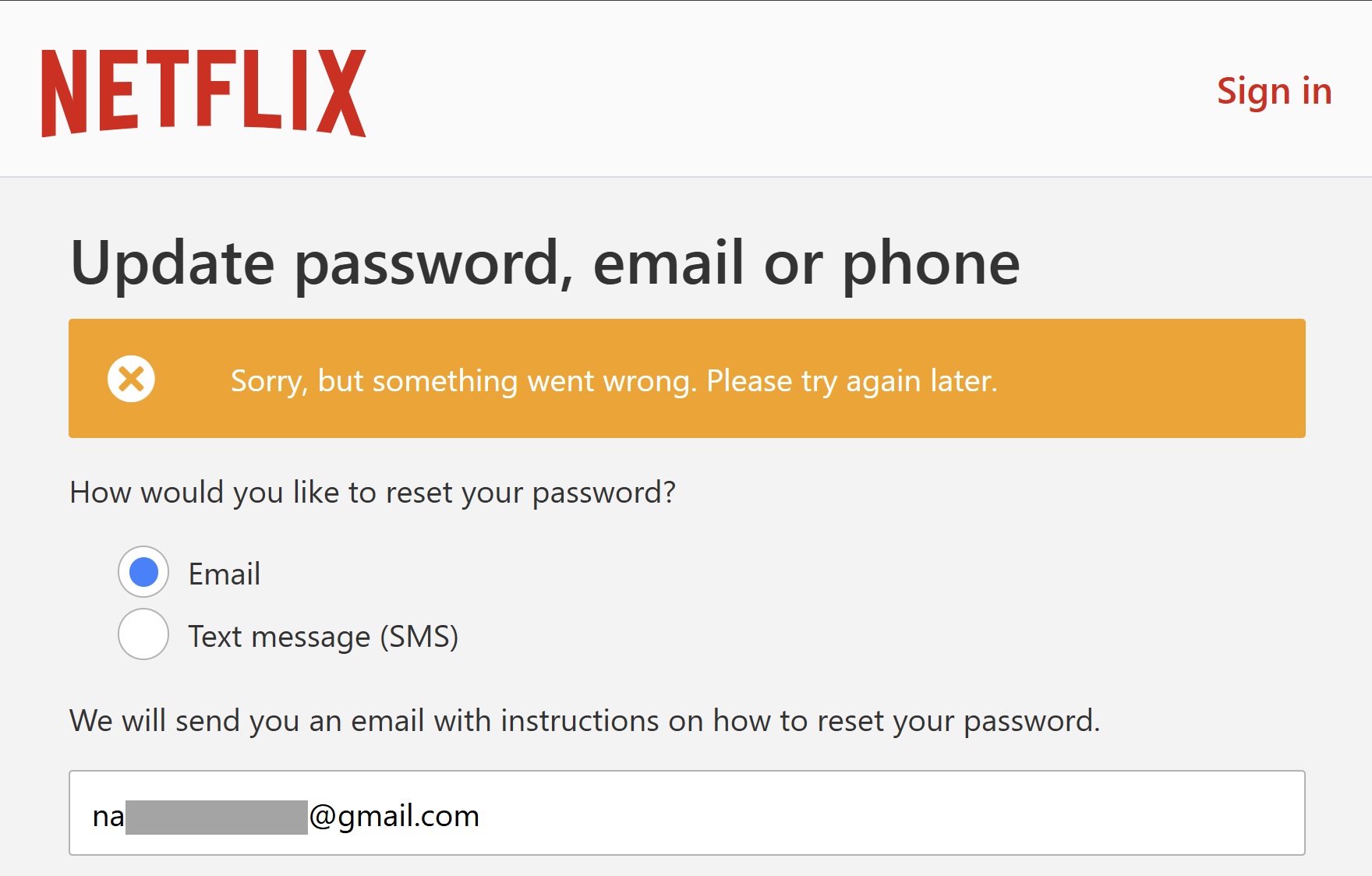
When there's a breach of a discrete website, verification of the incident is usually pretty trivial. For example, if Netflix suffered a breach (and I have no indication they have, this is just an example), I can go to their website, head to the password reset field, enter a made-up email address and see a response like this:
On the other hand, an address that does exist on the service usually returns a message to the effect of "we've sent you a password reset email". This is called an "enumeration vector" in that it enables you to enumerate through a list of email addresses and find out which ones have an account on the site.
But stealer logs don't come from a single source like Netflix, instead they contain the credentials for a whole range of different sites visited by people infected with malware. However, I can still take lines from the stealer logs that were captured against Netflix and test the email addresses. (Note: I never test if the password is valid, that would be a privacy violation that constitutes unauthorised access and besides, as you'll read next, there's simply no need to.)
Initially, I actually ran into a bit of a roadblock when testing this:
I found this over and over again so, I went back and checked the source data and inspected this poor victim's record:
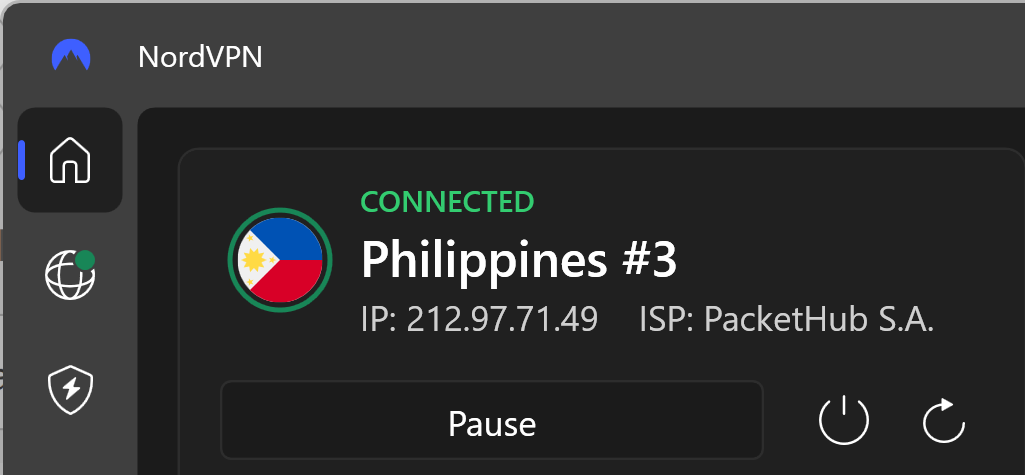
Their Netflix credentials were snared when they were entered into the website with a path of "/ph-en/login", implying they're likely Filipino. Let's try VPN'ing into Manilla:
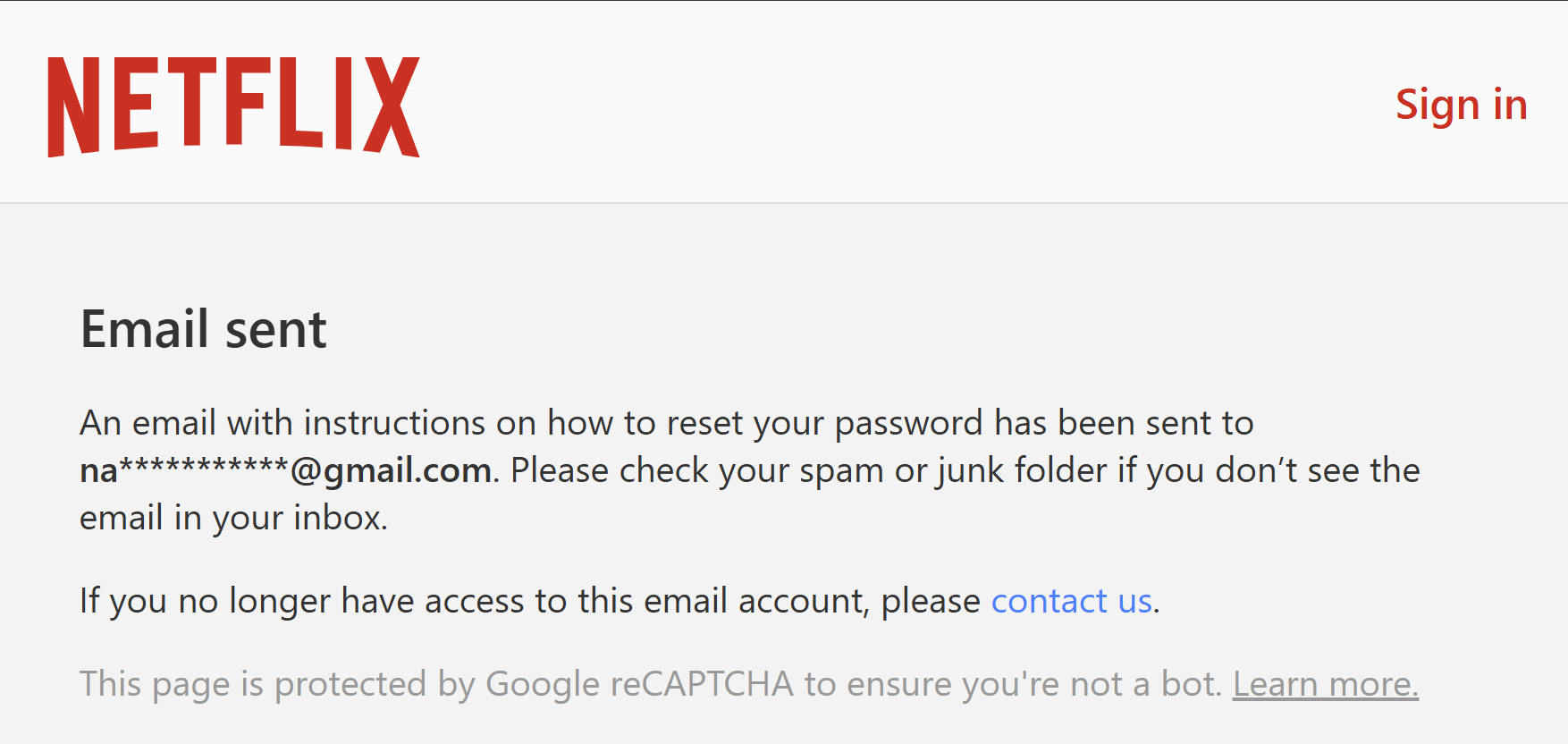
And suddenly, a password reset gives me exactly what I need:
That's a little tangent from stealer logs, but Netflix obviously applies some geo-fencing logic to certain features. This actually worked out better than expected verification-wise because not only was I able to confirm the presence of the email address on their service, but that the stealer log entry placing them in the Philippines was also geographically correct. It was reproducible too: when I saw "something went wrong", but the path began with "mx", I VPN'd into Mexico City and Netflix happily confirmed the reset email was sent. Another path had "ve", so it was off to Caracas and the Venezuelan victim's account was confirmed. You get the idea. So, strong signal on confirmation of account existence via password reset, now let's also try something more personal.
I emailed a handful of HIBP subscribers and asked for their support verifying a breach. I got a fast, willing response from one guy and sent over more than 1,100 rows of data against his address 😲 It's fascinating what you can tell about a person from stealer log data: He's obviously German based on the presence of websites with a .de address, and he uses all the usual stuff most of us do (Amazon, eBay, LinkedIn, Airbnb). But it's the less common ones that make for more interesting reading: He drives a Mercedes because he's been logging into an address there for owners, and it also appears he likes whisky given his account at an online specialist. He's a Firefox user, as he's logged in there too, and he seems to be a techie as he's logged into Seagate and a site selling some very specialised electrical testing equipment. But is it legit?
Imagine the heart-in-mouth moment the poor guy must have had seeing his digital life laid out in front of him like that and knowing criminals have this data. It'd be a hell of a shock.
Having said all that, whilst I'm confident there's a large volume of legitimate data in this corpus, it's also possible there will be junk. Fabricated email addresses, websites that were never used, etc. I hope folks who experience this can appreciate how hard it is for us to discern "legitimate" stealer logs from those that were made up. We've done as much parsing and validation as possible, but we have no way of knowing if someone@yourdomain.com is an email address that actually exists or if it does, if they ever actually used Netflix or Spotify or whatever. They're just strings of data, and all we can do is report them as found.
Searching Entries Against Your Website with a Pwned 5 Subscription
When we published the stealer logs last month, I kept caveating everything with "experimental". Even the first word of the blog post title was "experimenting", simply because we didn't know how this would be received. Would people welcome the additional data we were making available? Or find it unactionable noise? It turns out it was entirely the former, and I didn't see a single negative comment or, as it often has been in the past with stealer logs or malware breaches, angry victims demanding I send their entire row(s) of data. And I guess that makes sense given what we made available so, starting today, we're making even more available!
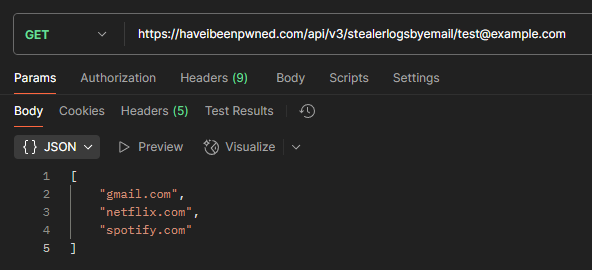
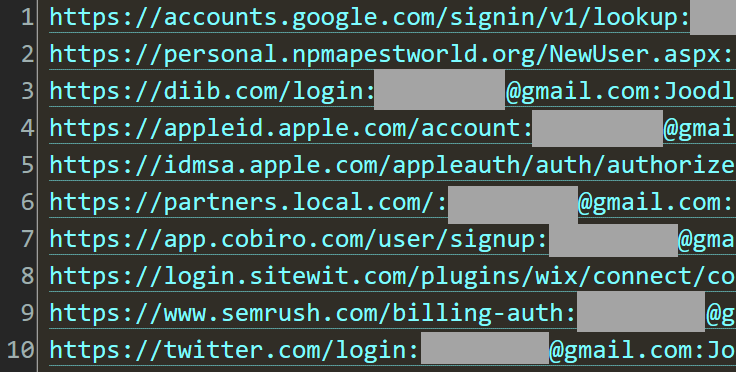
First, a bit of nomenclature. Consider the following stealer log entry:
There are four parts to this entry that are relevant to the HIBP services I'm going to write about here:
Email Address
Website Domain
Email Alias
Email Domain
https://
www.netflix.com
/en-ph/login
john
@
example.com
P@ssw0rd
Last month, we added functionality to the UI such that after verifying your email address you could see a collection of website domains. In the example above, this meant that John could use the free notification service to verify control of his email address after which he'd see www.netflix.com listed. (Note: we're presently totally redesigning this as part of our UX rebuild and it'll be much smoother in the very near future.) Likewise, we introduced an API to do exactly the same thing, but only after verifying control of the email domain. So, in the case above, the owner of example.com would be able to query john@example.com and get back www.netflix.com (along with any other website domains poor John had been using).
Today, we're introducing two new APIs, and they're big ones:
Query stealer logs by email domain
Query stealer logs by website domain
The first one is akin to our existing domain search feature so in the example above, the owner of the domain could query the stealer logs for example.com and get back each email address alias and the website domains they appear against. Here's what that output looks like:
The previous model only allowed querying by email address, so you could end up with an organisation needing to iterate through thousands of individual API requests. This model means that can now be done in a single request, which will make life much easier for larger organisations assessing the exposure of their workforce.
The second new API is designed for website operators who want to identify customers who've had their credentials snared at login. So, in our demo row above, Netflix could query www.netflix.com (after verifying control of the domain, of course) and retrieve a list of their customers from the stealer logs:
[
"john@example.com",
"jane@yahoo.com"
]
Both these new APIs are orientated towards larger organisations and can return vast volumes of data. When considering how to price this service, the simplest, most commensurate model we arrived at was to use a pricing tier we already had: Pwned 5:
Whilst we'd previously only ever listed tiers 1 through 4, we'd always had higher tiers sitting there in the background for organisations needing higher rate limits. Surfacing this subscription and adding the ability to query stealer logs via these two new APIs makes it easy for new and existing subscribers alike to unlock the feature. And if you are an existing subscriber, the price is simply adjusted pro rata at Stripe's end such that your existing balance is carried forward. Per the above image, this subscription is available either monthly or annually so if you just want to see what's in the current corpus of data and keep the cost down, take it for a month then cancel it. (Note: the Pwned 5 subscription is also now required for the API to search by email address we launched last month, but the web UI that uses the notification service to show stealer log results by email is absolutely still free and will remain that way.)
Another small addition since last month is that we've added an "IsStealerLog" flag on the breach model. This means that anyone programmatically dealing with data in HIBP can now easily elect to handle stealer logs differently than other breaches. For example, a new breach with this flag set to "true" might then trigger a query of the new API endpoints to search by domain so that an organisation can update their records with any new stealer log entries.
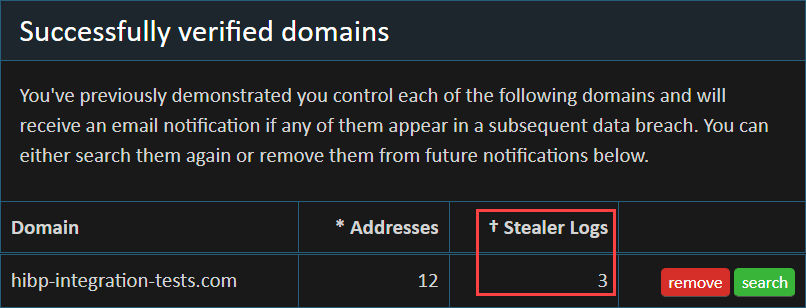
Anyone searching by email domain already knows the scope of addresses on their domain as it's reported on their dashboard. Plus, when email notifications are sent on breach load it tells you exactly how many new addresses from your domains are in the breach. Starting today, we've also added a column to explain how many email addresses appear against your website domain:
In other words, 3 people have had their email address grabbed by an info stealer when logging on to hibp-integration-tests.com, and the new API will return all of those addresses. It is only API-based for the moment, we'll consider if a UI makes sense as part of the rebranded site launch, it may not becuase of the potentially huge volumes of data.
Just one last thing: for the two new APIs that query by domain, we've set a rate limit which is entirely independent of the rate limit on, say, breached account searches. Whilst a Pwned 5 subscription would allow 1,000 requests to that API every minute, it's significantly more restricted when hitting those two new stealer log APIs. We haven't published a number as I expect we'll tweak it a bit based on usage, but it's more than enough for any normal use of the service whilst ensuring we don't get completely overwhelmed by high-overhead searches. The stealer log API that queries by email address inherits the 1,000 RPM rate limit of the Pwned 5 subscription.
We've Added 244M New Passwords to Pwned Passwords
One of the coolest most awesome best things we've ever done with HIBP is to create a massive repository of passwords that's all open source (both code and data) and can be queried anonymously without disclosing the searched password. Pwned Passwords is amazing, and it has gained huge traction:
There it is - we’ve now passed 10,000,000,000 requests to Pwned Password in 30 days 😮 This is made possible with @Cloudflare’s support, massively edge caching the data to make it super fast and highly available for everyone. pic.twitter.com/kw3C9gsHmB
10 billion times a month, our API helps a service somewhere assist one of their customers with making a good password choice. And that's just the API - we have no idea the full scope of the service as having the data open source means people can just download the entire corpus and run it themselves.
Per the opening para, we now have an additional 244 million previously unseen passwords in this corpus. And, as always, they make for some fun reading:
tender-kangaroo
swimmingkangaroo59
gentlekangaroo
CaptainKangaroo340
And, uh, some kangaroos doing other stuff I can't really repeat here. Those passwords are at the final stages of loading and should flush through cache to Cloudflare's hundreds of edge nodes in the next few hours. That's another quarter of a billion that join the list of previously breached ones, whilst 199 million we'd already seen before have had their prevalence counts upped.
HIBP in Practice
It's amazing to see where my little pet project with the stupid name has gone, and nobody is more surprised than me when it pops up in cool places. Looking around for some stealer log references while writing this blog post, I came across this one:
This was already in place when you created a new account or updated your password. But now it's also verified on every login against the live HIBP database. Hats off to the tremendous service HIBP provides to the internet 🙏 https://t.co/Z61AgDaL2t
That's awesome! That's exactly the sort of use case that speaks to the motto of "do good things with breach data after bad things happen". By adding this latest trove of data, the folks using Basecamp will immediately benefit simply by virtue of the service being plugged into our API. And sidenote: David has done some amazing stuff in the past so I was especially excited to see this shout-out 😊
This one is a similar story, albeit using Pwned Passwords:
Their service is phenomenal! We also inform users in our product if they set/change their password to a known password that has been hacked. Admins have the option to not allow for users to use these passwords, if they wish. pic.twitter.com/bvLfYm9xzH
Inevitably, those requests form a slice of the 10 billion monthly we see that are now able to identify a quarter of a billion more compromised ones and hopefully, keep them out of harm's way.
For many organisations, the data we're making available via stealer logs is the missing piece of the puzzle that explains patterns that were previously unexplainable:
Gotta say I’m pretty happy with what we did with stealer logs last week, think we’re gonna need to do more of this 😎 pic.twitter.com/4rMaMmL8LU
I've had so many emails to that effect after loading various stealer logs over the years. The constant theme I love hearing is how it benefits the good guys and, well, not so much the bad guys:
The introduction of these new APIs today will finally help many organisations identify the source of malicious activity and even more importantly, get ahead of it and block it before it does damange. Whilst there won't be any set cadence to the addition of more stealer logs (obviously, we can't really predict when this stuff will emerge), I have no doubt we'll continue to add a lot more data yet.
Techie Bits
Processing this data has been non-trivial to say the least, so I thought I'd give you a bit of an overview of how I ultimately approached it. In essence, we're talking about transforming a very large amount of highly redundant text-based data and ultimately ending up with a distinct list of email addresses against website domains. Here's the high-level process:
Start with 744 files of logs totalling 1.5TB and containing 23 billion rows
In a .NET console app, process each file in point 1 and extract the domain and email address from valid lines (domain, email and password, all colon delimited) to produce 744 files totalling 390GB (9.7B rows)
In another .NET console app, consolidate all 744 files from the previous point into a single file with a distinct set of website domain and email address pairs (789M rows)
Take the file from the previous point, and in another .NET console app, extract all the unique domains (18M rows)
Use SQL BCP to upload the files from the two previous points to SQL Azure
Insert any new domains that don't already exist in HIBP (these are held in a dedicated table) via a TSQL statement (6.7M rows)
Upload the 284M unique email addresses like with a typical data breach (69% of them were already in HIBP)
Join the distinct list of domains and email addresses to the data uploaded in the previous point and insert email and domain pairs into the stealer log table, but only if they haven't been seen before via another TSQL statement (493M rows)
Wait - if I took distinct website and email pairs in step 4 and got 789M rows then in step 9 it only inserted 493M, what happened? There were 220M rows already in HIBP from last month which will account for some of the gap (existing records aren't reinserted), and there was also some additional validation in SQL Server courtesy of code we only have in that environment. The remaining gap is explained by the .NET code not ignoring case on distinct, so in other words, I dumped and uploaded way more data than I had to and made SQL Sever do extra work 🤦♂️
Go live and get 🍺
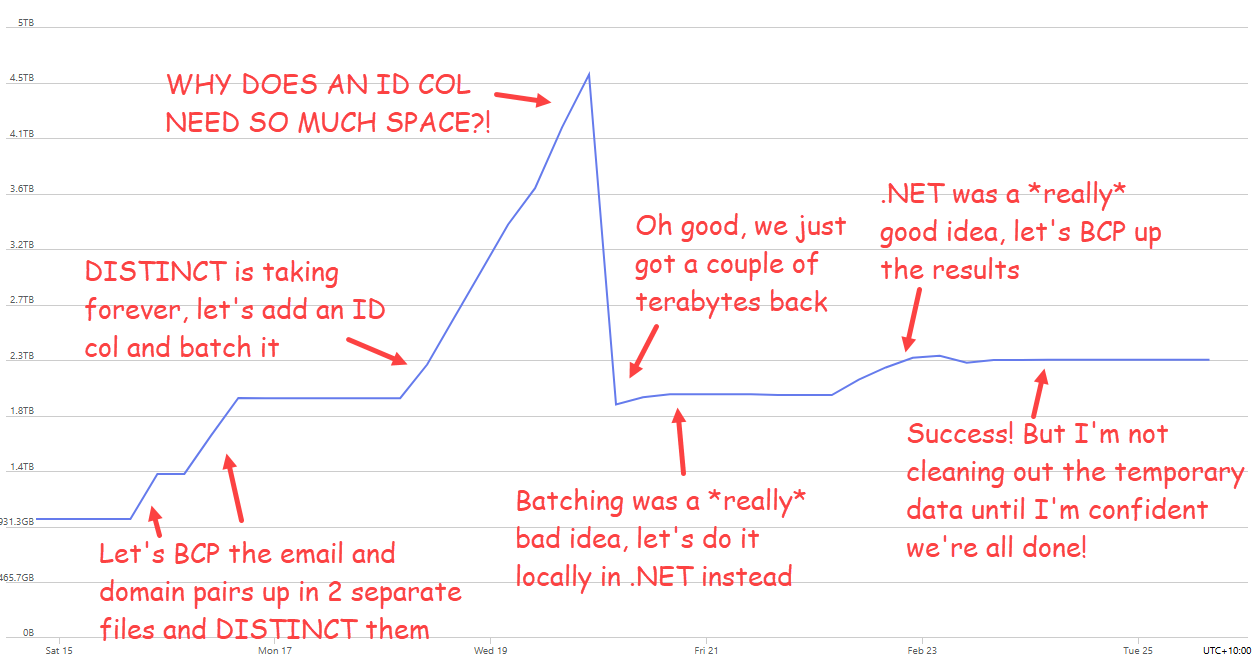
It was actually much, much harder than this due to the trials and errors of attempting to distil what starts out as tens of billions of rows down into hundreds of millions of unique examples. I was initially doing a lot more of the processing in SQL Azure because hey, it's just cloud and you can turn up the performance as much as you want, right?! After running 80 cores of Azure SQL Hyperscale for days on end ($ouch$) and seeing no end in sight to the execution of queries intended to take distinct values across billions of rows, I fell back to local processing with .NET. You could, of course, use all sorts of other technologies of choice here, but it turned out that local processing with some hand-rolled code was way more efficient than delegating the task to a cloud-based RDBMS. The space used by the database tells a big part of the story:
As I've said many times before, the cloud, my friends, is not always the answer. Do as much processing as possible locally on sunk-cost hardware unless there's a compelling reason not to.
I've detailed all this here in part because that's what I've always done with this project over the last 11 and a bit years, but also to illustrate how much time, effort, and money is burned processing data like this. It's very non-trivial, especially not when everything has to ultimately go into an increasingly large system with loads of external dependencies and be fast, reliable and cost-effective.
Conclusion
From 23 billion raw rows down to a much more manageable and discrete set of data, the latest stealer logs are now searchable via all the ways you've done for years, plus those two new domain-based stealer log APIs. We've called this breach "ALIEN TXTBASE Stealer Logs", let's see what positive outcomes we can all now produce with the data.
TL;DR — Email addresses in stealer logs can now be queried in HIBP to discover which websites they've had credentials exposed against. Individuals can see this by verifying their address using the notification service and organisations monitoring domains can pull a list back via a new API.
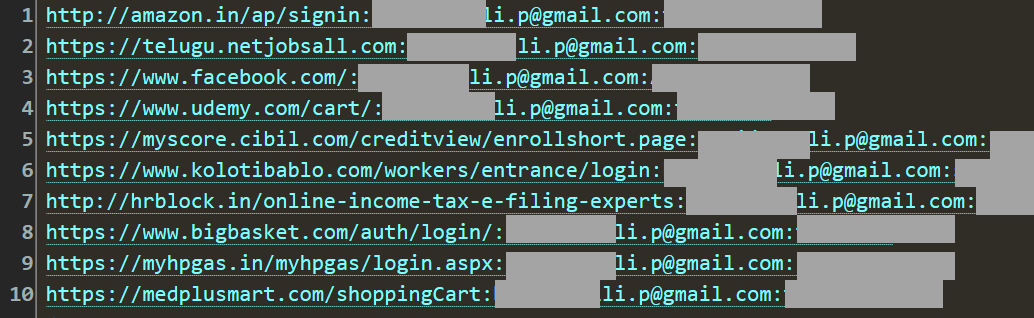
Nasty stuff, stealer logs. I've written about them and loaded them into Have I Been Pwned (HIBP) before but just as a recap, we're talking about the logs created by malware running on infected machines. You know that game cheat you downloaded? Or that crack for the pirated software product? Or the video of your colleague doing something that sounded crazy but you thought you'd better download and run that executable program showing it just to be sure? That's just a few different ways you end up with malware on your machine that then watches what you're doing and logs it, just like this:
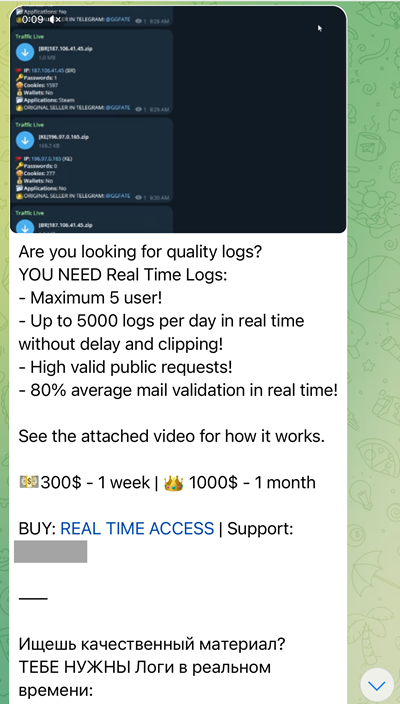
These logs all came from the same person and each time the poor bloke visited a website and logged in, the malware snared the URL, his email address and his password. It's akin to a criminal looking over his shoulder and writing down the credentials for every service he's using, except rather than it being one shoulder-surfing bad guy, it's somewhat larger than that. We're talking about billions of records of stealer logs floating around, often published via Telegram where they're easily accessible to the masses. Check out Bitsight's piece titled Exfiltration over Telegram Bots: Skidding Infostealer Logs if you'd like to get into the weeds of how and why this happens. Or, for a really quick snapshot, here's an example that popped up on Telegram as I was writing this post:
As it relates to HIBP, stealer logs have always presented a bit of a paradox: they contain huge troves of personal information that by any reasonable measure constitute a data breach that victims would like to know about, but then what can they actually do about it? What are the websites listed against their email address? And what password was used? Reading the comments from the blog post in the first para, you can sense the frustration; people want more info and merely saying "your email address appeared in stealer logs" has left many feeling more frustrated than informed. I've been giving that a lot of thought over recent months and today, we're going to take a big step towards addressing that concern:
The domains an email address appears next to in stealer logs can now be returned to authorised users.
This means the guy with the Gmail address from the screen grab above can now see that his address has appeared against Amazon, Facebook and H&R Block. Further, his password is also searchable in Pwned Passwords so every piece of info we have from the stealer log is now accessible to him. Let me explain the mechanics of this:
Firstly, the volumes of data we're talking about are immense. In the case of the most recent corpus of data I was sent, there are hundreds of text files with well over 100GB of data and billions of rows. Filtering it all down, we ended up with 220 million unique rows of email address and domain pairs covering 69 million of the total 71 million email addresses in the data. The gap is explained by a combination of email addresses that appeared against invalidly formed domains and in some cases, addresses that only appeared with a password and not a domain. Criminals aren't exactly renowned for dumping perfectly formed data sets we can seamlessly work with, and I hope folks that fall into that few percent gap understand this limitation.
So, we now have 220 million records of email addresses against domains, how do we surface that information? Keeping in mind that "experimental" caveat in the title, the first decision we made is that it should only be accessible to the following parties:
The person who owns the email address
The company that owns the domain the email address is on
At face value it might look like that first point deviates from the current model of just entering an email address on the front page of the site and getting back a result (and there are very good reasons why the service works this way). There are some important differences though, the first of which is that whilst your classic email address search on HIBP returns verified breaches of specific services, stealer logs contain a list of services that have never have been breached. It means we're talking about much larger numbers that build up far richer profiles; instead of a few breached services someone used, we're talking about potentially hundreds of them. Secondly, many of the services that appear next to email addresses in the stealer logs are precisely the sort of thing we flag as sensitive and hide from public view. There's a heap of Pornhub. There are health-related services. Religious one. Political websites. There are a lot of services there that merely by association constitute sensitive information, and we just don't want to take the risk of showing that info to the masses.
The second point means that companies doing domain searches (for which they already need to prove control of the domain), can pull back the list of the websites people in their organisation have email addresses next to. When the company controls the domain, they also control the email addresses on that domain and by extension, have the technical ability to view messages sent to their mailbox. Whether they have policies prohibiting this is a different story but remember, your work email address is your work's email address! They can already see the services sending emails to their people, and in the case of stealer logs, this is likely to be enormously useful information as it relates to protecting the organisation. I ran a few big names through the data, and even I was shocked at the prevalence of corporate email addresses against services you wouldn't expect to be used in the workplace (then again, using the corp email address in places you definitely shouldn't be isn't exactly anything new). That in itself is an issue, then there's the question of whether these logs came from an infected corporate machine or from someone entering their work email address into their personal device.
I started thinking more about what you can learn about an organisation's exposure in these logs, so I grabbed a well-known brand in the Fortune 500. Here are some of the highlights:
2,850 unique corporate email addresses in the stealer logs
3,159 instances of an address against a service they use, accompanied by a password (some email addresses appeared multiple times)
The top domains included paypal.com, netflix.com, amazon.com and facebook.com (likely within the scope of acceptable corporate use)
The top domains also included steamcommunity.com, roblox.com and battle.net (all gaming websites likely not within scope of acceptable use)
Dozens of domains containing the words "porn", "adult" or "xxx" (definitely not within scope!)
Dozens more domains containing the corporate brand, either as subdomains of their primary domain or org-specific subdomains of other services including Udemy (online learning), Amplify ("strategy execution platform"), Microsoft Azure (the same cloud platform that HIBP runs on) and Salesforce (needs no introduction)
That said, let me emphasise a critical point:
This data is prepared and sold by criminals who provide zero guarantees as to its accuracy. The only guarantee is that the presence of an email address next to a domain is precisely what's in the stealer log; the owner of the address may never have actually visited the indicated website.
Stealer logs are not like typical data breaches where it's a discrete incident leading to the dumping of customers of a specific service. I know that the presence of my personal email address in the LinkedIn and Dropbox data breaches, for example, is a near-ironclad indication that those services exposed my data. Stealer logs don't provide that guarantee, so please understand this when reviewing the data.
The way we've decided to implement these two use cases differs:
Individuals who can verify they control their email address can use the free notification service. This is already how people can view sensitive data breaches against their address.
Organisations monitoring domains can call a new API by email address. They'll need to have verified control of the domain the address is on and have an appropriately sized subscription (essentially what's already required to search the domain).
Because of the recirculation of many stealer logs, we're not tracking which domains appeared against which breaches in HIBP. Depending on how this experiment with stealer logs goes, we'll likely add more in the future (and fill in the domain data for existing stealer logs in HIBP), but additional domains will only appear in the screen above if they haven't already been seen.
We've done the searches by domain owners via API as we're talking about potentially huge volumes of data that really don't scale well to the browser experience. Imagine a company with tens or hundreds of thousands of breached addresses and then a whole heap of those addresses have a bunch of stealer log entries against them. Further, by putting this behind a per-email address API rather than automatically showing it on domain search means it's easy for an org to not see these results, which I suspect some will elect to do for privacy reasons. The API approach was easiest while we explore this service then we can build on that based on feedback. I mentioned this was experimental, right? For now, it looks like this:
Lastly, there's another opportunity altogether that loading stealer logs in this fashion opens up, and the penny dropped when I loaded that last one mentioned earlier. I was contacted by a couple of different organisations that explained how around the time the data I'd loaded was circulating, they were seeing an uptick in account takeovers "and the attackers were getting the password right first go every time!" Using HIBP to try and understand where impacted customers might have been exposed, they posited that it was possible the same stealer logs I had were being used by criminals to extract every account that had logged onto their service. So, we started delving into the data and sure enough, all the other email addresses against their domain aligned with customers who were suffering from account takeover. We now have that data in HIBP, and it would be technically feasible to provide this to domain owners so that they can get an early heads up on which of their customers they probably have to rotate credentials for. I love the idea as it's a great preventative measure, perhaps that will be our next experiment.
I thought that doing more than 10 billion requests a month was cool, but look at that data transfer - more than a quarter of a petabyte just last month! And it's in use at some pretty big name sites as well:
That's just where the API is implemented client-side, and we can identify the source of the requests via the referrer header. Most implementations are done server-side, and by design, we have absolutely no idea who those folks are. Shoutout to Cloudflare while we're here for continuing to provide the service behind this for free to help make a more secure web.
In terms of the passwords in this latest stealer log corpus, we found 167 million unique ones of which only 61 million were already in HIBP. That's a massive number, so we did some checks, and whilst there's always a bit of junk in these data sets (remember - criminals and formatting!) there's also a heap of new stuff. For example:
Tryingtogetkangaroo
Kangaroolover69
fuckkangaroos
And about 106M other non-kangaroo themed passwords. Admittedly, we did start to get a bit preoccupied looking at some of the creative ways people were creating previously unseen passwords:
passwordtoavoidpwned13
verygoodpassword
AVerryGoodPasswordThatNooneCanGuess2.0
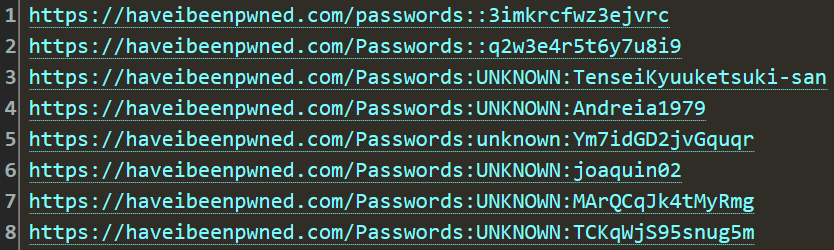
And here's something especially ironic: check out these stealer log entries:
People have been checking these passwords on HIBP's service whilst infected with malware that logged the search! None of those passwords were in HIBP... but they all are now 🙂
Want to see something equally ironic? People using my Hack Yourself First website to learn about secure coding practices have also been infected with malware and ended up in stealer logs:
So, that's the experiment we're trying with stealer logs, and that's how to see the websites exposed against an email address. Just one final comment as it comes up every single time we load data like this:
We cannot manually provide data on a per-individual basis.
Hopefully, there's less need to now given the new feature outlined above, and I hope the massive burden of looking up individual records when there are 71 million people impacted is evident. Do leave your comments below and help us improve this feature to become as useful as we can possibly make it.
Nearly four years ago now, I set out to write a book with Charlotte and RobIt was the stories behind the stories, the things that drove me to write my most important blog posts, and then the things that happened afterwards. It's almost like a collection of meta posts, each one adding behind-the-scenes commentary that most people reading my material didn't know about at the time.
It was a strange time for all of us back then. I didn't leave the country for the first time in over a decade. I barely even left the state. I had time to toil on the passion project that became this book. As I wrote about years later, there were also other things occupying my mind at the time. Writing this book was cathartic, providing me the opportunity to express some of the emotions I was feeling at the time and to reflect on life.
Speaking of reflecting, this week was Have I Been Pwned's 11th birthday. Reaching this milestone, getting back to travel (I'm writing this poolside with a beer at a beautiful hotel in Dubai), life settling down (while sitting next to my amazing wife), and it now being 2 years since we launched the book, I decided we should just give it away for free. I mean really free, not "give me all your personal details, then here's a download link" I mean, here are the direct download links:
I hope you enjoy the book. It's the culmination of so many things I worked so hard to create over the preceding decade and a half, and I'm really happy to just be giving it away now. Enjoy the book 😊
The response from each search was coming back so quickly that the user wasn’t sure if it was legitimately checking subsequent addresses they entered or if there was a glitch.
And now, the pièce de résistance, the coolest performance thing we've done to date (and it is now "we", thank you Stefán): just caching the whole lot at Cloudflare. Everything. Every search you do... almost. Let me explain, firstly by way of some background:
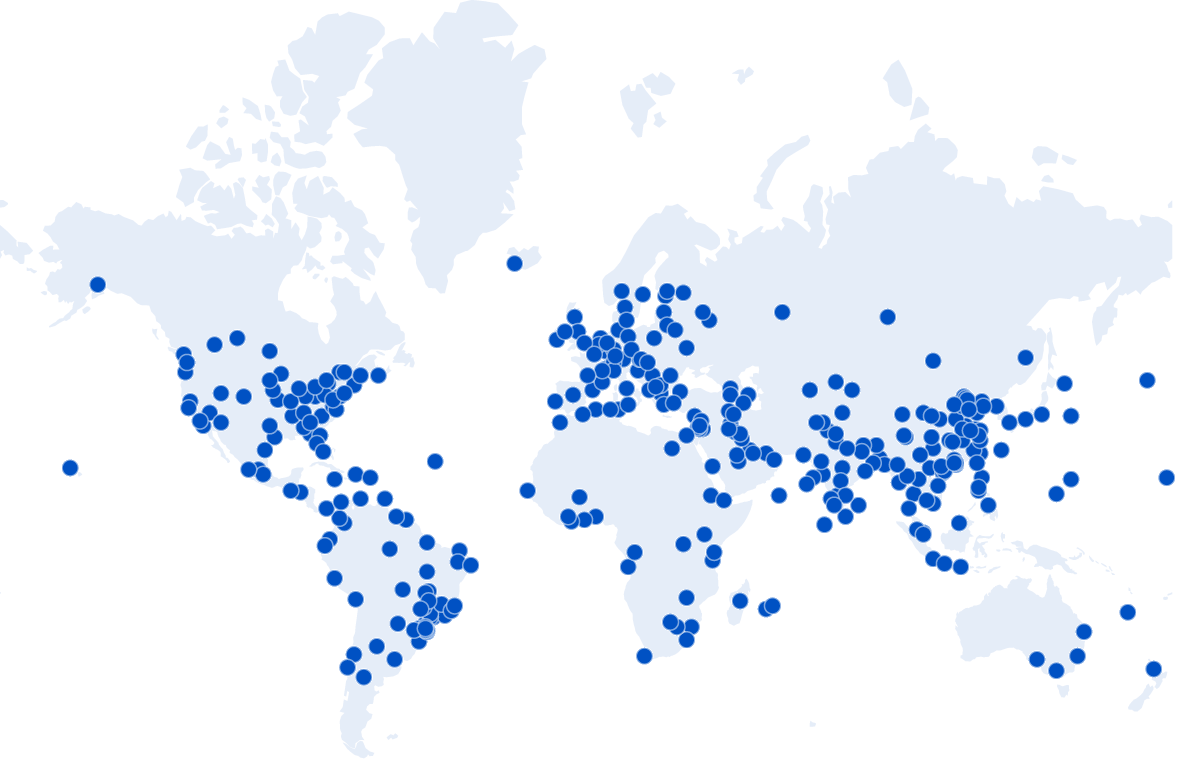
When you hit any of the services on HIBP, the first place the traffic goes from your browser is to one of Cloudflare's 330 "edge nodes":
As I sit here writing this on the Gold Coast on Australia's most eastern seaboard, any request I make to HIBP hits that edge node on the far right of the Aussie continent which is just up the road in Brisbane. The capital city of our great state of Queensland is just a short jet ski away, about 80km as the crow flies. Before now, every single time I searched HIBP from home, my request bytes would travel up the wire to Brisbane and then take a giant 12,000km trip to Seattle where the Azure Function in the West US Azure data would query the database before sending the response 12,000km back west to Cloudflare's edge node, then the final 80km down to my Surfers Paradise home. But what if it didn't have to be that way? What if that data was already sitting on the Cloudflare edge node in Brisbane? And the one in Paris, and the one in well, I'm not even sure where all those blue dots are, but what if it was everywhere? Several awesome things would happen:
You'd get your response much faster as we've just shaved off more than 99% of the distance the bytes need to travel.
The availability would massively improve as there are far fewer nodes for the traffic to traverse through, plus when a response is cached, we're no longer dependent on the Azure Function or underlying storage mechanism.
We'd save on Azure Function execution costs, storage account hits and especially egress bandwidth (which is very expensive).
In short, pushing data and processing "closer to the edge" benefits both our customers and ourselves. But how do you do that for 5 billion unique email addresses? (Note: As of today, HIBP reports over 14 billion breached accounts, the number of unique email addresses is lower as on average, each breached address has appeared in multiple breaches.) To answer this question, let's recap on how the data is queried:
Via the public API. This endpoint also takes an email address as input and then returns all breaches it appears in.
Via the k-anonyity enterprise API. This endpoint is used by a handful of large subscribers such as Mozilla and 1Password. Instead of searching by email address, it implements k-anonymity and searches by hash prefix.
Let's delve into that last point further because it's the secret sauce to how this whole caching model works. In order to provide subscribers of this service with complete anonymity over the email addresses being searched for, the only data passed to the API is the first six characters of the SHA-1 hash of the full email address. If this sounds odd, read the blog post linked to in that last bullet point for full details. The important thing for now, though, is that it means there are a total of 16^6 different possible requests that can be made to the API, which is just over 16 million. Further, we can transform the first two use cases above into k-anonymity searches on the server side as it simply involved hashing the email address and taking those first six characters.
In summary, this means we can boil the entire searchable database of email addresses down to the following:
AAAAAA
AAAAAB
AAAAAC
...about 16 million other values...
FFFFFD
FFFFFE
FFFFFF
That's a large albeit finite list, and that's what we're now caching. So, here's what a search via email address looks like:
Address to search: test@example.com
Full SHA-1 hash: 567159D622FFBB50B11B0EFD307BE358624A26EE
Six char prefix: 567159
API endpoint: https://[host]/[path]/567159
If hash prefix is cached, retrieve result from there
If hash prefix is not cached, query origin and save to cache
Return result to client
K-anonymity searches obviously go straight to step four, skipping the first few steps as we already know the hash prefix. All of this happens in a Cloudflare worker, so it's "code on the edge" creating hashes, checking cache then retrieving from the origin where necessary. That code also takes care of handling parameters that transform queries, for example, filtering by domain or truncating the response. It's a beautiful, simple model that's all self-contained within a worker and a very simple origin API. But there's a catch - what happens when the data changes?
There are two events that can change cached data, one is simple and one is major:
Someone opts out of public searchability and their email address needs to be removed. That's easy, we just call an API at Cloudflare and flush a single hash prefix.
A new data breach is loaded and there are changes to a large number of hash prefixes. In this scenario, we flush the entire cache and start populating it again from scratch.
The second point is kind of frustrating as we've built up this beautiful collection of data all sitting close to the consumer where it's super fast to query, and then we nuke it all and go from scratch. The problem is it's either that or we selectively purge what could be many millions of individual hash prefixes, which you can't do:
For Zones on Enterprise plan, you may purge up to 500 URLs in one API call.
And:
Cache-Tag, host, and prefix purging each have a rate limit of 30,000 purge API calls in every 24 hour period.
We're giving all this further thought, but it's a non-trivial problem and a full cache flush is both easy and (near) instantaneous.
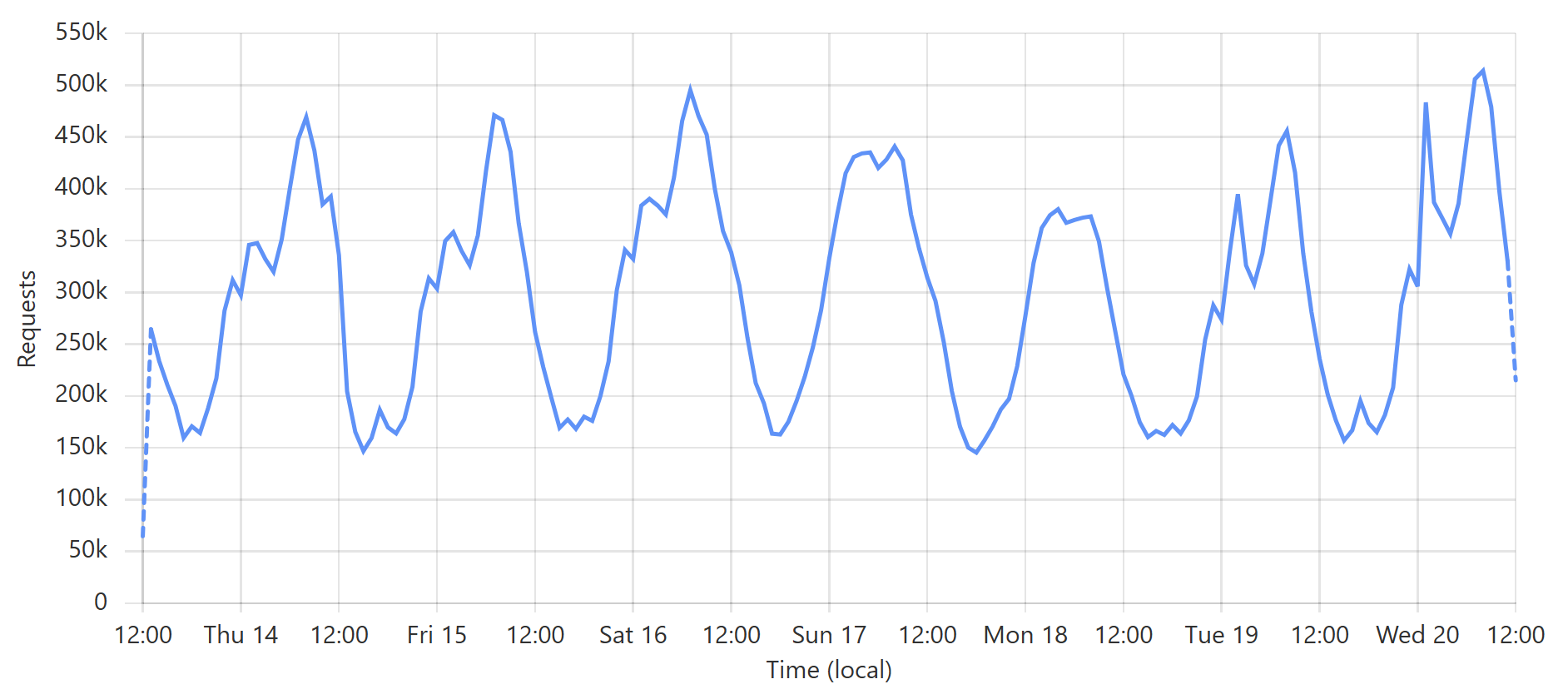
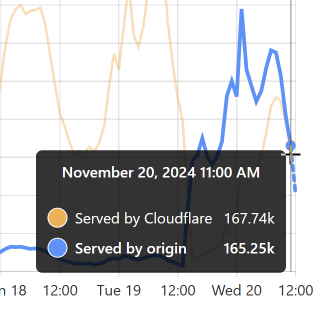
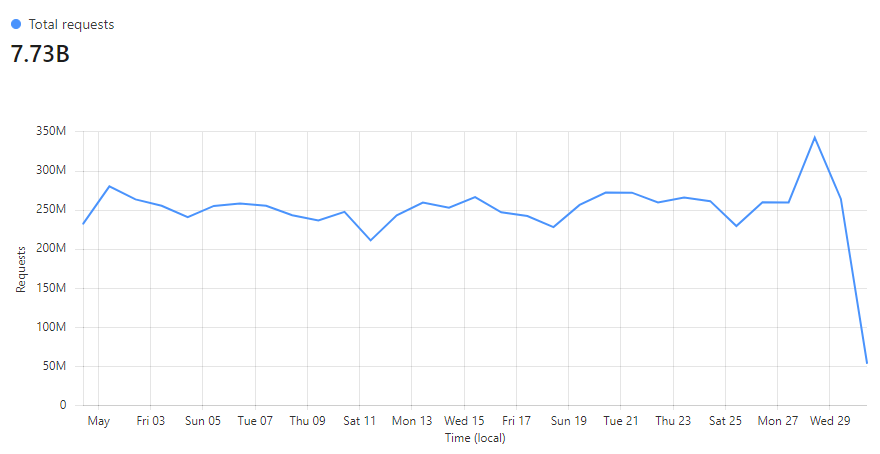
Enough words, let's get to some pictures! Here's a typical week of queries to the enterprise k-anonymity API:
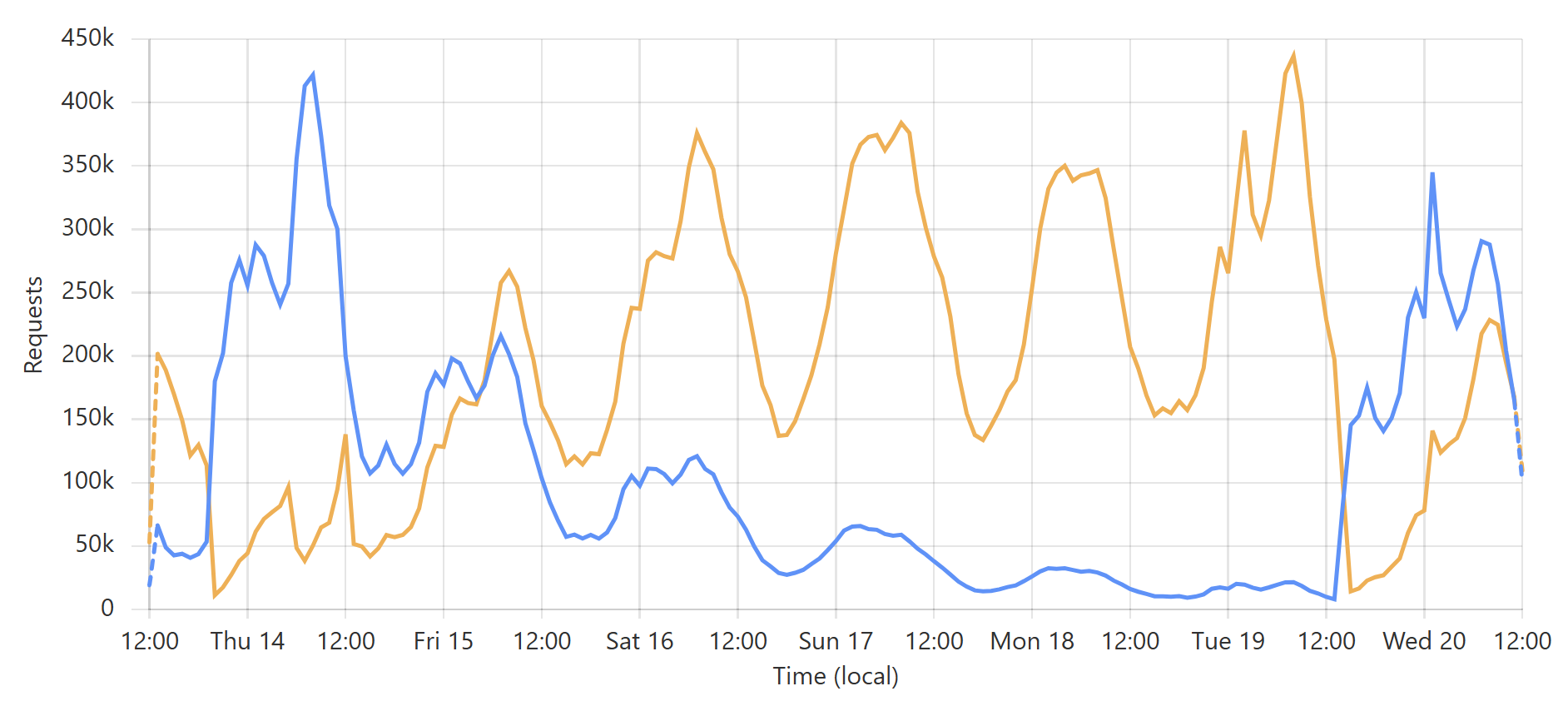
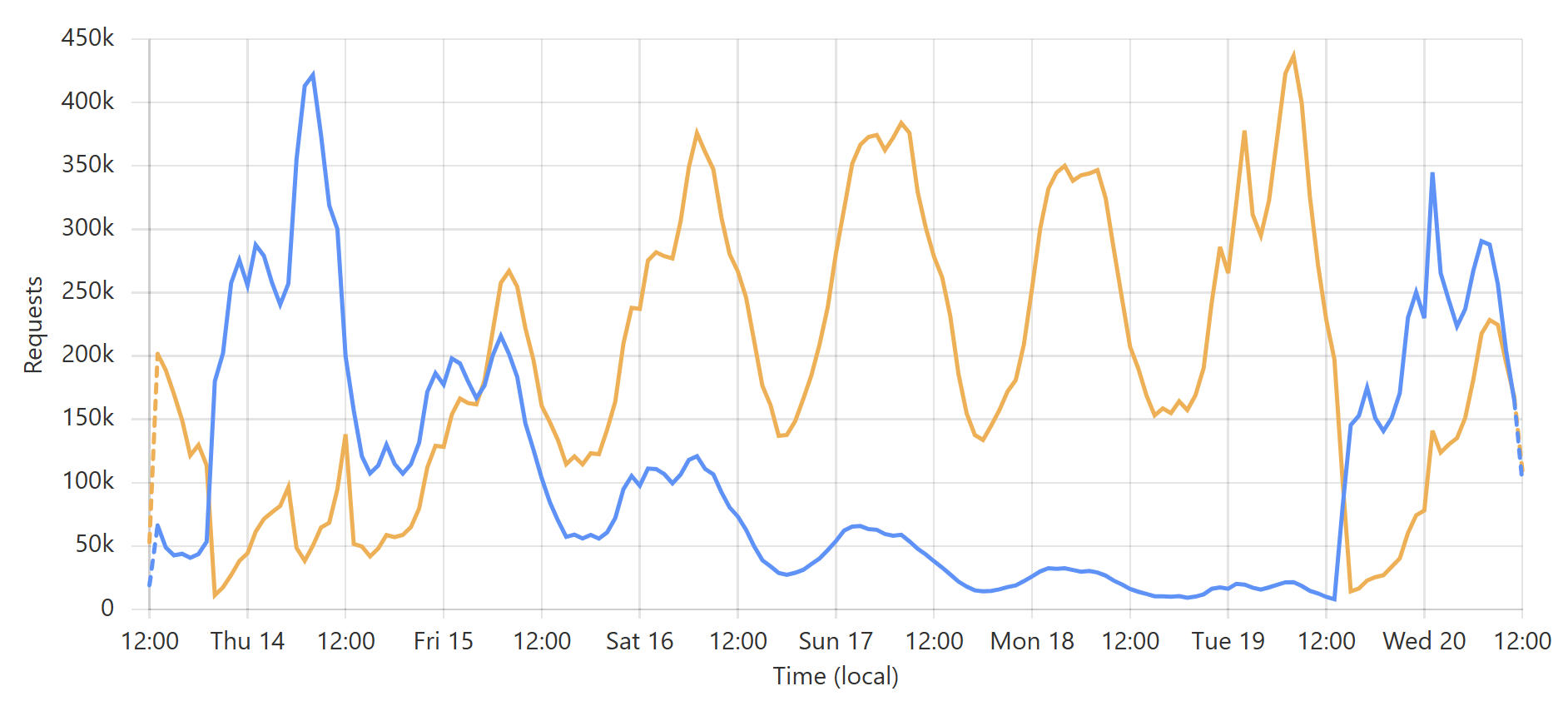
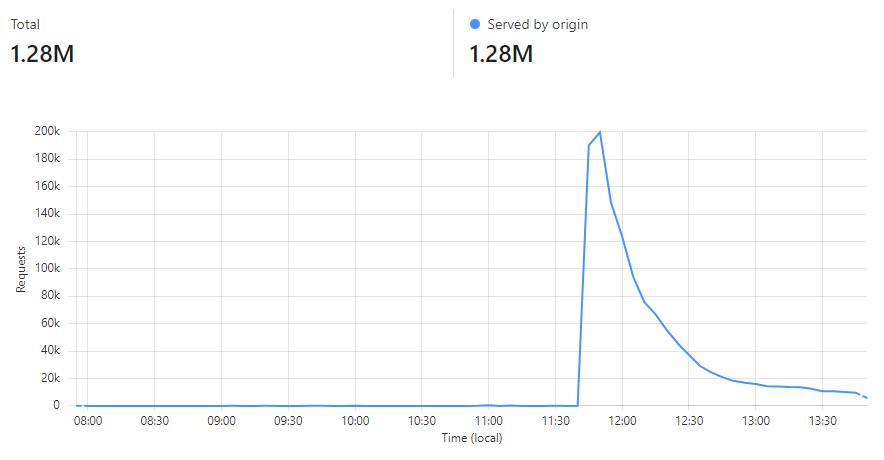
This is a very predictable pattern, largely due to one particular subscriber regularly querying their entire customer base each day. (Sidenote: most of our enterprise level subscribers use callbacks such that we push updates to them via webhook when a new breach impacts their customers.) That's the total volume of inbound requests, but the really interesting bit is the requests that hit the origin (blue) versus those served directly by Cloudflare (orange):
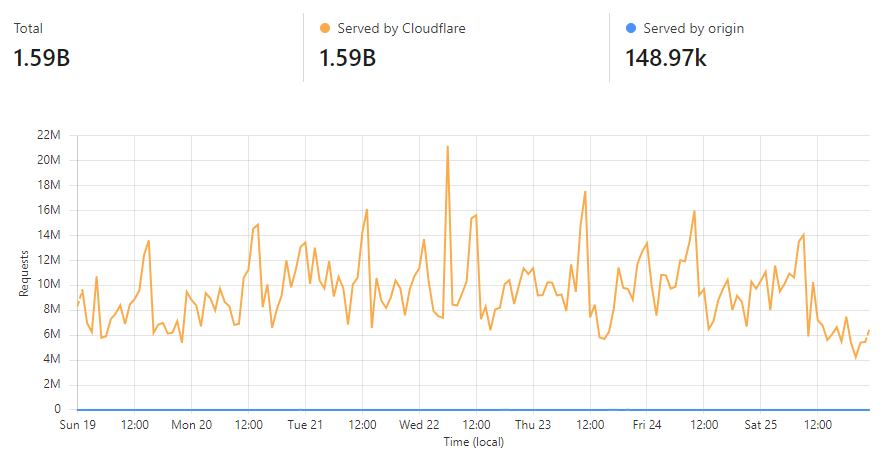
Let's take the lowest blue data point towards the end of the graph as an example:
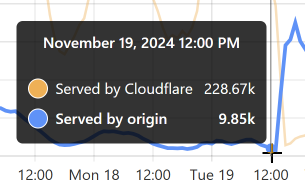
At that time, 96% of requests were served from Cloudflare's edge. Awesome! But look at it only a little bit later:
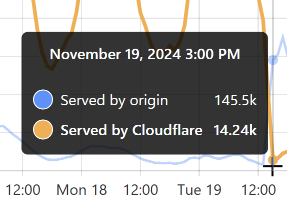
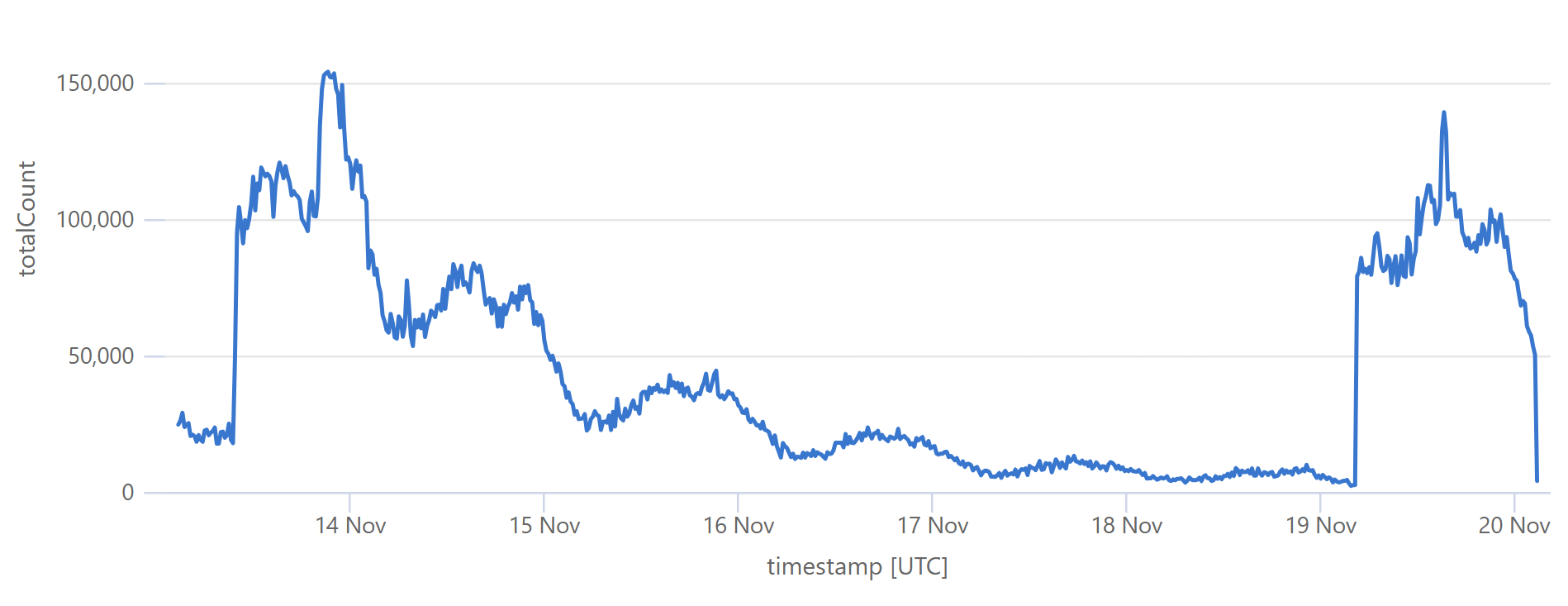
That's when I flushed cache for the Finsure breach, and 100% of traffic started being directed to the origin. (We're still seeing 14.24k hits via Cloudflare as, inevitably, some requests in that 1-hour block were to the same hash range and were served from cache.) It then took a whole 20 hours for the cache to repopulate to the extent that the hit:miss ratio returned to about 50:50:
Look back towards the start of the graph and you can see the same pattern from when I loaded the DemandScience breach. This all does pretty funky things to our origin API:
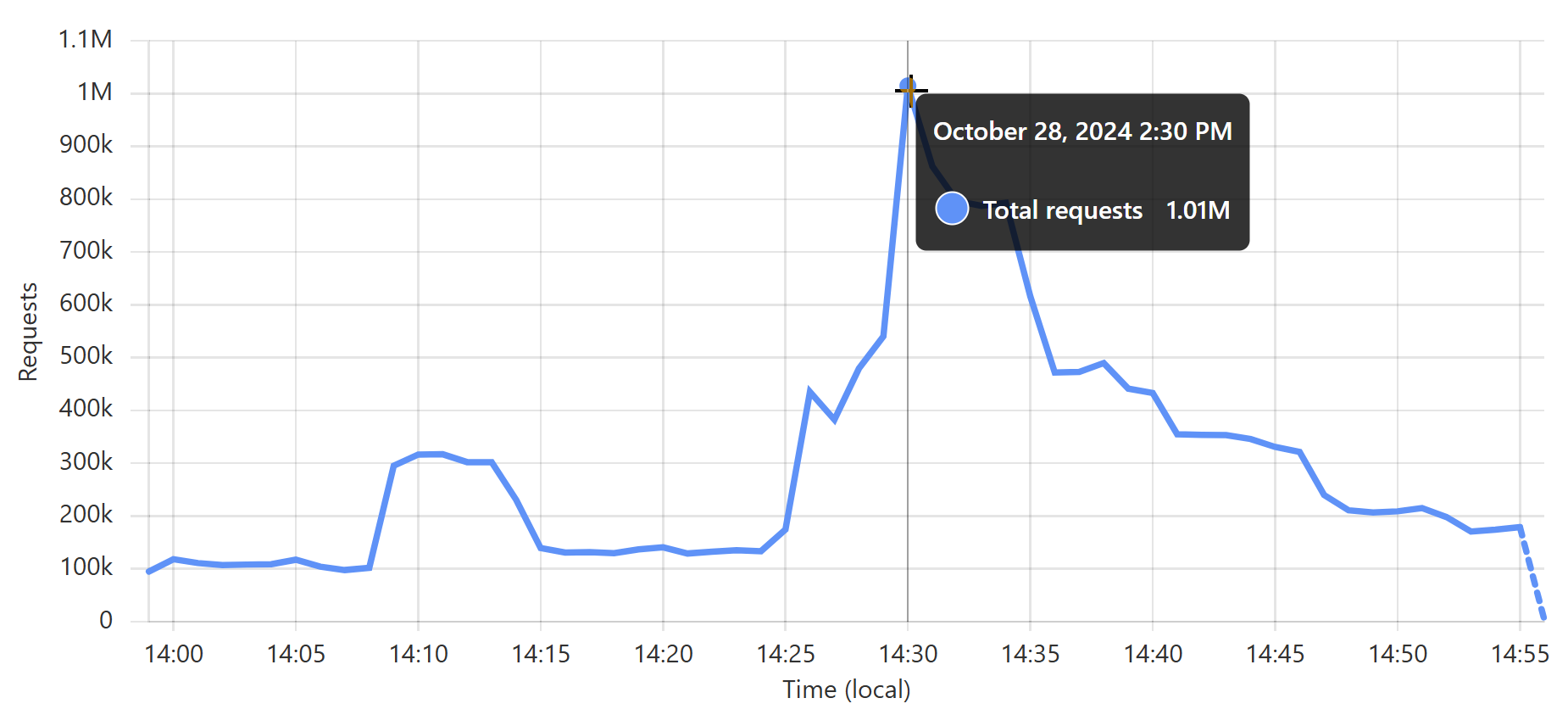
That last sudden increase is more than a 30x traffic increase in an instant! If we hadn't been careful about how we managed the origin infrastructure, we would have built a literal DDoS machine. Stefán will write later about how we manage the underlying database to ensure this doesn't happen, but even still, whilst we're dealing with the cyclical support patterns seen in that first graph above, I know that the best time to load a breach is later in the Aussie afternoon when the traffic is a third of what it is first thing in the morning. This helps smooth out the rate of requests to the origin such that by the time the traffic is ramping up, more of the content can be returned directly from Cloudflare. You can see that in the graphs above; that big peaky block towards the end of the last graph is pretty steady, even though the inbound traffic the first graph over the same period of time increases quite significantly. It's like we're trying to race the increasing inbound traffic by building ourselves up a bugger in cache.
Here's another angle to this whole thing: now more than ever, loading a data breach costs us money. For example, by the end of the graphs above, we were cruising along at a 50% cache hit ratio, which meant we were only paying for half as many of the Azure Function executions, egress bandwidth, and underlying SQL database as we would have been otherwise. Flushing cache and suddenly sending all the traffic to the origin doubles our cost. Waiting until we're back at 90% cache it ratio literally increases those costs 10x when we flush. If I were to be completely financially ruthless about it, I would need to either load fewer breaches or bulk them together such that a cache flush is only ejecting a small amount of data anyway, but clearly, that's not what I've been doing 😄
There's just one remaining fly in the ointment...
Of those three methods of querying email addresses, the first is a no-brainer: searches from the front page of the website hit a Cloudflare Worker where it validates the Turnstile token and returns a result. Easy. However, the second two models (the public and enterprise APIs) have the added burden of validating the API key against Azure API Management (APIM), and the only place that exists is in the West US origin service. What this means for those endpoints is that before we can return search results from a location that may be just a short jet ski ride away, we need to go all the way to the other side of the world to validate the key and ensure the request is within the rate limit. We do this in the lightest possible way with barely any data transiting the request to check the key, plus we do it in async with pulling the data back from the origin service if it isn't already in cache. In other words, we're as efficient as humanly possible, but we still cop a massive latency burden.
Doing API management at the origin is super frustrating, but there are really only two alternatives. The first is to distribute our APIM instance to other Azure data centres, and the problem with that is we need a Premium instance of the product. We presently run on a Basic instance, which means we're talking about a 19x increase in price just to unlock that ability. But that's just to go Premium; we then need at least one more instance somewhere else for this to make sense, which means we're talking about a 28x increase. And every region we add amplifies that even further. It's a financial non-starter.
The second option is for Cloudflare to build an API management product. This is the killer piece of this puzzle, as it would put all the checks and balances within the one edge node. It's a suggestion I've put forward on many occasions now, and who knows, maybe it's already in the works, but it's a suggestion I make out of a love of what the company does and a desire to go all-in on having them control the flow of our traffic. I did get a suggestion this week about rolling what is effectively a "poor man's API management" within workers, and it's a really cool suggestion, but it gets hard when people change plans or when we want to apply quotas to APIs rather than rate limits. So c'mon Cloudflare, let's make this happen!
Finally, just one more stat on how powerful serving content directly from the edge is: I shared this stat last month for Pwned Passwords which serves well over 99% of requests from Cloudflare's cache reserve:
There it is - we’ve now passed 10,000,000,000 requests to Pwned Password in 30 days 😮 This is made possible with @Cloudflare’s support, massively edge caching the data to make it super fast and highly available for everyone. pic.twitter.com/kw3C9gsHmB
That's about 3,900 requests per second, on average, non-stop for 30 days. It's obviously way more than that at peak; just a quick glance through the last month and it looks like about 17k requests per second in a one-minute period a few weeks ago:
But it doesn't matter how high it is, because I never even think about it. I set up the worker, I turned on cache reserve, and that's it 😎
Apparently, before a child reaches the age of 13, advertisers will have gathered more 72 million data points on them. I knew I'd seen a metric about this sometime recently, so I went looking for "7,000", which perfectly illustrates how unaware we are of the extent of data collection on all of us. I started Have I Been Pwned (HIBP) in the first place because I was surprised at where my data had turned up in breaches. 11 years and 14 billion breached records later, I'm still surprised!
Jason (not his real name) was also recently surprised at where his data had appeared. He found it in a breach of a service called "Pure Incubation", a company whose records had appeared on a popular hacking forum earlier this year:
🚨Over 183 Million Pure Incubation Ventures Records for Sale 🚨
183,754,481 records belonging to Pure Incubation Ventures (https://t.co/m3sjzAMlXN) have been put up for sale on a hacking forum for $6,000 negotiable.
When Jason found his email address and other info in this corpus, he had the same question so many others do when their data turns up in a place they've never heard of before - how? Why?! So, he asked them:
I seem to have found my email in your data breach. I am interested in finding how my information ended up in your database.
To their credit, he got a very comprehensive answer, which I've included below:
Well, that answers the "how" part of the equation; they've aggregated data from public sources. And the "why" part? It's the old "data is the new oil" analogy that recognises how valuable our info is, and as such, there's a market for it. There are lots of terms used to describe what DemandScience does, including "B2B demand generation", "buyer intelligence solutions provider", "empowering technology companies to accelerate ROI", "supercharging pipelines" and "account intelligence". Or, to put it in a more lay-person-friendly fashion, they sell data on people.
DemandScience is what we refer to as a "data aggregator" in that they combine identity data from multiple locations, bundle it up, and then sell it. Occasionally, data aggregators end up having sizeable data breaches; before today, HIBP already contained Adapt (9M records), Data & Leads (44M records), Exactis (132M records), Factual (2M records), and You've Been Scraped (66M records). According to DemandScience, "none of our current operational systems were exploited", yet simultaneously, "the leaked data originated from a system that has been decommissioned". So, it's a breach of an old system.
Does it matter? I mean, if it's just public data, should people care? Jason cared, at least enough to make the original enquiry and for DemandScience to look him up and realise he's not in their current database. Still, he existed in the breached one (I later sent Jason his record from the breach, and he confirmed the accuracy). As I often do in these cases, I reached out to a bunch of recent HIBP subscribers in the breach and asked them three simple questions:
Is the data about you accurate and if not, which bits are wrong?
Is this data you would consider to be in the public domain already?
Would you expect to be notified about your data being used in this fashion, and consequently appearing a breach?
The answers were all the same: the data is accurate, it's already in the public domain, and people aren't too concerned about it appearing in this breach. Well that was easy 🙂 However...
There are two nuances that aren't captured here, and the first one is that this is valuable data, that's why DemandScience sells it! It comes back to that "new oil" analogy and if you have enough of it, you can charge good money for it. Companies typically use data such as this to do precisely the sort of catchphrasey stuff the company talks about, primarily around maximising revenue from their customers by understanding them better.
The second nuance is that whilst this data may already be in the public domain, did the owners of it expect it to be used in this fashion? For example, if you publish your details in a business directory, is your expectation that this info may then be sold to other companies to help them upsell you on their products? Probably not. And if, like many of the records in the data, someone's row is accompanied by their LinkedIn profile, would they expect that data to matched and sold? I suggest the responses would likely be split here, and that in itself is an important observation: how we view the sensitivity of our data and the impact of it being exposed (whether personal or business) is extremely personal. Some people take the view of "I have nothing to hide", whilst others become irate if even just their email address is exposed.
Whilst considering how to add more insights to this blog post, I thought I'd do a quick check on just one more email address:
"54543060",,"0","TROY","HUNT","PO BOX 57",,"WEST RYDE",,,"AU","61298503333",,,,"troy.hunt@pfizer.com","pfizer.com","PFIZER INC",,"250-499","$50 - 99 Million","Healthcare, Pharmaceuticals and Biotech","VICE PRESIDENT OF INFORMATION TECHNOLOGY","VP Level","2834",,"Senior Management (SVP/GM/Director)","IT",,"1","GemsTarget INTL","GEMSTARGET_INTL_648K_10.17.18",,,,,,,,,"18/10/2018 05:12:39","5/10/2021 16:47:56","PFIZER.COM",,,,,"IT Management General","Information Technology"
I'll be entirely transparent and honest here - my exact words after finding this were "motherfucker!" True story, told uncensored here because I want to impress on the audience how I feel when my data turns up somewhere publicly. And I do feel like it's "my" data; it's certainly my name and even though it's my old Pfizer email address I've not used for almost a decade now, that also has my name in it. My job title is also there... and it's completely wrong! I never had a VP-level role, even though the other data around my tech role is at least in the vicinity of being correct. But other than the initial shock of finding myself in yet another data breach, personally, I'm in the same boat as the HIBP subscribers I contacted, and this doesn't bother me too much. But I also agree with the following responses I received to my third question:
I think it is useful to be notified of such breaches, even if it is just to confirm no sensitive data has been compromised. As I said, our IT department recently notified me that some of my data was leaked and a pre-emptive password reset was enforced as they didn't know what was leaked.
It would be good to see it as an informational notification in case there's an increase in attack attempts against my email address.
I would like to opt-out of here to reduce the SPAM and Phishing emails.
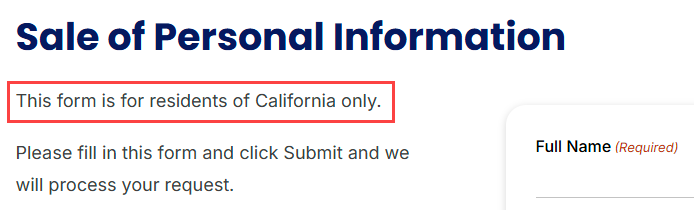
That last one seems perfectly reasonable, and fortunately, DemandScience does have a link on their website to Do Not Sell My Information:
Dammit! If, like me, you're part of the 99.5% of the world that doesn't live in California, then apparently this form isn't for you. However, they do list dataprivacy@demandscience.com on that page, which is the same address Jason was communicating with above. Chances are, if you want to remove your data then that's where to start.
There were almost 122M unique email addresses in this corpus and those have now been added to HIBP. Treat this as informational; I suspect that for most people, it won't bother them, whilst others will ask for their data not to be sold (regardless of where they live in the world). But in all likelihood, there will be more than a handful of domain subscribers who take issue with that volume of people data sitting there in one corpus easily downloadable via a clear web hacking forum. For example, mine was just one of many tens of thousands of Pfizer email addresses, and that sort of thing is going to raise the ire of some folks in corporate infosec capacities.
One last comment: there was a story published earlier this year titled Our Investigation of the Pure Incubation Ventures Leak and in there they refer to "encrypted passwords" being present in the data. Many of the files do contain a column with bcrypt hashes (which is definitely not encryption), but given the way in which this data was collated, I can see no evidence whatsoever that these are password hashes. As such, I haven't listed "Passwords" as one of the compromised data classes in HIBP and you find yourself in this breach, I wouldn't be at all worried about this.
The conundrum I refer to in the title of this post is the one faced by a breached organisation: disclose or suppress? And let me be even more specific: should they disclose to impacted individuals, or simply never let them know? I'm writing this after many recent such discussions with breached organisations where I've found myself wishing I had this blog post to point them to, so, here it is.
Let's start with tackling what is often a fundamental misunderstanding about disclosure obligations, and that is the legal necessity to disclose. Now, as soon as we start talking about legal things, we run into the problem of it being different all over the world, so I'll pick a few examples to illustrate the point. As it relates to the UK GDPR, there are two essential concepts to understand, and they're the first two bulleted items in their personal data breaches guide:
The UK GDPR introduces a duty on all organisations to report certain personal data breaches to the relevant supervisory authority. You must do this within 72 hours of becoming aware of the breach, where feasible.
If the breach is likely to result in a high risk of adversely affecting individuals’ rights and freedoms, you must also inform those individuals without undue delay.
On the first point, "certain" data breaches must be reported to "the relevant supervisory authority" within 72 hours of learning about it. When we talk about disclosure, often (not just under GDPR), that term refers to the responsibility to report it to the regulator, not the individuals. And even then, read down a bit, and you'll see the carveout of the incident needing to expose personal data that is likely to present a "risk to people’s rights and freedoms".
This brings me to the second point that has this massive carveout as it relates to disclosing to the individuals, namely that the breach has to present "a high risk of adversely affecting individuals’ rights and freedoms". We have a similar carveout in Australia where the obligation to report to individuals is predicated on the likelihood of causing "serious harm".
This leaves us with the fact that in many data breach cases, organisations may decide they don't need to notify individuals whose personal information they've inadvertently disclosed. Let me give you an example from smack bang in the middle of GDPR territory: Deezer, the French streaming media service that went into HIBP early January last year:
New breach: Deezer had 229M unique email addresses breached from a 2019 backup and shared online in late 2022. Data included names, IPs, DoBs, genders and customer location. 49% were already in @haveibeenpwned. Read more: https://t.co/1ngqDNYf6k
229M records is a substantial incident, and there's no argument about the personally identifiable nature of attributes such as email address, name, IP address, and date of birth. However, at least initially (more on that soon), Deezer chose not to disclose to impacted individuals:
Chatting to @Scott_Helme, he never received a breach notification from them. They disclosed publicly via an announcement in November, did they never actually email impacted individuals? Did *anyone* who got an HIBP email get a notification from Deezer? https://t.co/dnRw8tkgLlhttps://t.co/jKvmhVCwlM
Yes, same situation. I got the breach notification from HaveIBeenPwned, I emailed customer service to get an export of my data, got this message in response: pic.twitter.com/w4maPwX0Qe
This situation understandably upset many people, with many cries of "but GDPR!" quickly following. And they did know way before I loaded it into HIBP too, almost two months earlier, in fact (courtesy of archive.org):
This information came to light November 8 2022 as a result of our ongoing efforts to ensure the security and integrity of our users’ personal information
Deezer has not violated any data protection regulations
And based on the carveouts discussed earlier, I can see how they drew that conclusion. Was the disclosed data likely to lead to "a high risk of adversely affecting individuals’ rights and freedoms"? You can imagine lawyers arguing that it wouldn't. Regardless, people were pissed, and if you read through those respective Twitter threads, you'll get a good sense of the public reaction to their handling of the incident. HIBP sent 445k notifications to our own individual subscribers and another 39k to those monitoring domains with email addresses in the breach, and if I were to hazard a guess, that may have been what led to this:
Is this *finally* the @Deezer disclosure notice to individuals, a month and a half later? It doesn’t look like a new incident to me, anyone else get this? https://t.co/RrWlczItLm
So, they know about the breach in Nov, and they told people in Feb. It took them a quarter of a year to tell their customers they'd been breached, and if my understanding of their position and the regulations they were adhering to is correct, they never needed to send the notice at all.
I appreciate that's a very long-winded introduction to this post, but it sets the scene and illustrates the conundrum perfectly: an organisation may not need to disclose to individuals, but if they don't, they risk a backlash that may eventually force their hand.
In my past dealing with organisations that were reticent to disclose to their customers, their positions were often that the data was relatively benign. Email addresses, names, and some other identifiers of minimal consequence. It's often clear that the organisation is leaning towards the "uh, maybe we just don't say anything" angle, and if it's not already obvious, that's not a position I'd encourage. Let's go through all the reasons:
Whose Data is it Anyway?
I ask this question because the defence I've often heard from organisations choosing the non-disclosure path is that the data is theirs - the company's. I have a fundamental issue with this, and it's not one with any legal basis (but I can imagine it being argued by lawyers in favour of that position), rather the commonsense position that someone's email address, for example, is theirs. If my email address appears in a data breach, then that's my email address and I entrusted the organisation in question to look after it. Whether there's a legal basis for the argument or not, the assertion that personally identifiable attributes become the property of another party will buy you absolutely no favours with the individual who provided them to you when you don't let them know you've leaked it.
The Determination of Rights, Freedoms, and Serious Harm
Picking those terms from earlier on, if my gender, sexuality, ethnicity, and, in my case, even my entire medical history were to be made public, I would suffer no serious harm. You'd learn nothing of any consequence that you don't already know about me, and personally, I would not feel that I suffered as a result. However...
For some people, simply the association of their email address to their name may have a tangible impact on their life, and using the term from above jeopardises their rights and freedoms. Some people choose to keep their IRL identities completely detached from their email address, only providing the two together to a handful of trusted parties. If you're handling a data breach for your organisation, do you know if any of your impacted customers are in that boat? No, of course not; how could you?
Further, let's imagine there is nothing more than email addresses and passwords exposed on a cat forum. Is that likely to cause harm to people? Well, it's just cats; how bad could it be? Now, ask that question - how bad could it be? - with the prevalence of password reuse in mind. This isn't just a cat forum; it is a repository of credentials that will unlock social media, email, and financial services. Of course, it's not the fault of the breached service that people reuse their passwords, but their breach could lead to serious harm via the compromise of accounts on totally unrelated services.
Let's make it even more benign: what if it's just email addresses? Nothing else, just addresses and, of course, the association to the breached service. Firstly, the victims of that breach may not want their association with the service to be publicly known. Granted, there's a spectrum and weaponising someone's presence in Ashley Madison is a very different story from pointing out that they're a LinkedIn user. But conversely, the association is enormously useful phishing material; it helps scammers build a more convincing narrative when they can construct their messages by repeating accurate facts about their victim: "Hey, it's Acme Corp here, we know you're a loyal user, and we'd like to make you a special offer". You get the idea.
Who is Non-disclosure Actually Protecting?
I'll start this one in the complete opposite direction to what it sounds like it should be because this is what I've previously heard from breached organisations:
We don't want to disclose in order to protect our customers
Uh, you sure about that? And yes, you did read that paraphrasing correctly. In fact, here's a copy paste from a recent discussion about disclosure where there was an argument against any public discussion of the incident:
Our concern is that your public notification would direct bad actors to search for the file, which can potentially do harm to both the business and our mutual users.
The fundamental issue of this clearly being an attempt to suppress news of the incident aside, in this particular case, the data was already on a popular clear web hacking forum, and the incident has appeared in multiple tweets viewed by thousands of people. The argument makes no sense whatsoever; the bad guys - lots of them - already have the data. And the good guys (the customers) don't know about it.
I'll quote precisely from another company who took a similar approach around non-disclosure:
[company name] is taking steps to notify regulators and data subjects where it is legally required to do so, based on advice from external legal counsel.
By now, I don't think I need to emphasise the caveat that they inevitably relied on to suppress the incident, but just to be clear: "where it is legally required to do so". I can say with a very high degree of confidence that they never notified the 8-figure number of customers exposed in this incident because they didn't have to. (I hear about it pretty quickly when disclosure notices are sent out, and I regularly share these via my X feed).
Non-disclosure is intended to protect the brand and by extension, the shareholders, not the customers.
Non-Disclosure Creates a Vacuum That Will be Filled by Others
Usually, after being sent a data breach, the first thing I do is search for "[company name] data breach". Often, the only results I get are for a listing on a popular hacking forum (again, on the clear web) where their data was made available for download, complete with a description of the incident. Often, that description is wrong (turns out hackers like to embellish their accomplishments). Incorrect conclusions are drawn and publicised, and they're the ones people find when searching for the incident.
When a company doesn't have a public position on a breach, the vacuum it creates is filled by others. Obviously, those with nefarious intent, but also by journalists, and many of those don't have the facts right either. Public disclosure allows the breached organisation to set the narrative, assuming they're forthcoming and transparent and don't water it down such that there's no substance in the disclosure, of course.
The Truth is in the Data, and it Will be Set Free
All the way back in 2017, I wrote about The 5 Stages of Data Breach Grief as I watched The AA in the UK dig themselves into an ever-deepening hole. They were doubling down on bullshit, and there was simply no way the truth wasn't going to come out. It was such a predictable pattern that, just like with Kübler-Ross' stages of personal grief, it was very clear how this was going to play out.
If you choose not to disclose a breach - for whatever reason - how long will it be until your "truth" comes out? Tomorrow? Next month? Years from now?! You'll be looking over your shoulder until it happens, and if it does one day go public, how will you be judged? Which brings me to the next point:
This is going to feel like I'm talking to my kids after they've done something wrong, but here goes anyway: If people entrusted you with your data and you "lost" it (had it disclosed to unauthorised parties), the only decent thing to do is own up and acknowledge it. It doesn't matter if it was your organisation directly or, as with the Deezer situation, a third party you entrusted with the data; you are the coalface to your customers, and you're the one who is accountable for their data.
But the real people who feel pain here are Australians when their information that they gave in good faith to that company is breached in a cyber incident, and the focus is not on those customers from the very first moment. The people whose data has been stolen are the real victims here. And if you focus on them and put their interests first every single day, you will get good outcomes. Your customers and your clients will be respectful of it, and the Australian government will applaud you for it.
I'm presently on a whirlwind North America tour, visiting government and law enforcement agencies to understand more about their challenges and where we can assist with HIBP. As I spend more time with these agencies around the world, I keep hearing that data breach victim notification is an essential piece of the cybersecurity story, and I'm making damn sure to highlight the deficiencies I've written about here. We're going to keep pushing for all data breach victims to be notified when their data is exposed, and my hope in writing this is that when it's read in future by other organisations I've disclosed to, they respect their customers and disclose promptly. Check out Data breach disclosure 101: How to succeed after you've failed for guidance and how to do this.
TL;DR — Tens of millions of credentials obtained from info stealer logs populated by malware were posted to Telegram channels last month and used to shake down companies for bug bounties under the misrepresentation the data originated from their service.
How many attempted scams do you get each day? I woke up to yet another "redeem your points" SMS this morning, I'll probably receive a phone call from "my bank" today (edit: I was close, it was "Amazon Prime" 🤷♂️) and don't even get me started on my inbox. We're bombarded to the point of desensitisation, which itself is dangerous because it creates the risk of inadvertently dismissing something that really does require your attention. Which brings me to the email Scott Helme from Report URI (disclosure: a service I've long partnered with and advised) received yesterday titled "Bug bounty Program - PII leak Credentials more than 170". It began as follows:
Through open-source intelligence gathering, I discovered a significant amount of "report-uri.com" user credentials and sensitive documents have been leaked and are publicly accessible.
The sender then attached a text file with 197 lines of email addresses and passwords belonging to users of Scott's pride and joy. The first lines looked like this (url:email:password):
The impact of this vulnerability is severe, potentially resulting in: Mass account takeovers by malicious actors. Exposure of sensitive user data including names, emails, addresses, and documents. Unauthorized transactions or malicious activities using compromised accounts. Further compromise of organizational infrastructure through account abuse. Financial and reputational damage due to security breaches.
Just to avoid any semblance of doubt as to the motive of the sender, the subject began by flagging the desire for a bug bounty (Report URI does not advertise a bounty program, but clearly a reward was being sought), followed by an email body stating it related to leaked Report URI credentials and then highlighted that "this vulnerability is severe". And then there's that last line about financial and reputation damage. It looked bad. However, cooler heads prevailed, and we started looking closer at the email addresses in the "breach" by checking them against Have I Been Pwned. Very quickly, a pattern emerged:
Most of the addresses we checked had appeared in the lists posted to Telegram I'd loaded into HIBP a couple of months ago.These were stealer logs, not a breach of Report URI! To validate that assertion, I pulled the original data source and parsed out every line containing "report-uri.com". Sure enough, the lines from the file sent to Scott were usually contained in the stealer log files. So, let's talk about how this works:
Take the URL you saw at the beginning of each line earlier on, the one being for the registration page. Here's what it looks like:
Now, imagine you're filling out this form and your machine is infected with malware that can observe the data entered into each field. It takes that data, "steals" it and logs it at the attacker's server, hence the term "info stealer logs". There is absolutely nothing Scott can do to prevent this; the user's machine is compromised, not Report URI.
To illustrate the point, I grabbed the first email address in the file Scott was sent and pulled the rows just for that address rather than solely the Report URI rows. This would show us all the other services this person's credentials were snared from, and there were dozens. Here are just the first ten:
Google. Apple. Twitter. Most with the same password too, because a normal person obviously owns this email address. So, has each of these organisations also received a beg bounty? No, that's not a typo, this is classic behaviour where unsophisticated and self-proclaimed "security researchers" use automated tooling to identify largely benign security configurations that could be construed as vulnerabilities. For example, they'll send through a report that an SPF record is too permissive (they probably can't even spell "SPF", let alone understand the nuances of sender policies), then try to shake people like Scott down for money under the guise of a "bug bounty". This isn't Scott's problem, nor is it Google's or Apple's or Twitter's, it's something only the malware infected victim's can address.
In this post, I referred to "most" of the addresses already being in HIBP and the lines from the file he was sent "usually" occurring in the logs I had. But there were gaps. For example, whilst there were 197 rows in "his" file, I only found 161 in the data I'd previously loaded. But I had a hunch on how to fill that gap and make up the difference...
Two weeks ago, I was sent a further 22GB of stealer logs found in Telegram channels. Unlike the previous corpus of data, this set contained only stealer logs (no credential stuffing lists) and had a total of 26,105,473 unique email addresses. That's significant, as it implies that every single one of those addresses belongs to someone infected with malware that's stealing their creds. Of the total count, 89.7% had been seen in previous data breaches already in HIBP which is a high crossover, but it also meant that 2,679,550 addresses were all new. I'd been considering whether or not it made sense to load this data given corpuses such as this create frustration when people don't know which site their record was snared from nor which password was impacted. One particular frustration you'll read in comments on the previous post was that people weren't sure whether their email address was in a stealer log or a credential stuffing list; did they have a machine infected with malware or was it merely recycled credentials from an old data breach? But given the way in which this new corpus of data is being used (to attempt to scam Scott and, one would assume, many others), the 7-figure number of previously unseen addresses and the fact that this time, they can all emphatically be tied back to malware campaigns, this is now searchable in HIBP as "Stealer Logs Posted to Telegram".
Ultimately, this is just scam on top of scam: the victims in the logs have had their credentials scammed, and the person who emailed Scott attempted to use that to scam him out of a bounty. Making data like this searchable in HIBP helps people do exactly what I did as soon as Scott forwarded me over the email: validate the origin and as Scott will now do, send a terse reply encouraging the guy to show some decency and stop with the beg bounties.
Lastly, I'm increasingly conscious of how useful the information contained in stealer logs is to organisations like Report URI, and after loading that previous corpus posted from Telegram, I did help out a few companies who thought they might have been hit by it. The position they were coming from was "we keep seeing account takeovers by what looks like credential stuffing attacks, but the attackers are getting the credentials right on the first go". When I pulled the data for their domain as I later did for Report URI, the email addresses were precisely the ones being targeted for account takeover. I want to address this via HIBP, but it's non-trivial for a variety of reasons, especially those related to privacy. In order for this data to be useful to companies like Report URI, I'd need to give them other people's email addresses (the password wouldn't be necessary) based on the assumption they were customers of the service. I'm working out how to do this in way that makes sense for everyone (well, everyone except for the bad guys), stay tuned for more and please do chime in via the comments if you have ideas on how to turn this into a useful service.
Last week, a security researcher sent me 122GB of data scraped out of thousands of Telegram channels. It contained 1.7k files with 2B lines and 361M unique email addresses of which 151M had never been seen in HIBP before. Alongside those addresses were passwords and, in many cases, the website the data pertains to. I've loaded it into Have I Been Pwned (HIBP) today because there's a huge amount of previously unseen email addresses and based on all the checks I've done, it's legitimate data. That's the high-level overview, now here are the details:
Telegram is a popular messaging platform that makes it easy to stand up a "channel" and share information to those who wish to visit it. As Telegram describes the service, it's simple, private and secure and as such, has become very popular with those wishing to share content anonymously, including content related to data breaches. Many of the breaches I've previously loaded into HIBP have been distributed via Telegram as it's simple to publish this class of data to the platform. Here's what data posted to Telegram often looks like:
These are referred to as "combolists", that is they're combinations of email addresses or usernames and passwords. The combination of these is obviously what's used to authenticate to various services, and we often see attackers using these to mount "credential stuffing" attacks where they use the lists to attempt to access accounts en mass. The list above is simply breaking the combos into their respective email service providers. For example, that last Gmail example contains over a quarter of a million rows like this:
That's only one of many files across many different Telegram channels. The data that was sent to me last week was sourced from 518 different channels and amounted to 1,748 separate files similar to the one above. Some of the files have literally no data (0kb), others are many gigabytes with many tens of millions of rows. For example, the largest file starts like this:
That looks very much like the result of info stealer malware that has obtained credentials as they were entered into websites on compromised machines. For example, the first record appears to have been snared when someone attempted to login to Nike. There's an easy way to get a sense of the accuracy of this data, just head over to the Nike homepage and click the login link which presents the following screen:
They serve the same page to both existing subscribers and new ones but then serve different pages depending on whether the email address already has an account (a classic enumeration vector). Mash the keyboard to create a fake email address and you'll be shown a registration form, but enter the address in the stealer log and, well, you get something different:
The email address has an account, hence the prompt for a password. I'm not going to test the password because that would constitute unauthorised access, but I also don't need to as the goal has already been achieved: I've demonstrated that the address has an account on Nike. (Also note that if the password didn't work it wouldn't necessarily mean it wasn't valid at some point in time at the past, it would simply mean it isn't valid now.)
Footlocker tries to be a bit more clever in avoiding enumeration on password reset, but they'll happily tell you via the registration page if the email address you've entered already exists:
Even the Italian tyre retailer happily confirmed the existence of the tested account:
Time and time again, each service I tested confirmed the presence of the email address in the stealer log. But are (or were) the passwords correct? Again, I'm not going to test those myself, but I have nearly 5M subscribers in HIBP and there's always a handful of them in any new breach that are happy to help out. So, I emailed some of the most recent ones, asked if they could help with verification and upon confirmation, sent them their data.
In reaching out to existing subscribers, I expected some repetition in terms of them already appearing in existing data breaches. For one person already in 13 different breaches in HIBP, this was their response:
Thanks Troy. These details were leaked in previous data breaches.
So accurate, but not new, and several of the breaches for this one were of a similar structure to the one we're talking about today in terms of them being combolists used for credential stuffing attacks. Same with another subscriber who was in 7 prior breaches:
Yes that’s familiar. Most likely would have used those credentials on the previous data breaches.
That one was more interesting as of the 7 prior breaches, only 6 had passwords exposed and none of them were combolists. Instead, it was incidents including MyFitnessPal, 8fit, FlexBooker, Jefit, MyHeritage and ShopBack; have passwords been cracked out of those (most were hashed) and used to create new lists? Very possibly. (Sidenote: this unfortunate person is obviously a bit of a fitness buff and has managed to end up in 3 different "fit" breaches.)
Another subscriber had an entry in the following format, similar to what we saw earlier on in the stealer log:
I think that epic games account was for my daughter a couple of years ago but I cancelled it last year from memory. That sds like a password she may have chosen so I'll check with her in an hour or two when I see her again.
And then, a little bit later
My daughter doesn't remember if that was her password as it was 4-5 years ago when she was only 8-9 years old. However it does sound like something she would have chosen so in all probability, I would say that is a legitimate link. We believe it was used when she played a game called Fortnite which she did infrequently at that time hence her memory is sketchy.
I realised that whilst each of these responses confirmed the legitimacy of the data, they really weren't giving me much insight into the factor that made it worth loading into HIBP: the unseen addresses. So, I went through the same process of contacting HIBP subscribers again but this time, only the ones that I'd never seen in a breach before. This would then rule out all the repurposed prior incidents and give me a much better idea of how impactful this data really was. And that's when things got really interesting.
Let's start with the most interesting one and what you're about to see is two hundred rows of stealer logs:
Even without seeing the email address and password, the commonality is clear: German websites. Whilst the email address is common, the passwords are not... at least not always. In 168 instances they were near identical with only a handful of them deviating by a character or two. There's some duplication across the lines (9 different rows of Netflix, 4 of Disney Plus, etc), but clearly this remains a significant volume of data. But is it real? Let's find out:
The data seems accurate so far. I have already changed some of the passwords as I was notified by the provider that my account was hacked. It is strange that the Telekom password was already generated and should not be guessable. I store my passwords in Firefox, so is it possible that they were stolen from there?
It's legit. Stealer malware explains both the Telekom password and why passwords in Firefox were obtained; there's not necessarily anything wrong with either service, but if a machine is infected with software that can grab passwords straight out of the fields they've been entered into in the browser, it's game over.
We started having some to-and-fro as I gathered more info, especially as it related to the timeframe:
It started about a month ago, maximum 6 weeks. I use a Macbook and an iPhone, only a Windows PC at work, maybe it happened there? About a week ago there was an extreme spam attack on my Gmail account, and several expensive items were ordered with my accounts in the same period, which fortunately could be canceled.
We had the usual discussion about password managers and of course before that, tracking down which device is infected and siphoning off secrets. This was obviously distressing for her to see all her accounts laid out like this, not to mention learning that they were being exchanged in channels frequented by criminals. But from the perspective of verifying both the legitimacy and uniqueness of the data (not to mention the freshness), this was an enormously valuable exchange.
Next up was another subscriber who'd previously dodged all the data breaches in HIBP yet somehow managed to end up with 53 rows of data in the corpus:
I've redacted everything after the first three characters of the password so you can get a sense of the breadth of different ones here. In this instance, there was no accompanying website, but the data checked out:
Oh damn a lot of those do seem pretty accurate. Some are quite old and outdated too. I tend to use that gmail account for inconsequential shit so I'm not too fussed, but I'll defintely get stuck in and change all those passwords ASAP. This actually explains a lot because I've noticed some pretty suspicious activity with a couple of different accounts lately.
Another with 35 records of website, email and password triplets responded as follows (I'll stop pasting in the source data, you know what that looks like by now):
Thank you very much for the information, although I already knew about this (I think it was due to a breach in LastPass) and I already changed the passwords, your information is much more complete and clear. It helped me find some pages where I haven't changed the password.
The final one of note really struck a chord with me, not because of the thrirteen rows of records similar to the ones above, but because of what he told me in his reply:
Thank you for your kindness. Most of these I have been able to change the passwords of and they do look familiar. The passwords on there have been changed. Is there a way we both can fix this problem as seeing I am only 14?
That's my son's age and predictably, all the websites listed were gaming sites. The kid had obviously installed something nasty and had signed up to HIBP notifications only a week earlier. He explained he'd recently received an email attempting to extort him for $1.3k worth of Bitcoin and shared the message. It was clearly a mass-mailed, indiscriminate shakedown and I advised him that it in no way targeted him directly. Concerned, he countered with a second extortion email he'd received, this time it was your classic "we caught you watching porn and masturbating" scam, and this one really had him worried:
I have been stressed and scared about these scams (even though I shouldn’t be). I have been very stressed and scared today because of another one of those emails.
Imagine being a young teenage boy and receiving that?! That's the sort of thing criminals frequenting Telegram channels such as the ones in question are using this data for, and it's reprehensible. I gave him some tips (I see the sorts of things my son's friends randomly install!) and hopefully, that'll set him on the right course.
They were the most noteworthy responses, the others that were often just a single email address and password pair just simply reinforced the same message:
Yes, this is an old password that I have used in the past, and matches the password of my accounts that had been logged into recently.
And:
Yes that password is familiar and accurate. I used to practice password re-use with this password across many services 5+ years ago.This makes it impossible to correlate it to a particular service or breach. It is known to me to be out there already, I've received crypto extortion emails containing it.
I know that many people who find themselves in this incident will be confused; which breach is it? I've never used Telegram before, why am I there? Those questions came through during my verification process and I know from loading previous similar breaches, they'll come up over and over again in the coming days and I hope that the overview above sufficiently answers these.
The questions that are harder to answer (and again, I know these will come up based on prior experience), are what the password is that was exposed, what the website it appeared next to was and, indeed, if it appeared next to a website at all or just alongside an email address. Right at the beginning of this project more than a decade ago, I made the decision not to load the data that would answer these questions due to the risk it posed to individuals and by extension, the risk to my ability to continue running HIBP. We were reminded of how important this decision was earlier in the year when a service aggregating data breaches left the whole thing exposed and put everyone in there at even more risk.
So, if you're in here, what do you do? It's a repeat of the same old advice we've been giving in this industry for decades now, namely keeping devices patched and updated, running security software appropriate for your device (I use Microsoft Defender on my PCs), using strong and unique passwords (get a password manager!) and enabling 2FA wherever possible. Each HIBP subscriber I contacted wasn't doing at least one of these things, which was evident in their password selection. Time and time again, passwords consisted of highly predictable patterns and often included their name, year of birth (I assume) and common character substitutions, usually within a dozen characters of length too. It's the absolute basics that are going wrong here.
To the point one of the HIBP subscribers made above, loading this data will help many people explain why they've been seeing unusual behaviour on their accounts. It's also the wakeup call to lift everyone's security game per the previous paragraph. But this also isn't the end of it, and more combolists have been posted in more Telegram channels since loading this incident. Whilst I'm still of the view from years ago that I'm not going to continuously load endless lists, I do hope people recognise that their security posture is an ongoing concern and not just something you think about after appearing in a breach.
Today we loaded 16.5M email addresses and 13.5M unique passwords provided by law enforcement agencies into Have I Been Pwned (HIBP) following botnet takedowns in a campaign they've coined Operation Endgame. That link provides an excellent overview so start there then come back to this blog post which adds some insight into the data and explains how HIBP fits into the picture.
Since 2013 when I kicked off HIBP as a pet project, it has become an increasingly important part of the security posture of individuals, organisations, governments and law enforcement agencies. Gradually and organically, it has found a fit where it's able to provide a useful service to the good guys after the bad guys have done evil cyber things. The phrase I've been fond of this last decade is that HIBP is there to do good things with data after bad things happen. The reputation and reach the service has gained in this time has led to partnerships such as the one you're reading about here today. So, with that in mind, let's get into the mechanics of the data:
In terms of the email addresses, there were 16.5M in total with 4.5M of them not having been seen in previous data breaches already in HIBP. We found 25k of our own individual subscribers in the corpus of data, plus another 20k domain subscribers which is usually organisations monitoring the exposure of their customers (all of these subscribers have now been sent notification emails). As the data was provided to us by law enforcement for the public good, the breach is flagged as subscription free which means any organisation that can prove control of the domain can search it irrespective of the subscription model we launched for large domains in August last year.
The only data we've been provided with is email addresses and disassociated password hashes, that is they don't appear alongside a corresponding address. This is the bare minimum we need to make that data searchable and useful to those impacted. So, let's talk about those standalone passwords:
There are 13.5 million unique passwords of which 8.9M were already in Pwned Passwords. Those passwords have had their prevalence counts updated accordingly (we received counts for each password with many appearing in the takedown multiple times over), so if you're using Pwned Passwords already, you'll see new numbers next to some entries. That also means there are 4.6M passwords we've never seen before which you can freely download using our open source tool. Or even better, if you're querying Pwned Passwords on demand you don't need to do anything as the new entries are automatically added to the result set. All this is made possible by feeding the data into the law enforcement pipeline we built for the FBI and NCA a few years ago.
A quick geek-out moment on Pwned Passwords: at present, we're serving almost 8 billion requests per month to this service:
Taking just last week as an example, we're a rounding error off 100% of requests being served directly from Cloudflare's cache:
That's over 99.99% of all requests during that period that were served from one of Cloudflare's edge nodes that sit in 320 cities globally. What that means for consumers of the service is massively fast response times due to the low latency of serving content from a nearby location and huge confidence in availability as there's only about a one-in-ten-thousand chance of the request being served by our origin service. If you'd like to know more about how we achieved this, check out my post from a year ago on using Cloudflare Cache Reserve.
After pushing out the new passwords today, all but 5 hash prefixes were modified (read more about how we use hashes to enable anonymous password searches) so we did a complete Cloudflare cache flush. By the time you read this, almost the entire 16^5 possible hash ranges have been completely repopulated into cache due to the volume of requests the service receives:
Lastly, when we talk about passwords in HIBP, the inputs we receive from law enforcement consist of 3 parts:
A SHA-1 hash
An NTLM hash
A count of how many times the password appears
The rationale for this is explained in the links above but in a nutshell, the SHA-1 format ensures any badly parsed data that may inadvertently include PII is protected and it aligns with the underlying data structure that drives the k-anonymity searches. We have NTLM hashes as well because many orgs use them to check passwords in their own Active Directory instances.
This operation will be significant in terms of the impact on cybercrime, and I'm glad we've been able to put this little project to good use by supporting our friends in law enforcement who are doing their best to support all of us as online citizens.