We often do that in this industry, the whole "1.0" thing, but it seems apt here. I started Have I Been Pwned (HIBP) in 2013 as a pet project that scratched an itch, so I never really thought of myself as an "employee". Over time, it grew (and I tell you what, nobody is more surprised by that than me!) and over the last few years, my wife Charlotte got more and more involved. Technically, we're both employees and we work on HIBP things but we're like, well, beta versions.
Today, I'm very happy to announce our first full-time, production-ready employee: Stefán Jökull Sigurðarson. This is both a massive commitment on Charlotte's and my part and a leap of faith on Stefán's and deserves some background:
I suffer somewhat from what I'll call the "founder's paradox", that is I find myself having built something genuinely useful and wanting to see it grow and mature yet also not wanting to let go. I want to be involved in everything, but I also want to go on holidays sometimes and tune out. I like making decisions on every aspect of how the service runs, but I want it to outlive me. Bringing any outside party into any business can be hard to come to terms with, but especially in the case of HIBP where it's become so critical to so many people and deals with so much sensitive data. Which is why I have to trust people like Stefán because if I don't, I'm one shark / snake / croc incident away from disappointing a lot of people.
Trust is the cornerstone of why Stefán is joining us now. Not just trust in his technical skills, but trust in him as a person. I've known Stefán for many years now, initially when he came to one of my Hack Yourself First workshops in Oslo back in 2018, then as a blogger writing about how he was implementing Pwned Passwords at EVE Online, then as conference speaker himself, a Microsoft MVP, and in 2021, as the person who selflessly gave up his own time to support the open source Pwned Passwords. What we never made any formal announcements about is that we did hire Stefán on a part-time basis beginning earlier last year to help out with the coding when he had free cycles amidst his full-time work. That went great and he obviously enjoyed working at HIBP so earlier this month, Stefán handed in his resignation and will shortly be a full-time employee.
I'm really happy with the timing of this and how it's all worked out. We're in a position to make the financial commitment largely because of finally putting a price on searches for large domains last year. What this has allowed us to do is shift money from companies who see value in the service (more than half the Fortune 500 use the domain search feature), and reinvest it into making HIBP more sustainable. Getting Stefán onboard is the manifestation of that investment and you'll very shortly see his work begin to translate into highly visible new features. But what you won't see is the stuff that's even more important, especially as it relates to running a more sustainable service that no longer has me as a single point of failure.
So, welcome Stefán, and thank you for your commitment 😊
Oh - just one more thing: I was looking around for a great hero image for this blog post and I found this awesome video of Stefán swimming through a semi-frozen Norwegian fjord before riding an iceberg. For real, this it perhaps the most Nordic thing I've ever seen (Stefán being from Iceland and all), but unfortunately videos don't really lend themselves to hero images, so I went switch a stylised AI-generated rendition of the event.
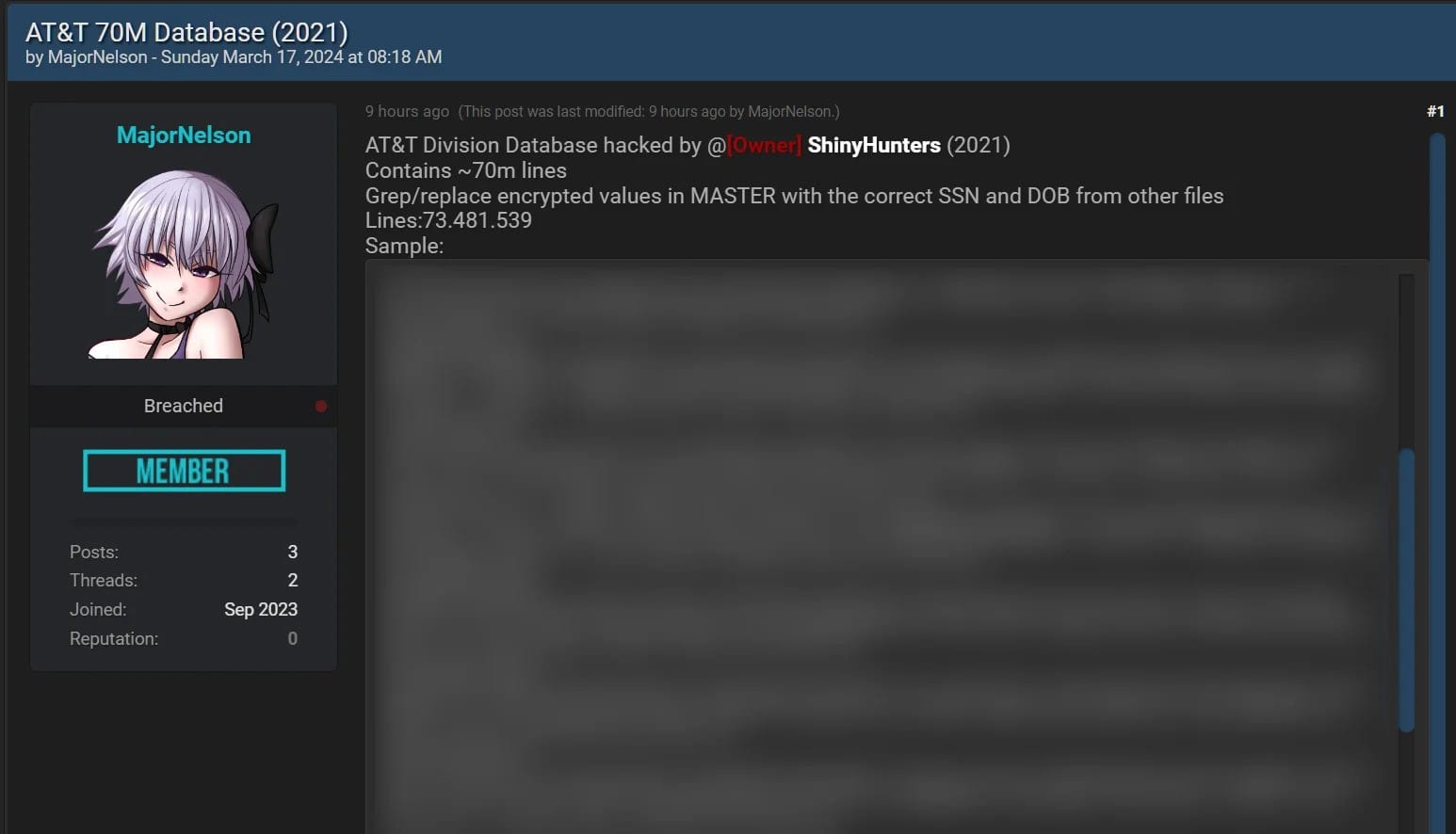
I hate having to use that word - "alleged" - because it's so inconclusive and I know it will leave people with many unanswered questions. But sometimes, "alleged" is just where we need to begin and over the course of time, proper attribution is made and the dots are joined. We're here at "alleged" for two very simple reasons: one is that AT&T is saying "the data didn't come from us", and the other is that I have no way of proving otherwise. But I have proven, with sufficient confidence, that the data is real and the impact is significant. Let me explain:
From the samples shared by the threat actor, the database contains customers' names, addresses, phone numbers, Social Security numbers, and date of birth.
Fast forward two and a half years and the successor to this forum saw a post this week alleging to contain the entire corpus of data. Except that rather than put it up for sale, someone has decided to just dump it all publicly and make it easily accessible to the masses. This isn't unusual: "fresh" data has much greater commercial value and is often tightly held for a long period before being released into the public domain. The Dropbox and LinkedIn breaches, for example, occurred in 2012 before being broadly distributed in 2016 and just like those incidents, the alleged AT&T data is now in very broad circulation. It is undoubtedly in the hands of thousands of internet randos.
AT&T's position on this is pretty simple:
AT&T continues to tell BleepingComputer today that they still see no evidence of a breach in their systems and still believe that this data did not originate from them.
The old adage of "absence of evidence is not evidence of absence" comes to mind (just because they can't find evidence of it doesn't mean it didn't happen), but as I said earlier on, I (and others) have so far been unable to prove otherwise. So, let's focus on what we can prove, starting with the accuracy of the data.
The linked article talks about the author verifying the data with various people he knows, as well as other well-known infosec identities verifying its accuracy. For my part, I've got 4.8M Have I Been Pwned (HIBP) subscribers I can lean on to assist with verification, and it turns out that 153k of them are in this data set. What I'll typically do in a scenario like this is reach out to the 30 newest subscribers (people who will hopefully recall the nature of HIBP from their recent memory), and ask them if they're willing to assist. I linked to the story from the beginning of this blog post and got a handful of willing respondents for whom I sent their data and asked two simple questions:
Does this data look accurate?
Are you an AT&T customer and if not, are you a customer of another US telco?
The first reply I received was simple, but emphatic:
This individual had their name, phone number, home address and most importantly, their social security number exposed. Per the linked story, social security numbers and dates of birth exist on most rows of the data in encrypted format, but two supplemental files expose these in plain text. Taken at face value, it looks like whoever snagged this data also obtained the private encryption key and simply decrypted the vast bulk (but not all of) the protected values.
The above example simply didn't have plain text entries for the encrypted data. Just by way of raw numbers, the file that aligns with the "70M" headline actually has 73,481,539 lines with 49,102,176 unique email addresses. The file with decrypted SSNs has 43,989,217 lines and the decrypted dates of birth file only has 43,524 rows. The last file, for example, has rows that look just like this:
That encrypted value is precisely what appears in the large file hence providing an easy way of matching all the data together. But those numbers also obviously mean that not every impacted individual had their SSN exposed, and most individuals didn't have their date of birth leaked.
As I'm fond of saying, there's only one thing worse than your data appearing on the dark web: it's appearing on the clear web. And that's precisely where it is; the forum this was posted to isn't within the shady underbelly of a Tor hidden service, it's out there in plain sight on a public forum easily accessed by a normal web browser. And the data is real.
That last response is where most people impacted by this will now find themselves - "what do I do?" Usually I'd tell them to get in touch with the impacted organisation and request a copy of their data from the breach, but if AT&T's position is that it didn't come from them then they may not be much help. (Although if you are a current or previous customer, you can certainly request a copy of your personal information regardless of this incident.) I've personally also used identity theft protection services since as far back as the 90's now, simply to know when actions such as credit enquiries appear against my name. In the US, this is what services like Aura do and it's become common practice for breached organisations to provide identity protection subscriptions to impacted customers (full disclosure: Aura is a previous sponsor of this blog, although we have no ongoing or upcoming commercial relationship).
What I can't do is send you your breached data, or an indication of what fields you had exposed. Whilst I did this in that handful of aforementioned cases as part of the breach verification process, this is something that happens entirely manually and is infeasible en mass. HIBP only ever stores email addresses and never the additional fields of personal information that appear in data breaches. In case you're wondering why that is, we got a solid reminder only a couple of months ago when a service making this sort of data available to the masses had an incident that exposed tens of billions of rows of personal information. That's just an unacceptable risk for which the old adage of "you cannot lose what you do not have" provides the best possible fix.
As I said in the intro, this is not the conclusive end I wanted for this blog post... yet. As impacted HIBP subscribers receive their notifications and particularly as those monitoring domains learn of the aliases in the breach (many domain owners use unique aliases per service they sign up to), we may see a more conclusive outcome to this incident. That may not necessarily be confirmation that the data did indeed originate from AT&T, it could be that it came from a third party processor they use or from another entity altogether that's entirely unrelated. The truth is somewhere there in the data, I'll add any relevant updates to this blog post if and when it comes out.
I've always thought of it a bit like baseball cards; a kid has a card of this one player that another kid is keen on, and that kid has a card the first one wants so they make a trade. They both have a bunch of cards they've collected over time and by virtue of existing in the same social circles, trades are frequent, and cards flow back and forth on a regular basis. That's the analogy I often use to describe the data breach "personal stash" ecosystem, but with one key difference: if you trade a baseball card then you no longer have the original card, but if you trade a data breach which is merely a digital file, it replicates.
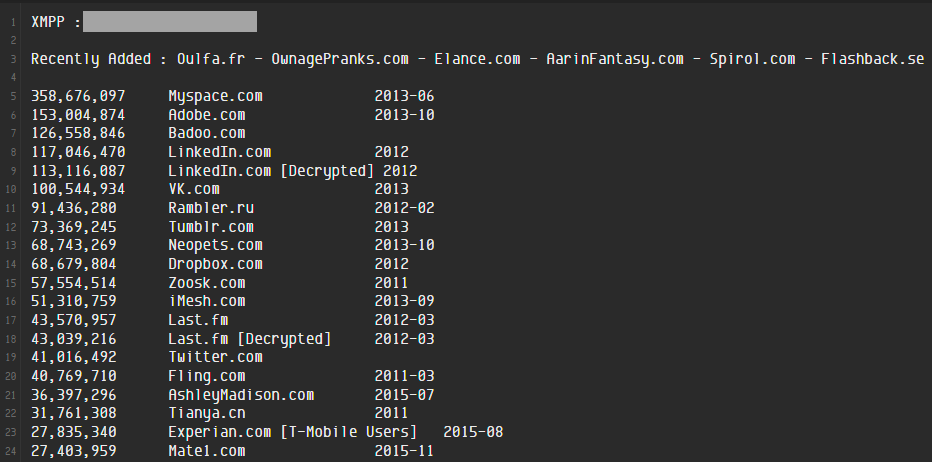
There are personal stashes of data breaches all over the place and they're usually presented like this one:
You'll recognise many of those names because they're noteworthy incidents that received a bunch of press. My Space. Adobe. LinkedIn. Ashley Madison.
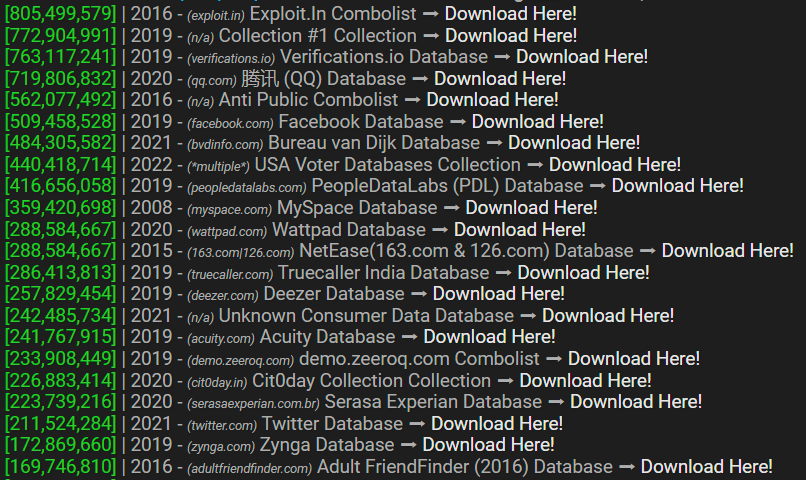
The same incidents appear here:
And so on and so forth. Stashes of breaches like this are all over the place and they fuel an exchange ecosystem that replicates billions of records of personal data over and over again. Your data. My data. The data of a significant portion of the global internet-using population, just freely flowing backwards and forwards not just in the shady corners of "the dark web" but traded out there in the clear on mainstream websites. Until inevitably:
Websites like these are taken down for a simple reason:
The ecosystem of personal stashes exchanged with other parties fuels crime.
For example, data breaches seed services set up with the express intent of monetising a broad range of personal attributes to the detriment of people who are already victims of a breach. Call them shady versions of Have I Been Pwned if you will, and this talk I gave at AusCERT a couple of years ago is a great explainer (deep-linked to the start of that segment):
The first service I spoke about in that segment was We Leak Info and it was run by two 22 year old guys. The website first appeared 3 years earlier - only a year after the creators had left childhood - and it allowed anyone with the money to access anyone else's personal data including:
names, email addresses, usernames, phone numbers, and passwords
However, unlike other breach notification services, such as Have I Been Pwned, LeakedSource also gave subscribers access to usernames, passwords (including in clear text), email addresses and IP addresses. LeakedSource services were often advertised on hacking forums and there was suspicion that its operators were actively looking to hack organizations whose data they could add to their database.
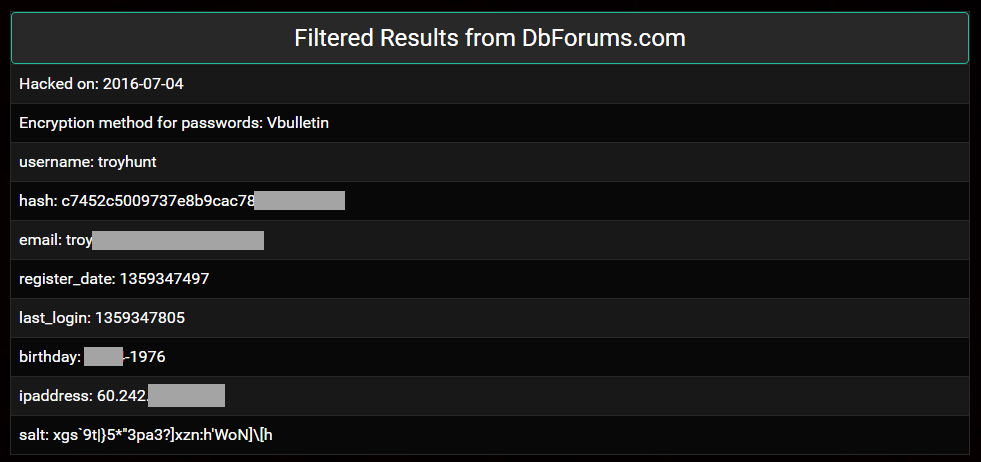
In 2016, a well-wisher purchased my own data from LeakedSource and sent over a dozen different records similar to this one:
Not mentioned in my talk but running in the same era was Leakbase, yet another service that collated huge volumes of sensitive data and sold it to absolutely anyone:
And just like all the other ones, the same data appeared over and over again:
It went dark at the end of 2017 amidst speculation the disappearance was tied to the takedown of the Hansa dark web market. If that was the case, why did we never hear of charges being laid as we did with We Leak Info and LeakedSource? Could it be that the operator of Leakbase was only ever so slightly younger than the other guys mentioned above and not having yet reached adulthood, managed to dodge charges? It would certainly be consistent with the demographic pattern of those with personal stashes of data breaches.
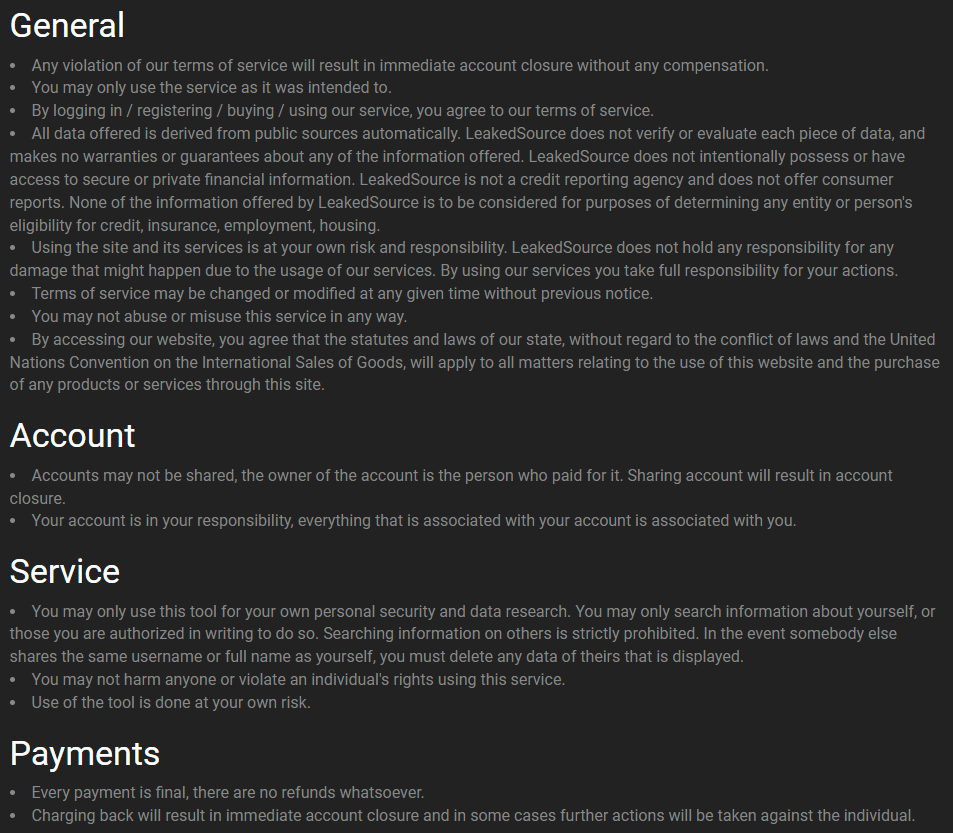
Speaking of patterns: We Leak Info, LeakedSource, Leakbase - it's like there's a theme of shady services attached to the word. As I say in the video, there's also a theme of attempting to remain anonymous (which clearly hasn't worked very well!), and a theme of attempting to eschew legal responsibility for how the data is used by merely putting words in the terms of service. For example, here's Jordan's go at deflecting his role in the ecosystem and yes, this was the entire terms of service:
I particularly like this clause:
You may only use this tool for your own personal security and data research. You may only search information about yourself, or those you are authorized in writing to do so.
That's not going to keep you out of trouble! Time and time again, I see this sort of wording on services used as if it's going to make a difference when the law comes asking hard questions; "Hey we literally told people to play nice with the data!"
We Leak Info strictly prohibits the use of its Services to cause damage or harm to others
You may not use Our Services in acts deemed illegal by the laws in Your region
We Leak Info does not knowingly participate in the act of obtaining or distributing Data
We Leak Info will cooperate with any legal investigations that it determines worthy and valid at its own discretion
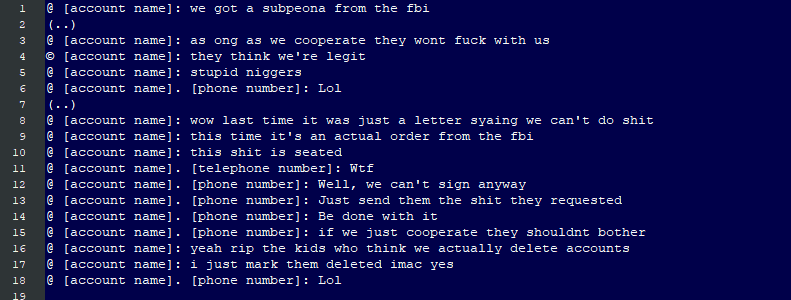
That last one in particular is an absolute zinger! But again, remember, we're talking about guys who stood this service up as teenagers and literally worked on the assumption of "as [l]ong as we cooperate they [the FBI] won't fuck with us" 🤦♂️ The ignorance of that attitude whilst advertising services on criminal forums is just mind-blowing, even for kids.
All of which brings me to the inspiration for this blog post:
Interesting find by @MayhemDayOne, wonder if it was from a shady breach search service (we’ve seen a bunch shut down over the years)? Either way, collecting and storing this data is now trivial so not a big surprise to see someone screw up their permissions and (re)leak it all. https://t.co/DM7udeUcRk
It's like I've seen it all before! No, really, because only a couple of days later someone running a service popped up and claimed responsibility for having exposed the data due to "a firewall misconfiguration". I'm not going to name or link the service, but I will describe a few key features:
After purchasing access, it returns extensive personal information exposed in data breaches including names, email addresses, usernames, phone numbers, and passwords
The operator is clearly trying to remain anonymous with no discoverable information about who is running it
It has ToS that include: "You may only use this service for your own personal security and research. Furthermore, you may only search for information about yourself or those who you are authorized in writing to do so." (I know what you're thinking, so I diff'd it for you)
The name of the service starts with the word "leak"
I could write predictions about the future of this service but if you've read this far and paid attention to the precedents, you can reliably form your own conclusion. The outcome is easily predictable and indeed it was the predictability of the whole situation when I started getting bombarded with queries about the "Mother of all Breaches" that frustrated me; of course it was someone's personal stash, because we've seen it all before and we live in an era where it's dead easy to build services like this. Cloud is ubiquitous and storage is cheap, you can stand up great looking websites in next to no time courtesy of freely available templates, and the whole data breach trading ecosystem I referred to earlier can easily seed services like this.
Maybe the young guy running this service (assuming the previously observed patterns apply) will learn from history and quietly exit while the getting is good, I don't know, time will tell. At the very least, if he reads this and takes nothing else away, don't go driving around in a bright green Lamborghini!
It feels like not a week goes by without someone sending me yet another credential stuffing list. It's usually something to the effect of "hey, have you seen the Spotify breach", to which I politely reply with a link to my old No, Spotify Wasn't Hacked blog post (it's just the output of a small set of credentials successfully tested against their service), and we all move on. Occasionally though, the corpus of data is of much greater significance, most notably the Collection #1 incident of early 2019. But even then, the rapid appearance of Collections #2 through #5 (and more) quickly became, as I phrased it in that blog post, "a race to the bottom" I did not want to take further part in.
Until the Naz.API list appeared. Here's the back story: this week I was contacted by a well-known tech company that had received a bug bounty submission based on a credential stuffing list posted to a popular hacking forum:
Whilst this post dates back almost 4 months, it hadn't come across my radar until now and inevitably, also hadn't been sent to the aforementioned tech company. They took it seriously enough to take appropriate action against their (very sizeable) user base which gave me enough cause to investigate it further than your average cred stuffing list. Here's what I found:
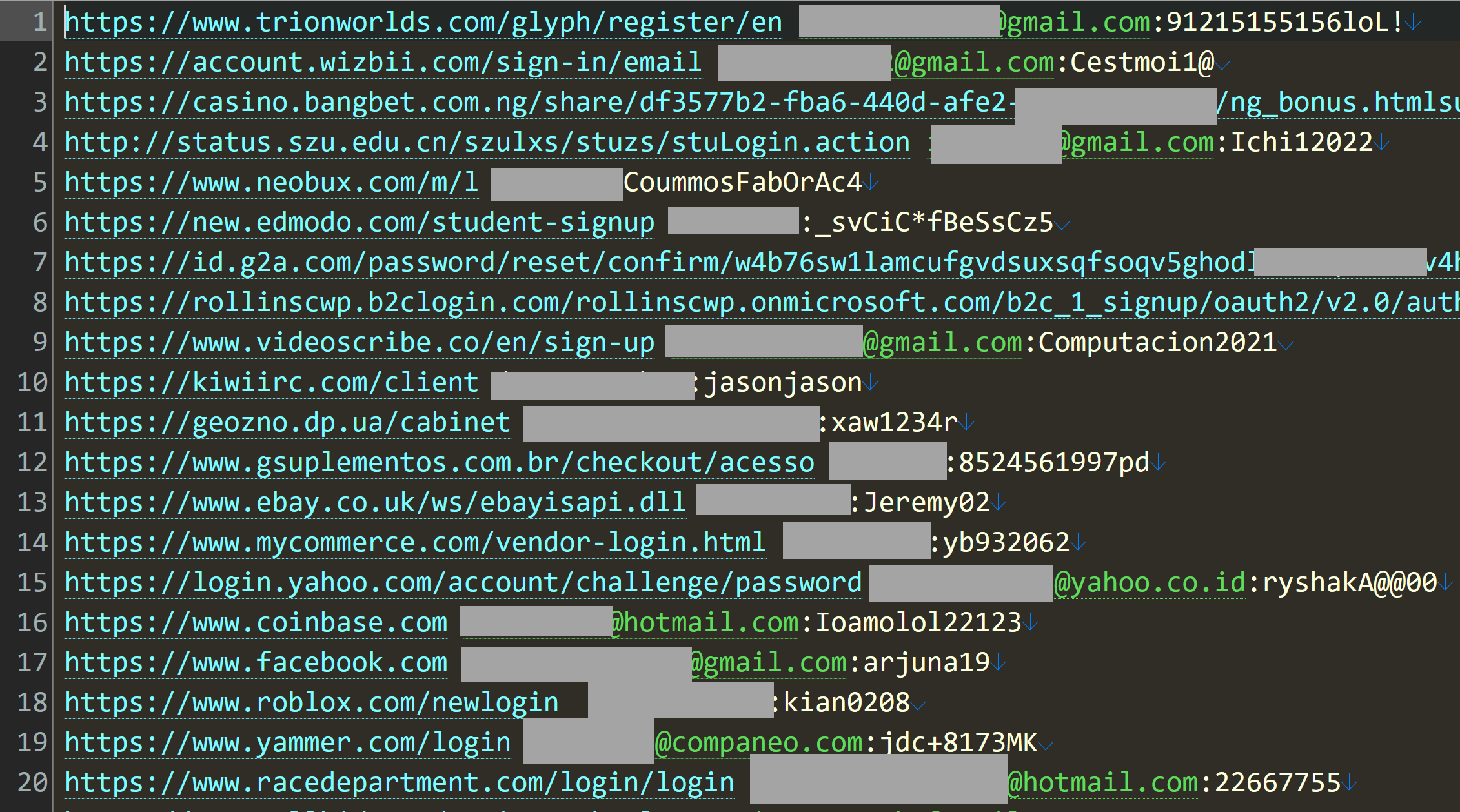
319 files totalling 104GB
70,840,771 unique email addresses
427,308 individual HIBP subscribers impacted
65.03% of addresses already in HIBP (based on a 1k random sample set)
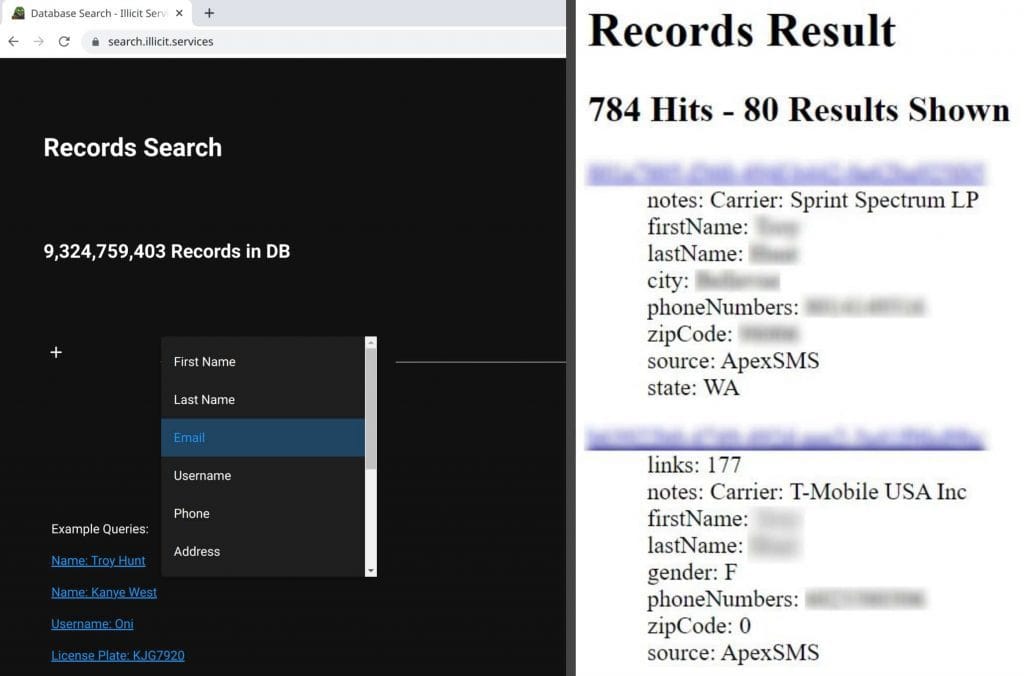
That last number was the real kicker; when a third of the email addresses have never been seen before, that's statistically significant. This isn't just the usual collection of repurposed lists wrapped up with a brand-new bow on it and passed off as the next big thing; it's a significant volume of new data. When you look at the above forum post the data accompanied, the reason why becomes clear: it's from "stealer logs" or in other words, malware that has grabbed credentials from compromised machines. Apparently, this was sourced from the now defunct illicit.services website which (in)famously provided search results for other people's data along these lines:
I was aware of this service because, well, just look at the first example query 🤦♂️
So, what does a stealer log look like? Website, username and password:
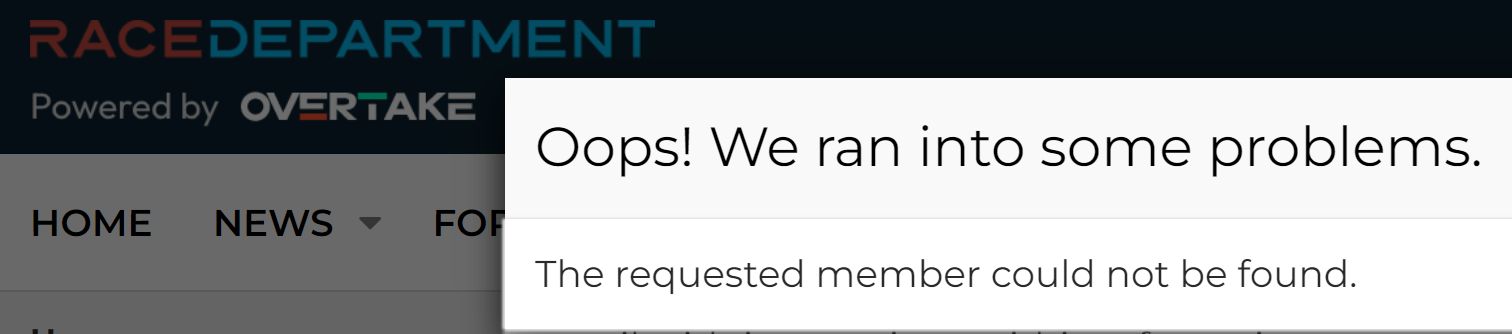
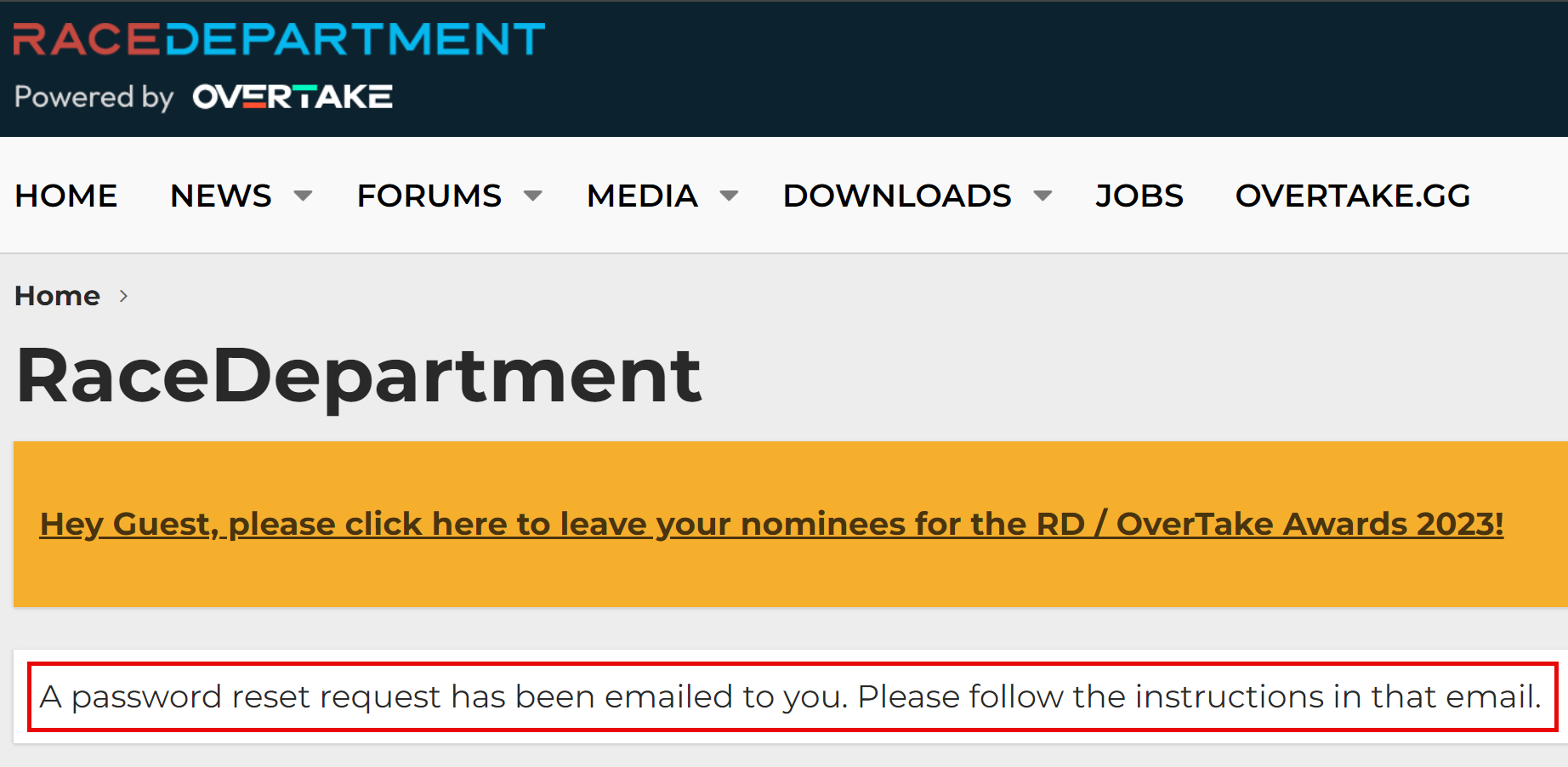
That's just the first 20 rows out of 5 million in that particular file, but it gives you a good sense of the data. Is it legit? Whilst I won't test a username and password pair on a service (that's way too far into the grey for my comfort), I regularly use enumeration vectors on websites to validate whether an account actually exists or not. For example, take that last entry for racedepartment.com, head to the password reset feature and mash the keyboard to generate a (quasi) random alias @hotmail.com:
And now, with the actual Hotmail address from that last line:
The email address exists.
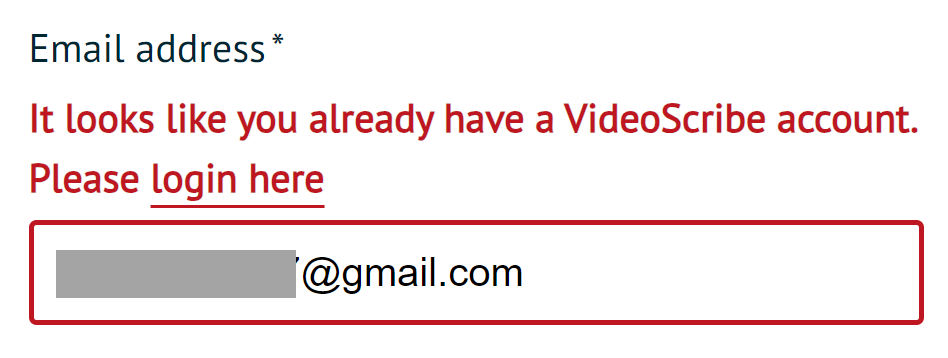
The VideoScribe service on line 9:
Exists.
And even the service on the very first line:
From a verification perspective, this gives me a high degree of confidence in the legitimacy of the data. The question of how valid the accompanying passwords remain aside, time and time again the email addresses in the stealer logs checked out on the services they appeared alongside.
Another technique I regularly use for validation is to reach out to impacted HIBP subscribers and simply ask them: "are you willing to help verify the legitimacy of a breach and if so, can you confirm if your data looks accurate?" I usually get pretty prompt responses:
Yes, it does. This is one of the old passwords I used for some online services.
When I asked them to date when they might have last used that password, they believed it was was either 2020 or 2021.
And another whose details appears alongside a Webex URL:
Yes, it does. but that was very old password and i used it for webex cuz i didnt care and didnt use good pass because of the fear of leaking
And another:
Yes these are passwords I have used in the past.
Which got me wondering: is my own data in there? Yep, turns out it is and with a very old password I'd genuinely used pre-2011 when I rolled over to 1Password for all my things. So that sucks, but it does help me put the incident in more context and draw an important conclusion: this corpus of data isn't just stealer logs, it also contains your classic credential stuffing username and password pairs too. In fact, the largest file in the collection is just that: 312 million rows of email addresses and passwords.
Speaking of passwords, given the significance of this data set we've made sure to roll every single one of them into Pwned Passwords. Stefán has been working tirelessly the last couple of days to trawl through this massive corpus and get all the data in so that anyone hitting the k-anonymity API is already benefiting from those new passwords. And there's a lot of them: it's a rounding error off 100 million unique passwords that appeared 1.3 billion times across the corpus of data 😲 Now, what does that tell you about the general public's password practices? To be fair, there are instances of duplicated rows, but there's also a massive prevalence of people using the same password across multiple difference services and completely different people using the same password (there are a finite set of dog names and years of birth out there...) And now more than ever, the impact of this service is absolutely huge!
Pwned Passwords remains totally free and completely open source for both code and data so do please make use of it to the fullest extent possible. This is such an easy thing to implement, and it has a profound impact on credential stuffing attacks so if you're running any sort of online auth service and you're worried about the impact of Naz.API, this now completely kills any attack using that data. Password reuse remain rampant so attacks of this type prosper (23andMe's recent incident comes immediately to mind), definitely get out in front of this one as early as you can.
So that's the story with the Naz.API data. All the email addresses are now in HIBP and searchable either individually or via domain and all those passwords are in Pwned Passwords. There are inevitably going to be queries along the lines of "can you show me the actual password" or "which website did my record appear against" and as always, this just isn't information we store or return in queries. That said, if you're following the age-old guidance of using a password manager, creating strong and unique ones and turning 2FA on for all your things, this incident should be a non-event. If you're not and you find yourself in this data, maybe this is the prompt you finally needed to go ahead and do those things right now 🙂
A decade ago to the day, I published a tweet launching what would surely become yet another pet project that scratched an itch, was kinda useful to a few people but other than that, would shortly fade away into the same obscurity as all the other ones I'd launched over the previous couple of decades:
It's alive! "Have I been pwned?" by @troyhunt is now up and running. Search for your account across multiple breaches http://t.co/U0QyHZxP6k
And then, as they say, things kinda escalated quickly. The very next day I published a blog post about how I made it so fast to search through 154M records and thus began a now 185-post epic where I began detailing the minutiae of how I built this thing, the decisions I made about how to run it and commentary on all sorts of different breaches. And now, a 10th birthday blog post about what really sticks out a decade later. And that's precisely what this 185th blog post tagging HIBP is - the noteworthy things of the years past, including a few things I've never discussed publicly before.
Pwned?
You know why it's called "Have I Been Pwned"? Try coming up with almost any conceivable normal sounding English name and getting a .com domain for it. Good luck! That was certainly part of it, but another part of the name choice was simply that I honestly didn't expect this thing to go anywhere. It's like I said in the intro of this post where I fully expected this to be another failed project, so why does the name matter?
But it's weird how "pwned" has stuck and increasingly, become synonymous with HIBP. For many people, the first time they ever hear the word is in the context of "Have I Been..." with an ensuing discussion often explaining the origins of the term as it relates to gaming culture. And if you do go and look for a definition of the term online, you'll come across resources such as How “PWNED” went from hacker slang to the internet’s favourite taunt:
Then in 2013, when various web services and sites saw an uptick in personal data breaches, security expert Troy Hunt created the website “Have I Been Pwned?” Anyone can type in an email address into the site to check if their personal data has been compromised in a security breach.
And somehow, this little project is now referenced in the definition of the name it emerged from. Weird.
It's difficult to even know where to start here. How does the little site with the weird name end up in the press? Inevitably, "because data breaches", and it's nuts just how much exposure this project has had because of them. These are often mainstream news events and what reporters often want to impart to people is along the lines of "Here's what you should do if you've been impacted", which often boils down to checking HIBP.
Press is great for raising awareness of the project, but it has also quite literally DDoS'd the service with the Martin Lewis Money Show in the UK knocking it offline in 2016. Cool! No, for real, I learned some really valuable lessons from that experience which, of course, I shared in a blog post. And then ensured could never happen again.
The point is that it's had impact, and nobody is more surprised about that than me.
Congress
How on earth did I end up here?!
6 years and a few days ago now, I found myself in a place I'd only ever seen before in the movies: Congress. American Congress. Saying "pwned"!
For reasons I still struggle to completely grasp, the folks there thought it would be a good idea if I flew to the other side of the world and talked about the impact of data breaches on identity verification. "You know they're just trying to get you to DC so they can arrest you for all that stolen data you have, right?! 🤣", the internet quipped. But instead, I had one of the most memorable moments of my career as I read my testimony (these are public hearings so it's all recorded and available to watch), responded to questions from congressmen and congresswomen and rounded out the trip staring down at where they inaugurate presidents:
Today, that photo adorns the wall outside my office and dozens of times a day I look at it and ask the same question - how did it all lead to this?!
Svalbard
The potential sale of HIBP was a very painful, very expensive chapter of life, announced in a blog post from June 2019. For the most part, I was as transparent and honest as I could be about the reasons behind the decision, including the stress:
To be completely honest, it's been an enormously stressful year dealing with it all.
More than one year later, I finally wrote about the source of so much of that stress: divorce. Relationship circumstances had put a huge amount of pressure on me and I needed a relief valve which at the time, I thought would be the sale of the project I loved so much but was becoming increasingly demanding. Ultimately, Project Svalbard (the code name for the sale of HIBP), had the opposite effect as years of bitter legal battles with my ex ensued, in part due to the perceived value that would have been realised had it been sold and some big tech company owned my arse for years to come. The project I built out of a passion to do community good was now being used as a tool to extract as much money out of me as possible. There's a wild story to be told there one day but whilst that saga is now well and truly behind me, the scars are still raw.
There were many times throughout Project Svalbard where I felt like I was living out an episode of Silicon Valley, especially as I hopped between interviews at the who's-who of tech firms in San Francisco to meet potential acquirers. But there was one moment in particular that I knew at the time would form an indelible memory, so I took a photo of it:
I'm sitting in a rental car in Yosemite whilst driving from the aforementioned meetings in SF and onto Vegas for the annual big cyber-events. I had a scheduled call with a big tech firm who was a potential acquirer and should that deal go through, the guy I was speaking to would be my new boss. I'd done that dozens of times by now and I don't know if it was because I was especially tired or emotional or if there was something in the way he phrased the question, but this triggered something deep inside me:
So Troy, what would your perfect day in the office look like?
I didn't say it this directly, but I kid you not this is exactly what popped into my mind:
I get on my jet ski and I do whatever the fuck I want
My potential new overlord had somehow managed to find exactly the raw nerve to touch that made me realise how valuable independence had become to me. 6 months later, Project Svalbard was dead after a deal I'd struck fell through. I still can't talk about the precise circumstances due to being NDA'd up to wazoo, but the term we chose to use was "a change of business circumstances on behalf of the purchaser". With the benefit of hindsight, I've never been so happy to have lost so much 😊
The FBI
10 years ago, I certainly didn't see this on the cards:
Nor did I expect them to be actively feeding data into HIBP. Or the UK's NCA to be feeding data in. Or various other law enforcement agencies the world over. And I never envisioned a time where dozens of national governments would be happy to talk about using the service.
A couple of months ago, the ABC wrote a long piece on how this whole thing is, to use their term, a strange sign of the times.
He’s just “a dude on the web”, but Troy Hunt has ended up playing an oddly central role in global cybersecurity.
It's strange until you look at through the lens of aligned objectives: the whole idea of HIBP was "to do good things after bad things happen" which is well aligned with the mandates of law enforcement agencies. You could call it... common ground:
This is something I suspect a lot of people don't understand - that law enforcement agencies often work in conjunction with private enterprise to further their goals of protecting people just like you and me. It's something I certainly didn't understand 10 years ago, and I still remember the initial surprise when agencies started reaching out. Many years on, these have become really productive relationships with a bunch of top notch people, a number of whom I now count as friends and make an effort to spend time with on my travels.
Passwords
This was never on the cards originally. In fact, I'd always been adamant that there should never be passwords in HIBP although in my defence, the sentiment was that they should never appear next to the username to which they originally accompanied. But looking at passwords through the lens of how breach data can be used to do good things, a list of known compromised passwords disassociated from any form of PII made a lot of sense. So, in 2017, Pwned Passwords was born. You know what I was saying earlier about things escalating quickly? Yeah:
Setting all new records for Pwned Passwords this week: biggest day ever yesterday at 282M requests and biggest rolling 30 days ever, now passing the 6 *billion* requests mark! pic.twitter.com/dQiuQim3da
As if to make the point, I just checked the latest stats and last week we did 301.6M requests in a single day. 100% of those requests - and that's not a rounded number either, it's 100.0000000000% - were served from Cloudflare's cache 🤯
There's so much I love about this service. I love that it's free, there's no auth, it's entirely open source (both code and data), the FBI feeds data into it and perhaps most importantly, it has real impact on security. It's such a simple thing, but every time you see a headline such as "Big online website hit with credential stuffing attack", a significant portion of the accounts being taken over have passwords that could easily have been blocked.
The Paradox of Handling Data Breaches
On multiple occasions now, I've had conversations that can best be paraphrased as follows:
Random Internet Person: I'm going to report you to the FBI for having all that stolen data
Me: Maybe you should start by Googling "troy hunt fbi" first...
But I understand where they're coming from and the paradox I refer to is the perceived conflict between handling what is usually the output of a crime whilst simultaneously trying to perform a community good. It's the same discussion I've often had with people citing privacy laws in their corner of the world (often the EU and GDPR) as the reason why HIBP shouldn't exist: "but you're processing data without informed consent!", they'll claim. The issue of there being other legal bases for processing aside, nobody consents to being in a data breach! The natural progression of that conversation is that being in a data breach is a parallel discussion to HIBP then indexing it and making it searchable, which is something I've devoted many words to addressing in the past.
But for all the bluster the occasional random internet person can have (and honestly, I could count the number of annual instances of this on one hand), nothing has come of any complaints. And when I say "complaints", it's often nothing more than a polite conversation which may simply conclude with an acknowledgment of opposing views and that's it. There has been one exception in the entire decade of running this service where a complaint did come via a government privacy regulator, I responded to all the questions that were asked and that was the end of it.
People
When you have a pet project like HIBP was in the beginning, it's usually just you putting in the hours. That's fine, it's a hobby and you're scratching an itch, so what does it matter that there's nobody else involved? Like many similar passion projects, HIBP consumed a lot of hours from early on, everything from obviously building the service then sourcing data breaches, verifying and disclosing them, writing up descriptions and even editing every single one of those 700+ logos by hand to be just the right dimensions and file size. But in the beginning, if I'd just stopped one day, what would happen? Nothing. But today, a genuinely important part of the internet that a huge number of individuals, corporations and governments have built dependencies on would stop working if I lost interest.
The dependency on just me was partly behind the possible sale in 2019, but clearly that didn't eventuate. There was always the option to employ people and build it out like most people would a normal company, but every time I gave that consideration it just didn't stack up for a whole bunch of reasons. It was certainly feasible from the perspective of building some sort of valuable commercial entity, but in just the same way as that question about my perfect day in the office sucked the soul from my body, so did the prospect of being responsible for other people. Employment contracts. Salary negotiations. Performance reviews. Sick leave and annual leave and all sorts of other people issues from strangers I'd need to entrust with "my baby". So, bringing in more people was a really unattractive idea, with 2 exceptions:
In early 2021, my (soon to be at the time) wife Charlotte started working for HIBP.
Charlotte had spent the last 8 years working with people just like me; software nerds. As a project manager for the NDC conferences based out of Norway, she'd dealt with hundreds of speakers (including me on many occasions), and thousands of attendees at the best conference I've ever been a part of. Plus, she spent a great deal of time coordinating sponsors, corporate attendees and all sorts of other folks that live in the tech world HIBP inhabited. For Charlotte, even though she's not a technical person (her qualifications are in PR and entrepreneurial studies), this was very familiar territory.
So, for the last few years, Charlotte has done absolutely everything that she can to ensure that I can focus on the things that need my attention. She onboards new corporate subscribers, handles masses of tickets for API and domain subscribers and does all the accounting and tax work. And she does this tirelessly every single day at all sorts of hours whether we're at home or travelling. She is... amazing 🤩
Earlier this year, Stefán Jökull Sigurðarson started working for us part time writing code, cleaning up code, migrating code and, well, doing lots of different code things.
Just today I asked Stefán what I should write about him, thinking he'd give me some bullet points I'd massage and then incorporate into this blog post. Instead, I reckon what he wrote was so spot on that I'm just going to quote the entire thing here:
"Just" that having had my eye on the service since it was released and then developing one of the first big integrations with the PwnedPasswords v2 API in EVE, coinciding with us meeting for the first time at NDC Oslo in 2018 shortly after, HIBP has managed to take me on this awesome journey where it has been a part of launching my public speaking career, contributing to OSS with Pwned Passwords, becoming an MVP and helped me meet a bunch of awesome people and allowed me to contribute to a better and hopefully safer internet. I'm very happy and honoured to a be a part of this project which is full of awesome challenges and interesting problems to deal with. Having meeting invites from the FBI in my inbox a few years after doing a few experimental rest calls to the Pwned Passwords API in early 2018 was definitely not something I was expecting 😅
What really resonated with me in Stefán's message is that for him, this isn't just a job, it's a passion. His journey is my journey in that we freely devoted our time to do something we love and it led to many wonderful things, including MVP roles and speaking at "Charlotte's" conference, NDC. Stefán is based in Iceland, but we've still had many opportunities to share beers together and establish a relationship that transcends merely writing code. I can't think of anyone better to do what he does today.
Breaches
731 breaches later, here we are. So, what stands out? Just going off the top of my head here:
Ashley Madison. Every knows the name so it needs no introduction, but that incident in 2015 had a major impact on HIBP in terms of use of the service, and also a major impact on me in terms of the engagements I had with impacted parties. My blog post on Here’s what Ashley Madison members have told me still feels harrowing to read.
Collection #1. This is the one that really contributed to my stress levels in early 2019 and had a profound impact on my decision to look at selling the service. Read about where those 773M records came from (still the largest breach in HIBP to date).
Rosebutt. Don't make a joke about it, don't make a joke about it, don't... aw man, thanks The Register! (link to an archive.org version as they seem to have thought better of their image choice later on...) The point is that even serious data breaches can have their moments of levity.
Shit Express. Sometimes, you just need a bit of hilarity in your data breach. Shit Express is literally a site to send other people pieces of that - anonymously - and they got breached, thus somewhat affecting their anonymity. The more serious point is that as I later wrote, claims of anonymity are often highly misleading.
Future
I often joke about my life being very much about getting up each morning, reading my emails and events from overnight and then just winging it from there. Of course there are the occasional scheduled things not to mention travel commitments, but for the most part it's very much just rolling with whatever is demanding attention on the day. This is also probably a significant part of why I don't really want to see this thing grow into a larger concern with more responsibilities, I just don't want to lose that freedom. Yet...
We're gradually moving in a direction where things become more formalised. 3 years ago, I did 100% of everything myself. 1 year ago, I did everything technical myself. 6 months ago, we had no ticketing system for support. But these are small, incremental steps forward and that's what I'd like to see continuing. I want HIBP to outlive me, I just don't want it to become a burden I'm beholden to in the process. I'd like to have more people involved but as you can see from above, that's been a very slow process with only those very close to me playing a role.
The only thing I have real certainty on at the moment is that there will be more breaches. I've commented many times recently that the scourge that is ransomware feels like it's really accelerated lately, I wonder how many of the people in the emails and documents and all sorts of other data that get dumped there ever learn of their exposure? It's a non-trivial exercise to index that (for all sorts of reasons), but it also seems like an increasingly worthy exercise. Who knows, let's see how I feel when I get up tomorrow morning 🙂
Finally, for this week's regular video, I'm going to make a birthday special and do it live with Charlotte. Please come and join us, I'm not entirely sure what we'll cover (I'll work it out on the morning!) but let's make a virtual 10th birthday party out of it 🎂
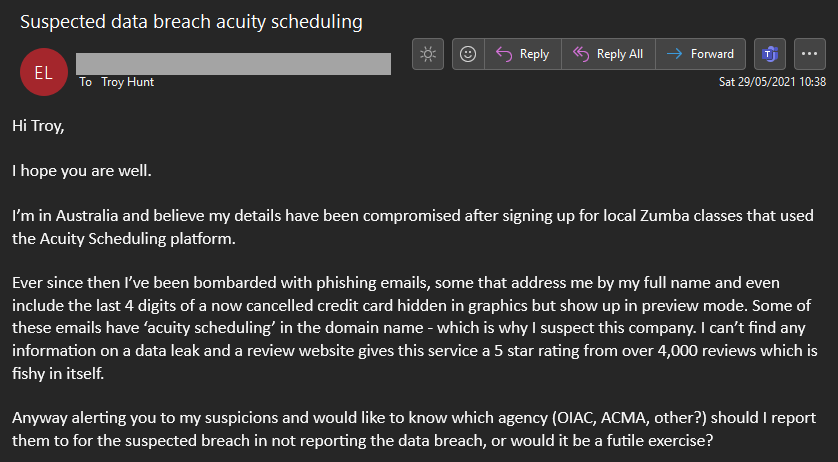
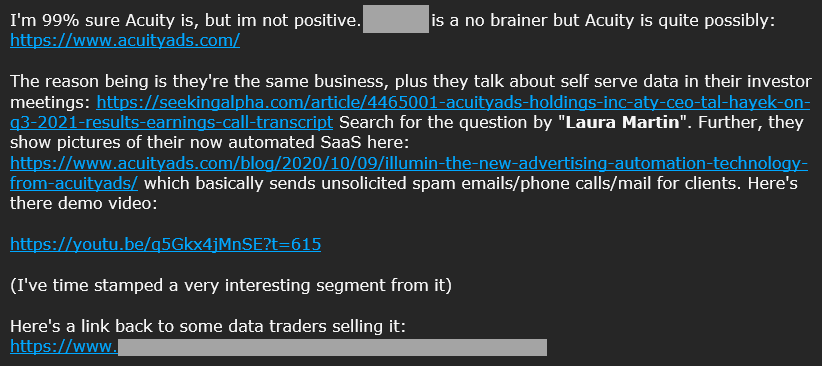
Allegedly, Acuity had a data breach. That's the context that accompanied a massive trove of data that was sent to me 2 years ago now. I looked into it, tried to attribute and verify it then put it in the "too hard basket" and moved onto more pressing issues. It was only this week as I desperately tried to make some space to process yet more data that I realised why I was short on space in the first place:
Ah, yeah - Acuity - that big blue 437GB blob. What follows is the process I went through trying to work out what an earth this thing is, the confusion surrounding the data, the shady characters dealing with it and ultimately, how it's now searchable in Have I Been Pwned (HIBP), which may be what brought you to this blog post in the first place.
That's not about healthcare, that's Acuity Brands. How many companies called "Acuity" that have been breached are there?! Let's see what references I have in my email:
Another one 🤦♂️ That "breach" could be circumstantial, so we'll call it a "maybe", but it's yet another Acuity with a question mark next to it. So how many "Acuity" companies are out there in total?! Just in the course of investigating this data, I came across a total of 6 of them that as far as I can tell, are completely unrelated:
Ugh, great. We'll work through them and try to figure out where they fit into the picture in a moment, but first let's look at the actual data. We already know it's 437GB, but it's the breadth of column headings that's most stunning; here's all 414 of them:
Just by eyeballing these, it really doesn't feel like the sort of data that comes from a healthcare provider, a brands company or a scheduler. The other 3, however... Maybe.
Some more data points before going further:
The files is named "ACUITY_MASTER_18062020.csv" (this is the date I've elected to stamp the breach with - 18 June 2020)
There are 21,873,706 email addresses in the file
Of those, "only" 14,055,729 are unique so there's some redundancy
The data is cleansed and formatted in a fashion that definitely isn't reflective of how data is entered by end users
On that final point, here's an example of what I'm talking about:
The last names are the same, as are the salutations. The physical addresses are spot on accurate in their structure as are the phone numbers; there are no spaces, no dashes and no other artifacts typical of millions of different humans entering data. This is clean - too clean.
The "datasource" field is another interesting data point with the top 10 values being:
Buy.com
Popularliving.com
studentsreview.com
TAGGED.COM
jamster.com
Expedia.com
cbsmarketwatch.com
netflix.com
selfwealthsystem.com
gocollegedegree.com
Each of these entries appeared at least hundreds of thousands of times, if not millions. Does that mean that Netflix, for example, provided customer data to this list? Almost certainly no, but it does feel reminiscent of the Acxiom / Live Ramp misattribution post I wrote a year ago where I listed full counts of a similar column. One of the top values there was also "TAGGED.COM" (also all in uppercase), alongside several other values that also appeared in both sources.
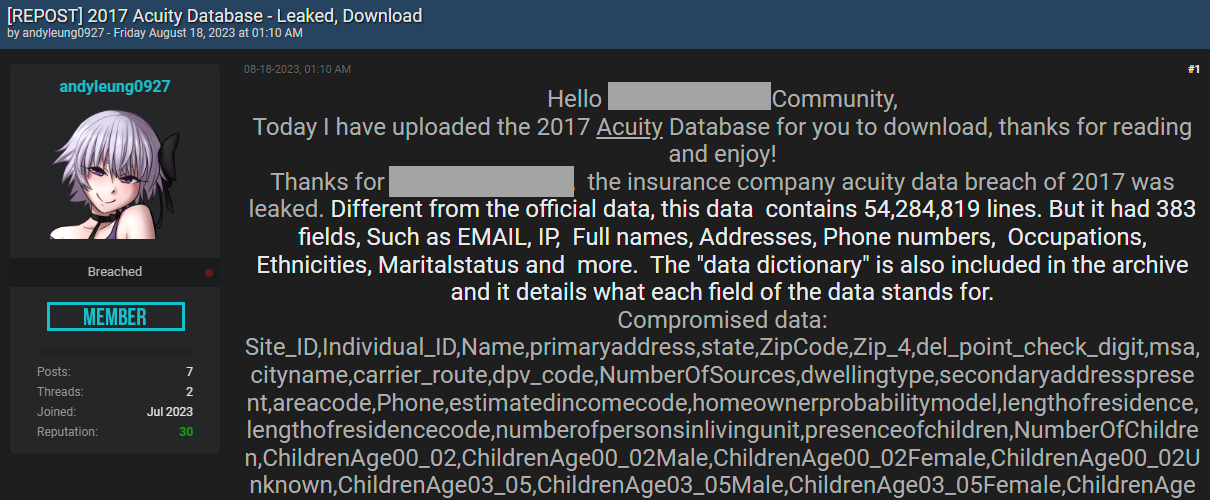
Back to attribution and a post on a popular hacking forum jumps out:
Many things here line up, for example the column names that are very unique to this data source, including "estimatedincomecode", "del_point_check_digit" and "secondaryaddresspresent". The attribution is to the insurance company named "Acuity", but is that accurate? Insurance companies collect a lot of data as it's relevant to how they run their business, but that data is highly unlikely to include fields such as:
SpectatorSportsBasketball
SewingKnittingNeedlework
PresenceOfUpscaleRetailCard
That's much more in the "data enrichment" space where a company sells a massive data set so that it can expand the profile data of the purchaser's existing customer base. It's a legitimate, honest, legal business model. It's also indistinguishable from this:
Hey, it's 437GB! And the column names line up! And it's called Acuity! Slightly different column count to mine (and similar but different to the hacker forum post), and slightly different email count, but the similarities remain striking. How I got to this resource is also interesting, having come by someone I was discussing the data with a couple of years ago:
The YouTube video is a walkthrough of a campaign management tool to send emails to customers. Could that indicate the data as coming from Acuity Ads (now Illumin)? No, not in and of itself, the walkthrough there isn't that dissimilar to other campaign tools I've used in the past. No matter how much I looked, I just couldn't find a solid lead back to Acuity Ads and anything even remotely related was merely circumstantial. It could be from them, but it could also be from many other places and the mere fact that a near identical corpus of data was sitting there on an outright spam site only makes the whole mystery that much deeper. There was just one more interesting data point in that email:
i myself am in that dataset and i've been getting 100x more phishing/scam calls, emails, and physical mail
Let me end this with a best guess: this feels like the same situation as the massive Master Deeds incident in South Africa in 2017. In that case, a legally operating data aggregator (I think you know how I feel about those by now...) sold personal information to a real estate business who then left it publicly exposed. I say it feels the same because it's just such a clean set of data and it's clearly very comprehensive in terms of the columns. It's exactly what I'd expect a data aggregator to prepare and sell to other businesses so they could identify which of their existing customers likes needlework.
In the past, publishing blog posts like this has helped identify an origin service and if that happens again here then I'll be sure to provide an update. For now, I've loaded it into HIBP and flagged it as a spam list which means it won't impact the size of anyone's domains and bump them into a different subscription level. If you do have any interesting insights on this data, please leave a comment below and with any luck, one of the Acuity entities out there will emerge as the source.
Note: just after loading the data, I ran the calcs on how many of the addresses were pre-existing in HIBP. This seems like a statistically significant number 😲
So, 100% (just under actually, but it rounded up). Working through a bunch of sample addresses, they appeared across all sorts of other existing spam lists and dodgy data aggregator breaches. Who knows which ones came first, just more data in the big swimming pool of breaches. https://t.co/Ux2rw6uaAk
I like to think of investigating data breaches as a sort of scientific search for truth. You start out with a theory (a set of data coming from an alleged source), but you don't have a vested interested in whether the claim is true or not, rather you follow the evidence and see where it leads. Verification that supports the alleged source is usually quite straightforward, but disproving a claim can be a rather time consuming exercise, especially when a dataset contains fragments of truth mixed in with data that is anything but. Which is what we have here today.
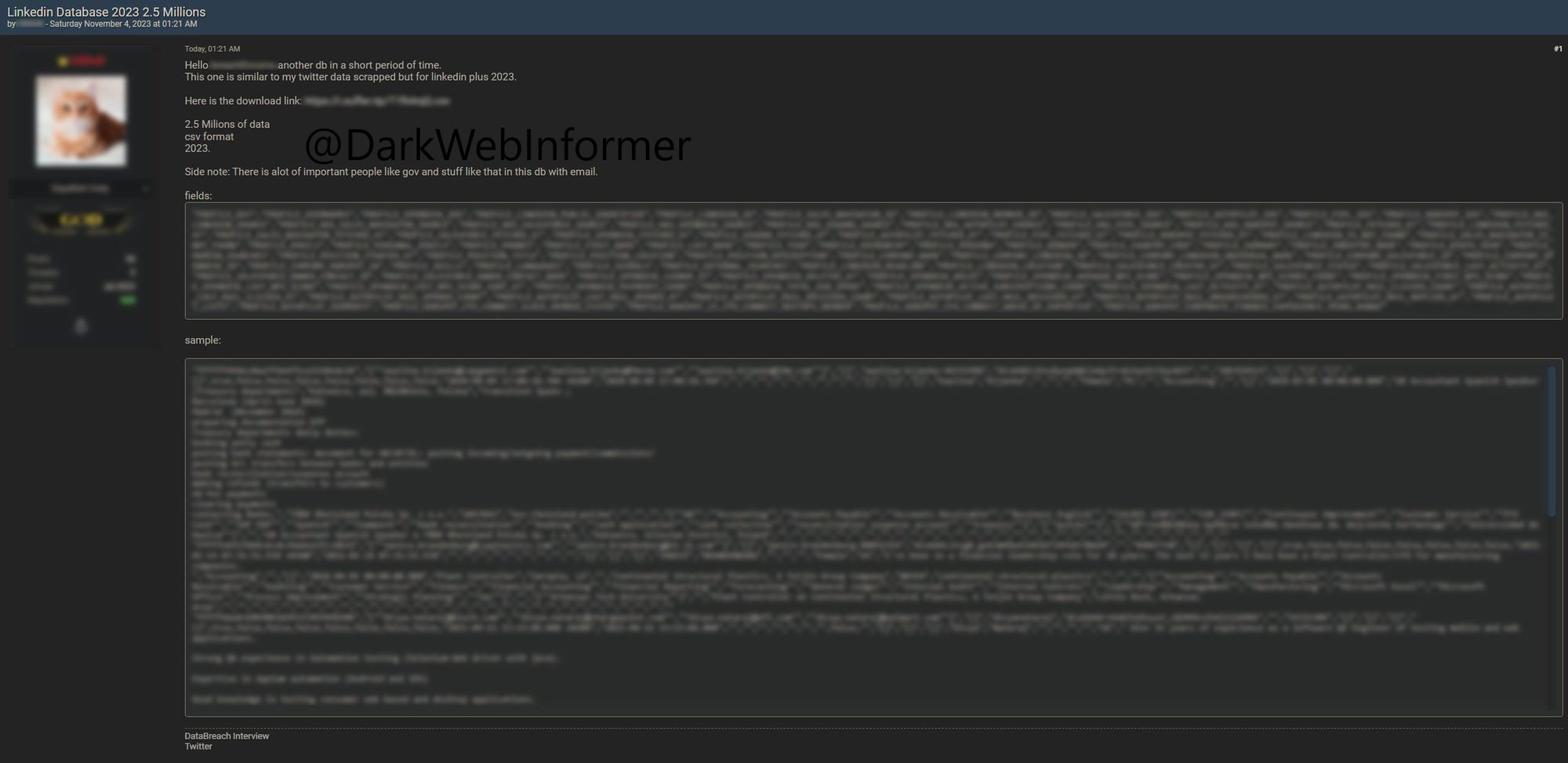
To lead with the conclusion and save you reading all the details if you're not inclined, the dataset so many people flagged me this week titled "Linkedin Database 2023 2.5 Millions" turned out to be a combination of publicly available LinkedIn profile data and 5.8M email addresses mostly fabricated from a combination of first and last name. It all began with this tweet:
All good lies are believable at face value; is it feasible a massive corpus of LinkedIn data is floating around? Well, they were proper breached in 2012 to the tune of 164M records (by which I mean that incident was genuinely internal data such as email addresses and passwords extracted out by a vulnerability), then they were massively scraped in 2021 with another 126M records going into Have I Been Pwned (HIBP). So, when you see a claim like the one above, it seems highly feasible at face value which is what many people take it at. But I'm a bit more suspicious than most people 🙂
First, the claim:
This one is similar to my twitter data scrapped [sic] but for linkedin plus 2023
Now, there's a whole debate about whether scraped data is breached data and indeed whether the definition of it even matters. With the rising prevalence of scraped data, this topic came up enough that I wrote a dedicated blog post about it a couple of years ago and concluded the following in terms of how we should define the term "breach":
A data breach occurs when information is obtained by an unauthorised party in a fashion in which it was not intended to be made available
Which makes scrapes like this alleged one a breach. If indeed it was accurate, LinkedIn data had been taken and redistributed in a way it was never intended to be by either the service itself or the individuals whose data was in this corpus. So, it's something to take seriously, and that warranted further investigation.
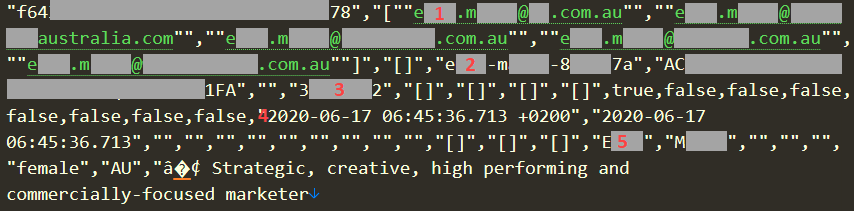
I scrolled through the 10M+ rows of data (many records spanned multiple rows due to line returns), and my eyes fell on a fellow Aussie who for the purposes of this exercise we'll call "EM", being the initials of her first and last name. Whilst the data I'm going to refer to is either public by design or fabricated, I don't want to use a real person as an example without their consent so let's just play it safe. Here's a fragment of EM's record:
There are 5 noteworthy parts of this I that immediately caught my attention:
There are 5 different email addresses here with the alias for each one represented in "[first name].[last name]@" form. These exist in a column titled "PROFILE_USERNAMES". (Incidentally, this is why the headline of 2.5M accounts expands out to 5.8M email addresses as there are often multiple addresses per account.)
There's a LinkedIn profile ID in the form of "[first name]-[last name]-[random hexadecimal chars]" under a column titled "PROFILE_LINKEDIN_ID". That successfully loaded EM's legitimate profile at https://www.linkedin.com/in/[id]/
The numeric value in the "PROFILE_LINKEDIN_MEMBER_ID" column matched with the value on EM's profile from the previous point.
The 2 dates starting with "2020-" are in columns titled "PROFILE_FETCHED_AT" and "PROFILE_LINKEDIN_FETCHED_AT". I assume these are self-explanatory.
EM's first and last name, precisely as it appears in each of her 5 email addresses.
On its own, this record would be unremarkable. It'd be entirely feasible - this could very well be legit - except when you keep looking through the remainder of the data. A pattern quickly emerged and I'm going to bold it here because it's the smoking gun that ultimately indicates that a bunch of this data is fake:
Every single record with multiple email addresses had exactly the same alias on completely unrelated domains and it was almost always in the form of "[first name].[last name]@".
Representing email addresses in this fashion is certainly common, but it's far from ubiquitous, and that's easy to demonstrate. For example, I have tons of emails from Pluralsight so I dig one out from my friend "CU":
There's no dot, rather a dash. Every single real Pluralsight email address I looked at was a dash rather than a dot, yet when I delved into the alleged LinkedIn data and dig out another sample Pluralsight address, here's what I found:
That's not LM's real address because it has a dot instead of a dash. Every. Single. One. Is. Fake.
Let's try this the other way around and load up the existing breached accounts in HIBP for the domain of one of EM's alleged email addresses and see how they're formed:
That's definitely not the same format as EM's address, not by a long shot. And time and time again, the same pattern of addresses in the corpus of data in the original tweet emerged, drawing me to what seems to be a pretty logical conclusion:
Each email address was fabricated by taking the actual domain of a company the individual legitimately worked at and then constructing the alias from their name.
And these are legitimate companies too because every single LinkedIn profile I checked had all the cues of accurate information and each domain I checked in the corpus of data was indeed the correct one for the company they worked at. I imagine someone has effectively worked through the following logic:
Get a list of LinkedIn profiles whether that be by ID or username or simply parsing them out of crawler results
Scrape the profiles and pull down legitimate information about each individual, including their employment history
Resolve the domain for each company they worked at and construct the email addresses
Profit?
On that final point, what is the point? The data wasn't being sold in that original tweet, rather it was freely downloadable. But per the date on EM's profile, the data could have been obtained much earlier and previously monetised. And on that, the date wasn't constant across records, rather there was a broad range of them as recent as July last year and as old as... well, I stopped when the records got older than me. What is this?!
I suspect the answer may partly lie in the column headings which I've pasted here in their entirety:
Check out some of those names: LinkedIn is obviously there, but so is Salesforce and Spendesk and Hubspot, among others. This reads more like an aggregation of multiple sources than it does data solely scraped from LinkedIn. My hope is that in posting this someone might pop up and say "I recognise those column headings, they're from..." Who knows.
So, here's where that leaves us: this data is a combination of information sourced from public LinkedIn profiles, fabricated emails address and in part (anecdotally based on simply eyeballing the data this is a small part), the other sources in the column headings above. But the people are real, the companies are real, the domains are real and in many cases, the email addresses themselves are real. There are over 1.8k HIBP subscribers in the data set and this is folks that have double opted-in so they've successfully received an email to that address in the past. Further, when the data was loaded into HIBP there were nearly a million email addresses that were already in the system so evidently, they were addresses that had previously been in use. Which stands to reason because even if every address was constructed by an algorithm, the pattern is common enough that there'll be a bunch of hits.
Because the conclusion is that there's a significant component of legitimate data in this corpus, I've loaded it into HIBP. But because there are also a significant number of fabricated email addresses in there, I've flagged it as a spam list which means the addresses won't impact the scale of anyone's paid subscription if they're monitoring domains. And whilst I know some people will suggest it shouldn't go in at all, time and time again when I've polled the public about similar incidents the overwhelming majority of people have said "we want to know about it then we'll make up our own minds what action needs to be taken". And in this case, even if you find an email address on your domain that doesn't actually exist, that person who either currently works at your company or previously did has still had their personal data dumped in this corpus. That's something most people will still want to know.
Lastly, one of the main reasons I decided to invest hours into this today is that I loathe disinformation and I hate people using that to then make statements that are completely off base. I'm looking at my Twitter feed now and see people angry at LinkedIn for this, blaming an insider due to recent layoffs there, accusing them of mishandling our data and so on and so forth. No, not this time, the evidence has led us somewhere completely different.
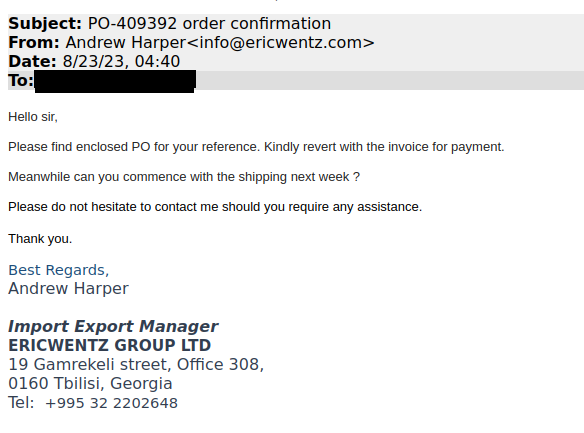
Last week I was contacted by CERT Poland. They'd observed a phishing campaign that had collected 68k credentials from unsuspecting victims and asked if HIBP may be used to help alert these individuals to their exposure. The campaign began with a typical email requesting more information:
In this case, the email contained a fake purchase order attachment which requested login credentials that were then posted back to infrastructure controlled by the attacker:
All in all, CERT Poland identified 202 other phishing campaigns using the same infrastructure which has subsequently been taken offline. Data accumulated by the malicious activity spanned from October 2022 until just last week.
The advice to impacted individuals is as follows:
Get a digital password manager to help you make all passwords strong and unique
If you've been reusing passwords, change them to strong and unique versions now, starting with the most important services you use
Turn on multi-factor authentication wherever it's available, especially for important accounts such as email, social media and banking
Never open attachments or follow links unless you're confident in the trustworthiness of their origin and if in doubt, delete the email
To disrupt the botnet, the FBI was able to redirect Qakbot botnet traffic to and through servers controlled by the FBI, which in turn instructed infected computers in the United States and elsewhere to download a file created by law enforcement that would uninstall the Qakbot malware
As part of the operation, the FBI have requested support from Have I Been Pwned (HIBP) to help notify impacted victims of their exposure to the malware. We provided similar support in 2021 with the Emotet botnet, although this time around with a grand total of 6.43M impacted email addresses. These are now all searchable in HIBP albeit with the incident is flagged as "sensitive" so you'll need to verify you control the email address via the notification service first, or you can search any domains you control via the domain search feature. Further, the passwords from the malware will shortly be searchable in the Pwned Passwords service which can either be checked online or via the API. Pwned Passwords is presently requested 5 and a half billion times each month to help organisations prevent people from using known compromised passwords.
Guidance for those impacted by this incident is the same tried and tested advice given after previous malware incidents:
There's a "hidden" API on HIBP. Well, it's not "hidden" insofar as it's easily discoverable if you watch the network traffic from the client, but it's not meant to be called directly, rather only via the web app. It's called "unified search" and it looks just like this:
It's been there in one form or another since day 1 (so almost a decade now), and it serves a sole purpose: to perform searches from the home page. That is all - only from the home page. It's called asynchronously from the client without needing to post back the entire page and by design, it's super fast and super easy to use. Which is bad. Sometimes.
The primary objective for putting a price on the public API was to tackle abuse. And it did - it stopped it dead. By attaching a rate limit to a key that required a credit card to purchase it, abusive practices (namely enumerating large numbers of email addresses) disappeared. This wasn't just about putting a financial cost to queries, it was about putting an identity cost to them; people are reluctant to start doing nasty things with a key traceable back to their own payment card! Which is why they turned their attention to the non-authenticated, non-documented unified search API.
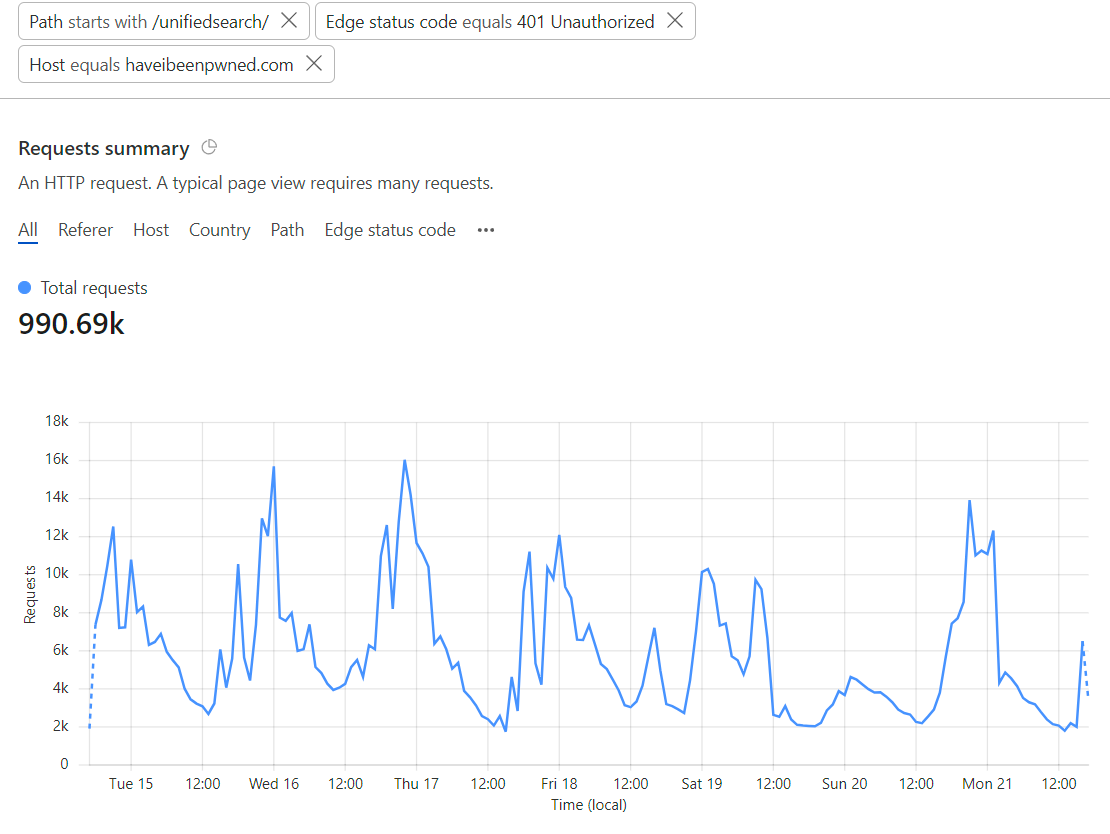
Let's look at a 3 day period of requests to that API earlier this year, keeping in mind this should only ever be requested organically by humans performing searches from the home page:
This is far from organic usage with requests peaking at 121.3k in just 5 minutes. Which poses an interesting question: how do you create an API that should only be consumed asynchronously from a web page and never programmatically via a script? You could chuck a CAPTCHA on the front page and require that be solved first but let's face it, that's not a pleasant user experience. Rate limit requests by IP? See the earlier problem with that. Block UA strings? Pointless, because they're easily randomised. Rate limit an ASN? It gets you part way there, but what happens when you get a genuine flood of traffic because the site has hit the mainstream news? It happens.
Over the years, I've played with all sorts of combinations of firewall rules based on parameters such as geolocations with incommensurate numbers of requests to their populations, JA3 fingerprints and, of course, the parameters mentioned above. Based on the chart above these obviously didn't catch all the abusive traffic, but they did catch a significant portion of it:
If you combine it with the previous graph, that's about a third of all the bad traffic in that period or in other words, two thirds of the bad traffic was still getting through. There had to be a better way, which brings us to Cloudflare's Turnstile:
With Turnstile, we adapt the actual challenge outcome to the individual visitor or browser. First, we run a series of small non-interactive JavaScript challenges gathering more signals about the visitor/browser environment. Those challenges include, proof-of-work, proof-of-space, probing for web APIs, and various other challenges for detecting browser-quirks and human behavior. As a result, we can fine-tune the difficulty of the challenge to the specific request and avoid ever showing a visual puzzle to a user.
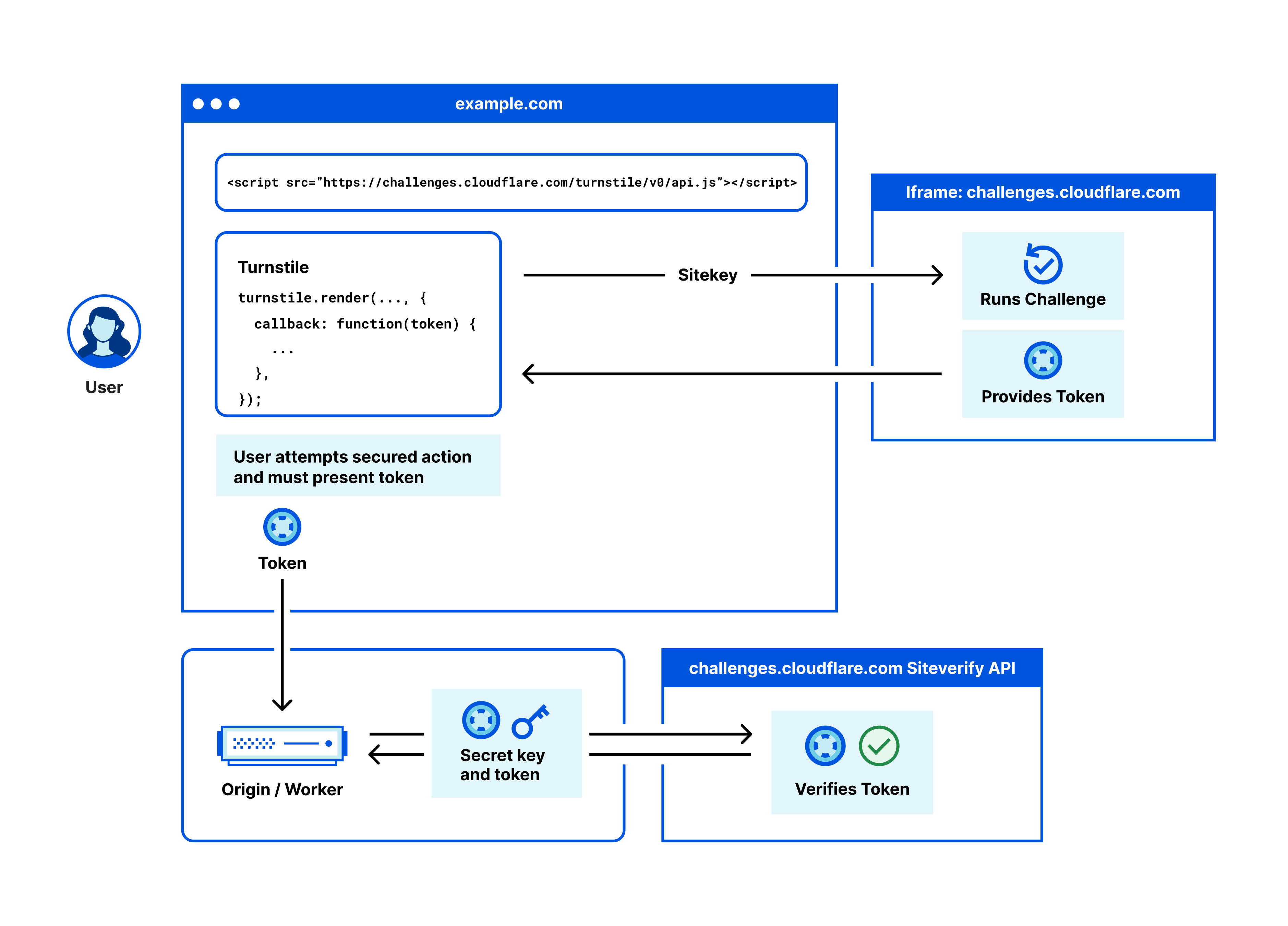
"Avoid ever showing a visual puzzle to a user" is a polite way of saying they avoid the sucky UX of CAPTCHA. Instead, Turnstile offers the ability to issue a "non-interactive challenge" which implements the sorts of clever techniques mentioned above and as it relates to this blog post, that can be an invisible non-interactive challenge. This is one of 3 different widget types with the others being a visible non-interactive challenge and a non-intrusive interactive challenge. For my purposes on HIBP, I wanted a zero-friction implementation nobody saw, hence the invisible approach. Here's how it works:
Get it? Ok, let's break it down further as it relates to HIBP, starting with when the front page first loads and it embeds the Turnstile widget from Cloudflare:
The widget takes responsibility for running the non-interactive challenge and returning a token. This needs to be persisted somewhere on the client side which brings us to embedding the widget:
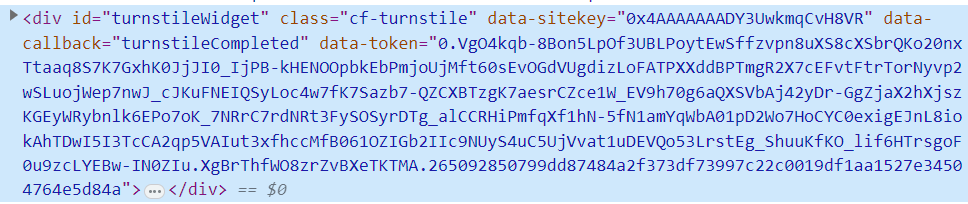
Per the docs in that link, the main thing here is to have an element with the "cf-turnstile" class set on it. If you happen to go take a look at the HIBP HTML source right now, you'll see that element precisely as it appears in the code block above. However, check it out in your browser's dev tools so you can see how it renders in the DOM and it will look more like this:
Expand that DIV tag and you'll find a whole bunch more content set as a result of loading the widget, but that's not relevant right now. What's important is the data-token attribute because that's what's going to prove you're not a bot when you run the search. How you implement this from here is up to you, but what HIBP does is picks up the token and sets it in the "cf-turnstile-response" header then sends it along with the request when that unified search endpoint is called:
So, at this point we've issued a challenge, the browser has solved the challenge and received a token back, now that token has been sent along with the request for the actual resource the user wanted, in this case the unified search endpoint. The final step is to validate the token and for this I'm using a Cloudflare worker. I've written a lot about workers in the past so here's the short pitch: it's code that runs in each one of Cloudflare's 300+ edge nodes around the world and can inspect and modify requests and responses on the fly. I already had a worker to do some other processing on unified search requests, so I just added the following:
const token = request.headers.get('cf-turnstile-response');
if (token === null) {
return new Response('Missing Turnstile token', { status: 401 });
}
const ip = request.headers.get('CF-Connecting-IP');
let formData = new FormData();
formData.append('secret', '[secret key goes here]');
formData.append('response', token);
formData.append('remoteip', ip);
const turnstileUrl = 'https://challenges.cloudflare.com/turnstile/v0/siteverify';
const result = await fetch(turnstileUrl, {
body: formData,
method: 'POST',
});
const outcome = await result.json();
if (!outcome.success) {
return new Response('Invalid Turnstile token', { status: 401 });
}
That should be pretty self-explanatory and you can find the docs for this on Cloudflare's server-side validation page which goes into more detail, but in essence, it does the following:
Gets the token from the request header and rejects the request if it doesn't exist
Sends the token, your secret key and the user's IP along to Turnstile's "siteverify" endpoint
If the token is not successfully verified then return 401 "Unauthorised", otherwise continue with the request
And because this is all done in a Cloudflare worker, any of those 401 responses never even touch the origin. Not only do I not need to process the request in Azure, the person attempting to abuse my API gets a nice speedy response directly from an edge node near them 🙂
So, what does this mean for bots? If there's no token then they get booted out right away. If there's a token but it's not valid then they get booted out at the end. But can't they just take a previously generated token and use that? Well, yes, but only once:
If the same response is presented twice, the second and each subsequent request will generate an error stating that the response has already been consumed.
And remember, a real browser had to generate that token in the first place so it's not like you can just automate the process of token generation then throw it at the API above. (Sidenote: that server-side validation link includes how to handle idempotency, for example when retrying failed requests.) But what if a real human fails the verification? That's entirely up to you but in HIBP's case, that 401 response causes a fallback to a full page post back which then implements other controls, for example an interactive challenge.
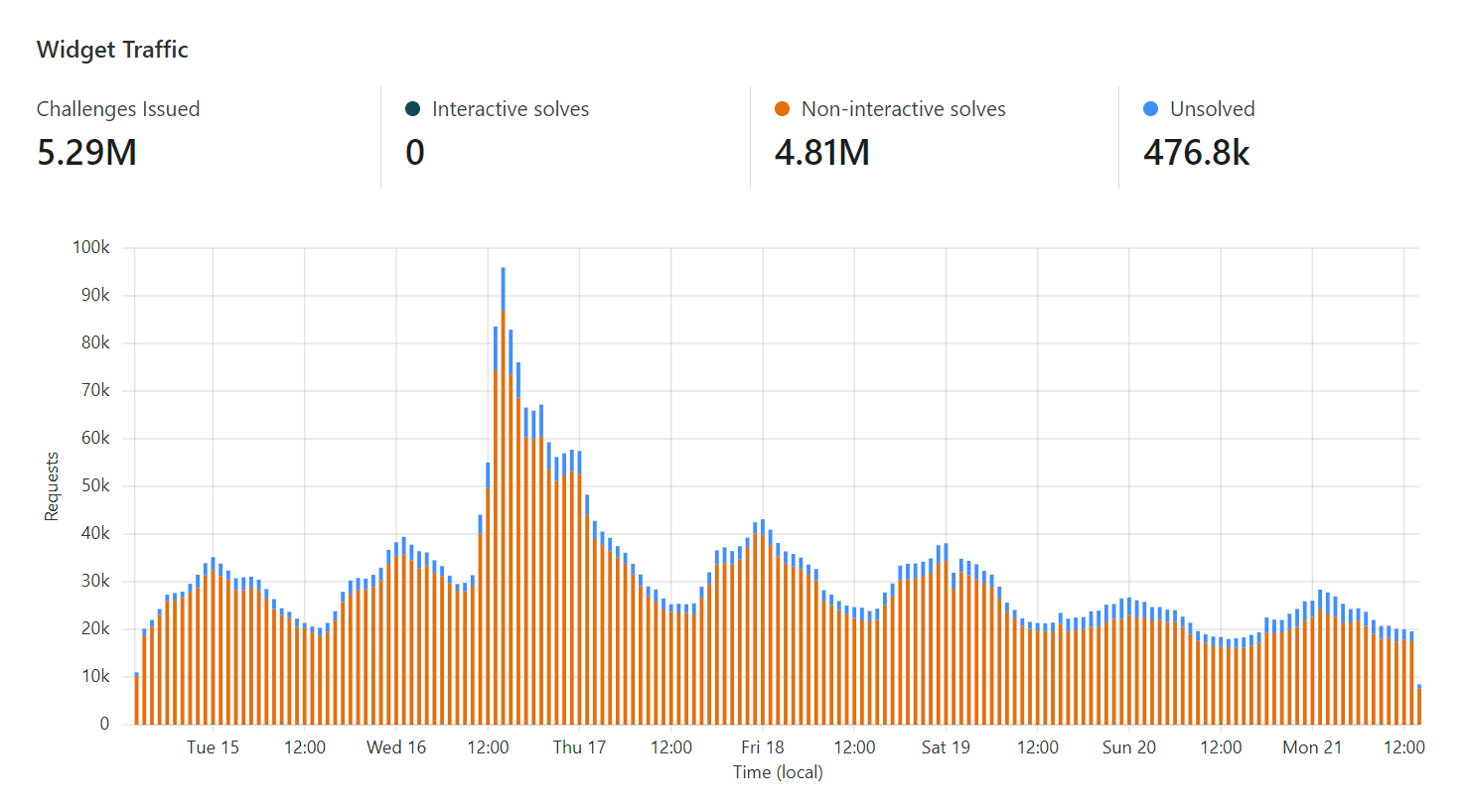
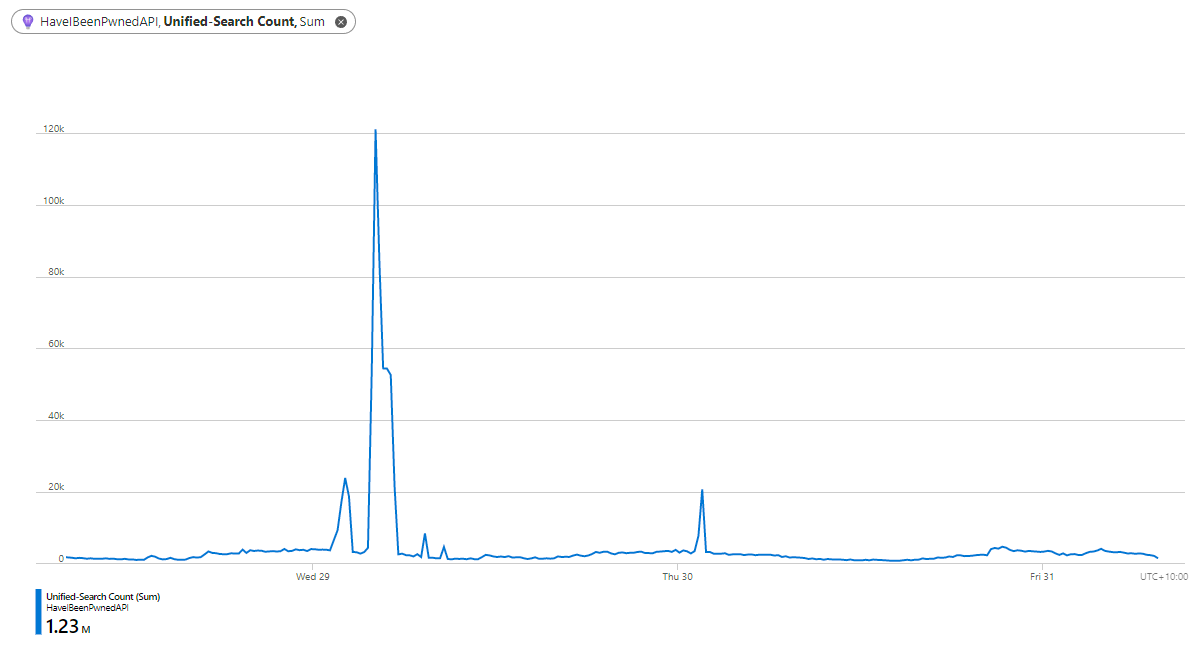
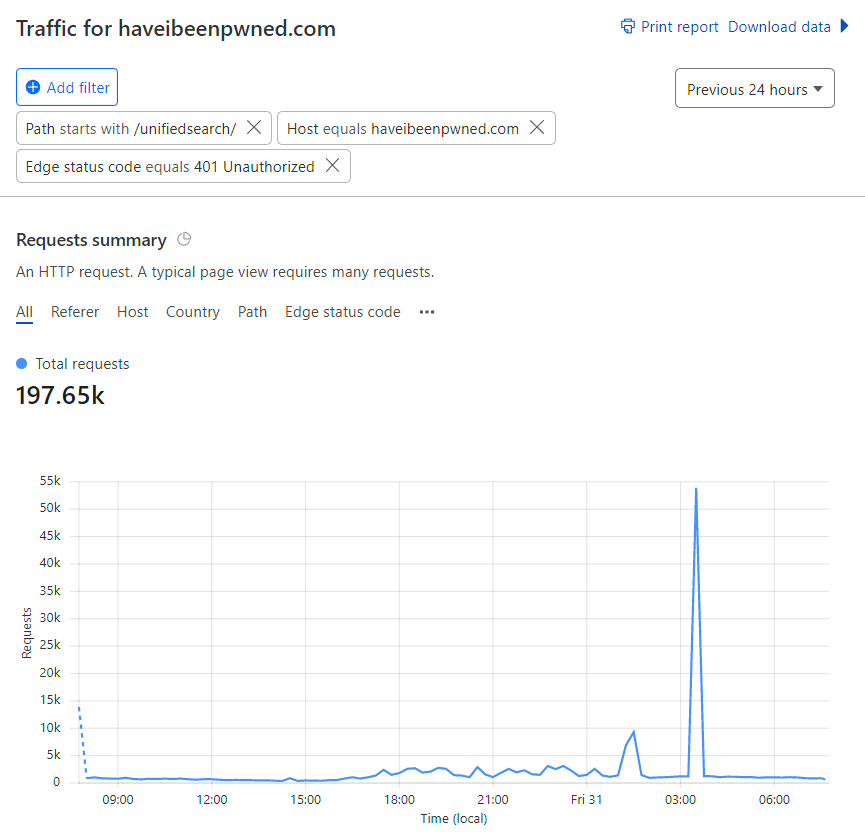
Time for graphs and stats, starting with the one in the hero image of this page where we can see the number of times Turnstile was issued and how many times it was solved over the week prior to publishing this post:
That's a 91% hit rate of solved challenges which is great. That remaining 9% is either humans with a false positive or... bots getting rejected 😎
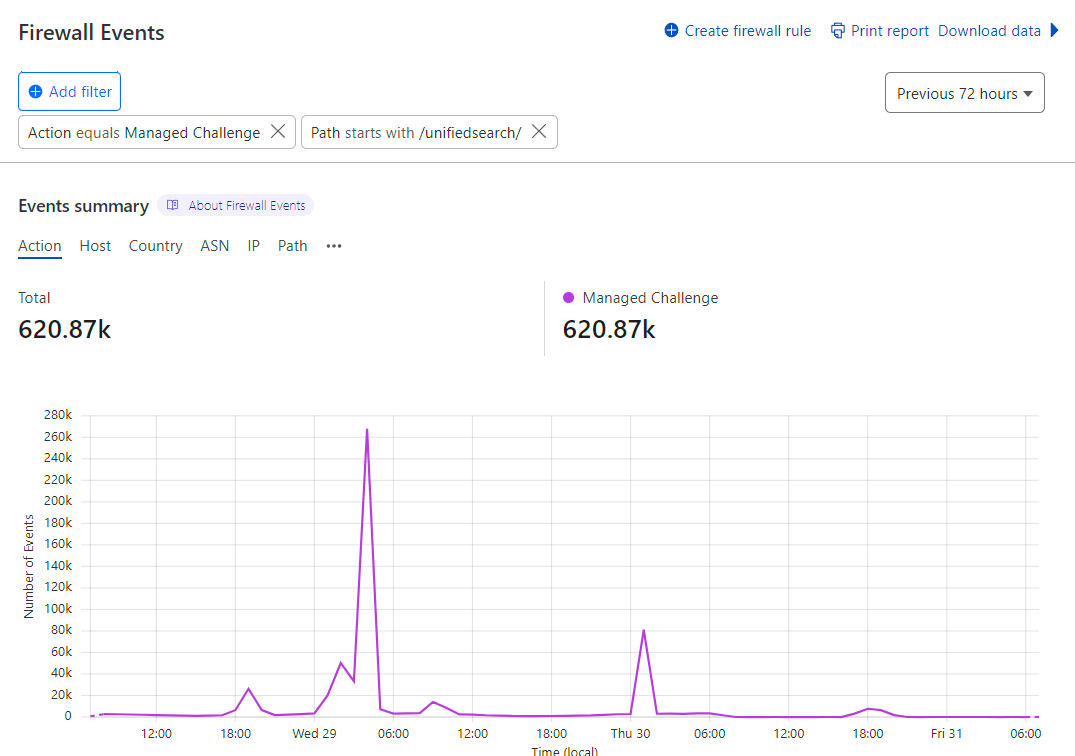
More graphs, this time how many requests to the unified search page were rejected by Turnstile:
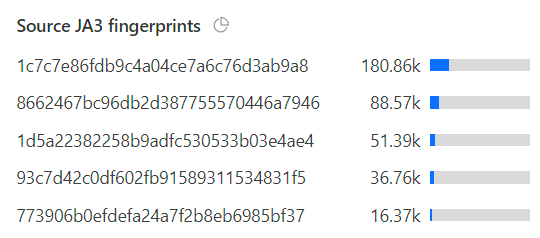
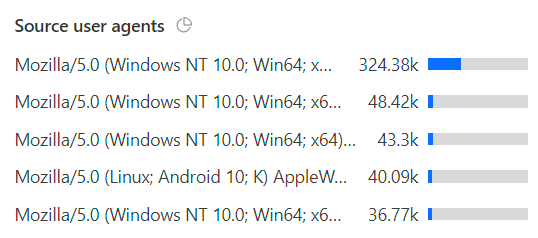
That 990k number doesn't marry up with the 476k unsolved ones from before because they're 2 different things: the unsolved challenges are when the Turnstile widget is loaded but not solved (hopefully due to it being a bot rather than a false positive), whereas the 401 responses to the API is when a successful (and previously unused) Turnstile token isn't in the header. This could be because the token wasn't present, wasn't solved or had already been used. You get more of a sense of how many of these rejected requests were legit humans when you drill down into attributes like the JA3 fingerprints:
In other words, of those 990k failed requests, almost 40% of them were from the same 5 clients. Seems legit 🤔
And about a third were from clients with an identical UA string:
And so on and so forth. The point being that the number of actual legitimate requests from end users that were inconvenienced by Turnstile would be exceptionally small, almost certainly a very low single-digit percentage. I'll never know exactly because bots obviously attempt to emulate legit clients and sometimes legit clients look like bots and if we could easily solve this problem then we wouldn't need Turnstile in the first place! Anecdotally, that very small false positive number stacks up as people tend to complain pretty quickly when something isn't optimal, and I implemented this all the way back in March. Yep, 5 months ago, and I've waited this long to write about it just to be confident it's actually working. Over 100M Turnstile challenges later, I'm confident it is - I've not seen a single instance of abnormal traffic spikes to the unified search endpoint since rolling this out. What I did see initially though is a lot of this sort of thing:
By now it should be pretty obvious what's going on here, and it should be equally obvious that it didn't work out real well for them 😊
The bot problem is a hard one for those of us building services because we're continually torn in different directions. We want to build a slick UX for humans but an obtrusive one for bots. We want services to be easily consumable, but only in the way we intend them to... which might be by the good bots playing by the rules!
I don't know exactly what Cloudflare is doing in that challenge and I'll be honest, I don't even know what a "proof-of-space" is. But the point of using a service like this is that I don't need to know! What I do know is that Cloudflare sees about 20% of the internet's traffic and because of that, they're in an unrivalled position to look at a request and make a determination on its legitimacy.
If you're in my shoes, go and give Turnstile a go. And if you want to consume data from HIBP, go and check out the official API docs, the uh, unified search doesn't work real well for you any more 😎