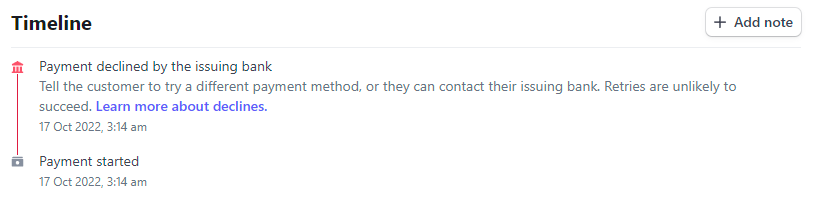
I've been investing a heap of time into Have I Been Pwned (HIBP) lately, ranging from all the usual stuff (namely trawling through masses of data breaches) to all new stuff, in particular expanding and enhancing the public API. The API is actually pretty simple: plug in an email address, get a result, and that's a very clearly documented process. But where things get more nuanced is when people pay money for it because suddenly, there are different expectations. For example, how do you cancel a subscription once it's started? You could read the instructions when signing up for a key, but who remembers what they read months ago? There's also a greater expectation of support for everything from how to construct an API request to what to do when you keep getting 429 responses because you're (allegedly) making too many requests. And yes, some of these queries are, um, "basic", but they're still things people want support with.
In the beginning, all emails from HIBP came from noreply@haveibeenpwned.com because I simply wasn't geared up to provide support. In my naivety, I assumed people would see "noreply" and not reply. Instead, they'd send email to that address, get frustrated when there was no reply (from the "noreply" address...) and seek out my personal contact info. Or they'd lodge a dispute with Stripe because they'd emailed noreply@ asking for their subscription to be cancelled and it wasn't. So, back in September I started looking for a better solution:
I’m thinking of setting up a more formal support process for @haveibeenpwned, especially for folks buying API keys and having queries around billing or implementation. Any suggestions on a service? Something that can triage requests, perhaps also have FAQs. Thoughts?
This was a non-trivial exercise. We've all used support services before, so we have an idea of what to expect from an end user perspective, but it's a different story once you dive into all the management bits behind them. Frankly, I find this sort of thing mind-numbing but fortunately it's a task my amazing wife Charlotte picked up with gusto. She has become increasingly involved in all things troyhunt.com and HIBP lately as she brings order, calm and frankly, much needed sanity into my otherwise crazy, demanding professional life. We also figured that if we did this right, she'd be able to handle a lot of the support queries I previously did myself, so she was always going to play a big part in choosing the support platform.
Largely based on Charlotte's work, we settled on Zendesk and about a week ago, silently pushed out support.haveibeenpwned.com:
There are FAQs that cover a bunch of frequent questions, troubleshooting that addresses common problems and, of course, the ability to submit a request if you still need help. These are all a work in progress, and we'll add a lot more content in response to queries, just so long as they're about the right thing. Speaking of which:
This service is only for users of the public commercial API key, not for general HIBP queries.
Is that even a query?! I don't know! But I do know that someone took the time to track down my personal email address this week and send it to me, and it's not the sort of thing we're going to be responding to on Zendesk. Nor are queries along the lines of the following:
I've been pwned, now what?
Or:
How do I remove my data from data breaches?
Or one of my personal favourites:
I demand you delete all my data from the data breaches or you'll get a letter from my lawyer!
This whole data breach landscape is a foreign concept for many people, and I understand there being questions, but Charlotte and I can't simultaneously run a free service and reply to queries like this from the masses. But the queries that come in via Zendesk are something we can manage as it's clearly scoped, there's lots of supporting docs and for the most part, we're dealing with tech professionals who understand this world a bit better than your average punter in the first place.
Just over 3 years ago now, I sat down at a makeshift desk (ok, so it was a kitchen table) in an Airbnb in Olso and built the authenticated API for Have I Been Pwned (HIBP). As I explained at the time, the primary goal was to combat abuse of the service and by adding the need to supply a credit card, my theory was that the bad guys would be very reluctant to, well, be bad guys. The theory checked out, and now with the benefit of several years of data, I can confidently say abuse is near non-existent. I just don't see it. Which is awesome 😊
But there were other things I also didn't see, and it's taken a while for me to get around to addressing them. Some of them are fixed now (like right now, already in production), and some of them will be fixed very, very soon. I think it's all pretty cool, let me explain:
Payments Can Be Hard... if You Don't Stripe Right
A little more background will help me explain this better: in the opening sentence of this blog post I mentioned building the original authenticated API out on a kitchen table at an Airbnb in Oslo. By that time, everyone knew I was going through an M&A process with HIBP I called Project Svalbard, which ultimately failed. What most people didn't know at the time was the other very stressful goings on in my life which combined, had me on a crazy rollercoaster ride I had little control over. It was in that environment that I created the authenticated API, complete with the Azure API Management (APIM) component and Stripe integration. It was rough, and I wish I'd done it better. Now, I have.
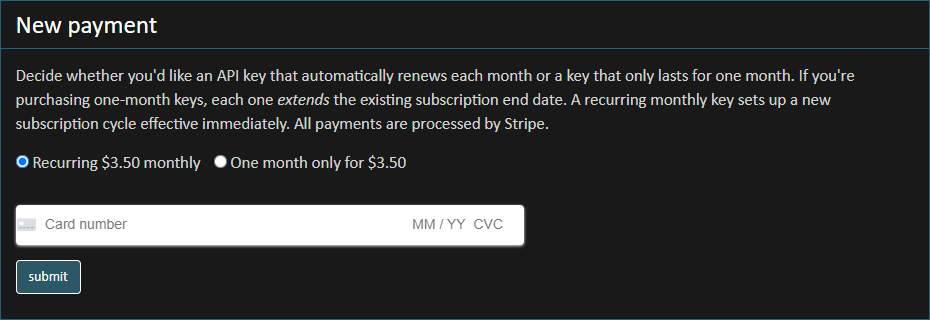
In the beginning, I pushed as much of the payment processing as possible to the HIBP website. This was due to a combination of me wanting to create a slick UX and frankly, not understanding Stripe's own UI paradigms. It looked like this:
Cards never ended up hitting HIBP directly, rather the site did a dance with Stripe that involved the card data going to them directly from the client side, a token coming back and then that being used for the processing. It worked, but it had numerous problems ranging from lack of support for things like 3D Secure payments, no support for other payments mechanisms such as Google Pay and Apple Pay and increasingly, large amounts of plumbing required to tie it all together. For example, there were hundreds of lines of code on my end to process payments, change the default card and show a list of previous receipts. The Stripe APIs are extraordinarily clever, but I couldn't escape writing large troves of my own code to make it work the way I originally designed it.
Two new things from Stripe since I originally wrote the code have opened up a whole new way of doing this:
Customer Portal: This is a fully hosted environment where payments are made, cards and subscriptions are managed, invoices and receipts are retrieved and basically, a huge amount of the work I'd previously hand-built can be managed by them rather than by me
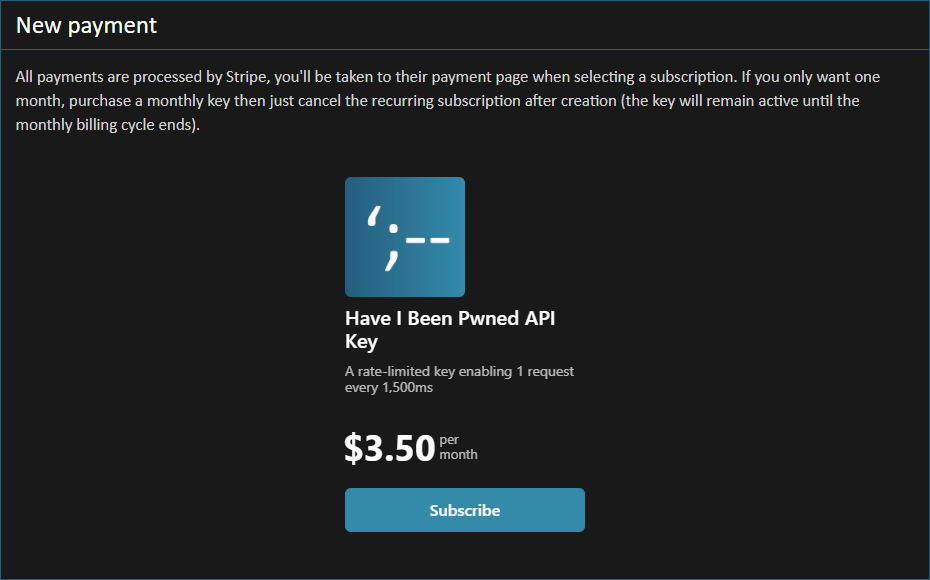
Embeddable Pricing Table: This brings the products and prices defined in Stripe into the UI of third party services (such as HIBP) such that customers can select their product then head off to Stripe and do the purchasing there
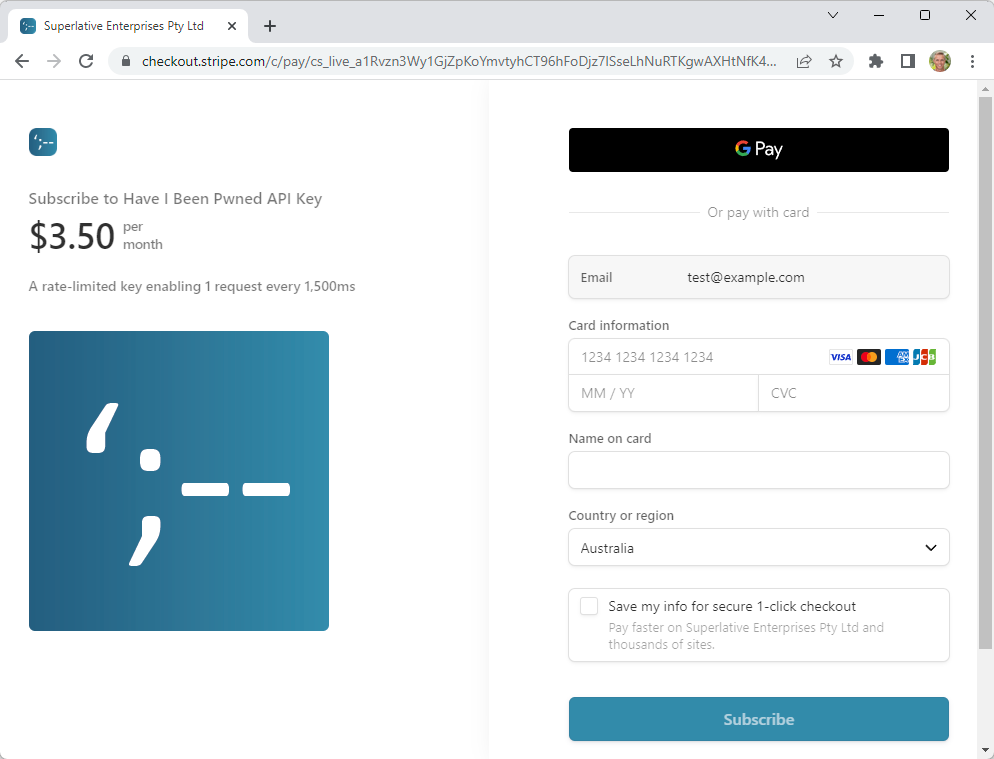
Rolling to these services removed a huge amount of code from HIBP with the bulk of what's left being email address verification, API key management and handling callbacks from Stripe when a payment is successful. What all this means is that when you first create a subscription, after verifying your email address, you see these two screens:
That's the embeddable pricing table following by Stripe's own hosted payment page. I left the browser address bar in the latter to highlight that this is served by Stripe rather than HIBP. I love distancing myself from any sort of card processing and what's more, everything to do with actually taking the payment is now Stripe's problem 😊 If you're interested in the mechanics of this, a successful payment calls a webhook on HIBP with the customer's details which updates their account with a month of API key whilst the screen above redirects them over to the HIBP website where they can grab their key. Easy peasy.
I silently rolled this out a week ago, watched it being used, made a few little tweaks and then waited until now to write about it. The rollout coincided with a typical email I've received so many times before:
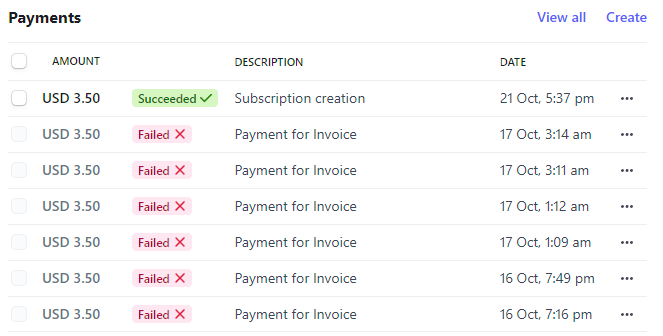
First of all I would like to thank you for the wonderful service that helps people to keep track of their email breaches. I was trying to build a product to provide your services via my website, something similar to Firefox, avast and 100's of other companies doing. We were trying to do it according to the guidelines mentioned in the website. However I am not able to renew my purchase due to payment gateway failures at stripe payment. Requesting you to kindly check the same and advise me on alternate methods for making the payment.
The old model often caused payments to be rejected, especially from subscribers in India. The painful thing for me when trying to help folks is that Stripe would simply report the failed payment as follows:
However, going back to the individual who raised the query above after rolling out this update, things changed very dramatically:
To the title of this section, I simply wasn't "Striping" right. I'm sure there's a way with enough plumbing that it's feasible, but why bother? I cut hundreds of lines of code out just by delegating more of the workload back to them. Further, with ever tightening PCI DSS standards (read Scott's piece, interesting stuff) the less I have to do with cards, the better.
This was a "penny drop" moment for me and it's already made a big difference in a positive way. But there's another penny that dropped for me at the same time: one-off keys were an unnecessary problem.
There Are No More One-Off Keys
It was at the moment I was ripping out those hundreds of lines of code that I wondered: why do I have all the additional kludge to support the paradigm of a one-off key that only lasts a month? Why had I built (and was now maintaining) server side code to handle different types of purchases and UX paradigms to represent one-off versus recurring keys? My gut feel was that most payments formed part of an ongoing subscription but hey, who needs gut feels when you have real data?! So I pulled the numbers:
Only 7% of payments were one-offs, with 93% of payments forming part of ongoing subscriptions.
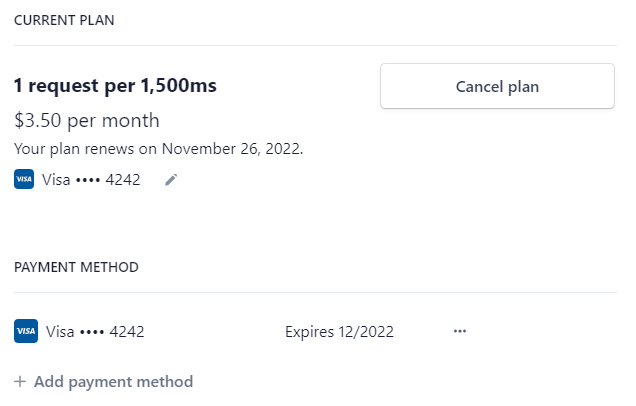
And so I killed the one-off keys. Kinda, because you can still have a key for only one month, you just purchase a monthly subscription then immediately cancel it via the Stripe Customer Portal:
That's linked into from the API key dashboard on HIBP and it'll take all of 5 seconds to do (also note the ability to change payment method directly on the Stripe site). I've added text to that effect on the HIBP website (you may have spotted that in the earlier screen cap) so in practice, the ability to purchase a one-off key is still there and the main upside of this is that I've just killed a trove of code I no longer have to worry about 🙂 Because this is the internet, I'm sure someone will still be upset, but if you only want a key for a month then that capability still well and truly exists.
All of this so far amounts to doing the same things that were always there but better. Now let's talk about the all new stuff!
Annual Billing and Different Rate Limits are Coming... Very Soon!
The title is self-explanatory and "very soon" is in about 2 weeks from now 😎
Let me illustrate the first part of that title with a message I received recently:
Is there a way to procure a 10 year API key? Our client wants to use the Have I been Pwned plugin for [redacted service name]; however, the $3.50 monthly subscription is too small to go through procurement.
What's that saying about no good deed going unpunished? In my naivety, I made the pricing low with the thinking that was a good thing, yet here we are with that posing barriers! This was a recurring message over and over again with folks simply struggling to get their $3.50 reimbursed. I should have seen this coming after years of living the corporate life myself (I have vivid flashbacks of how hard it was to get small sums reimbursed), and filling out an untold number of expense reports. Speaking of which, this was another recurring theme:
Is there a way to pay yearly for HIBP API access vs monthly? Monthly adds overhead in paperwork.
And again, I get it, this is a painful process. It somehow feels even more painful due to the fact the sum is so low; how much time are people burning trying to justify $3.50 to their boss?! It's painful, and this likely explains why the request for annual payments is the second most requested idea on HIBP's UserVoice. The comments there speak for themselves, and I'm having corporate PTSD flashbacks just reading them again now!
Sticking with the UserVoice theme, the 5th most requested feature is for different pricing on different rate limits. This is mostly self-explanatory but what I wasn't aware of until I went and pulled the stats was just how many people were hacking around the rate limit problem. There are heaps of API accounts like this:
Because there can only be one key per email address, organisations are creating heaps of unique sub-addressed emails in order to buy multiple keys. This would have been a manual, laborious process; there's no automated way to do this, quite the contrary with anti-automation controls built into the process. Further, each key has it's own rate limit so I imagine they were also building a bunch of plumbing in the back end to then distribute requests across a collection of keys which, yeah, I get it, but man that seems like hard work! When I say "a collection of keys", I'm not just talking about a few of them either; the largest number of active in-use keys by a single organisation is 112. One hundred and twelve! The next largest is 110. I never expected that 🤯 (Incidentally, these orgs and the others obtaining multiple keys are all precisely the kinds I want using the API to do good things.)
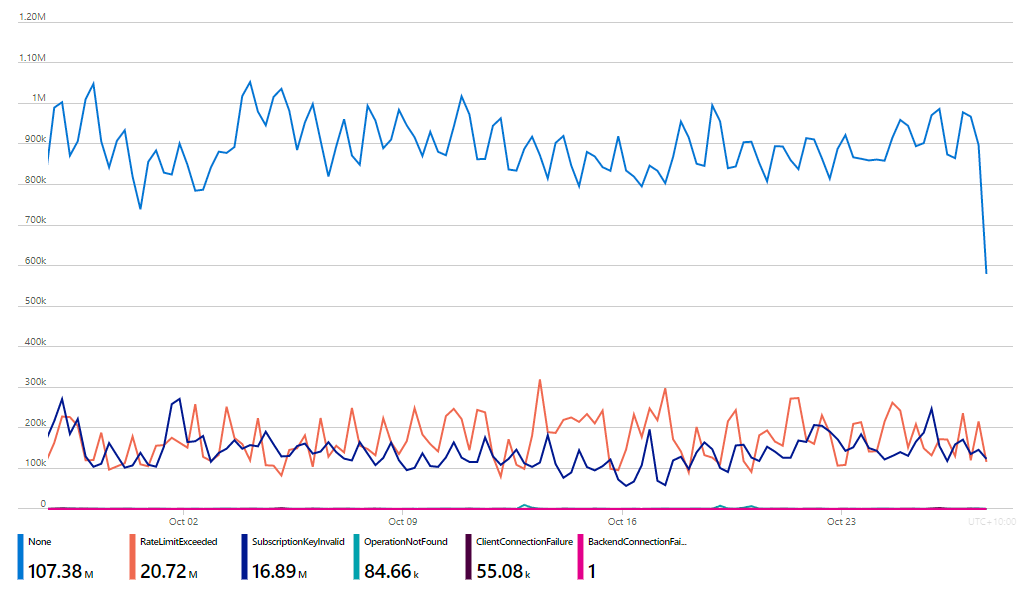
Building the mechanics of annual billing and different rate limits is only part of the challenge and most of that is already done, the harder part is pricing it. I'm pulling troves of analytics from APIM at present to better understand the usage patterns, and it's quite interesting to see the data as it relates to requests for the API:
There's no persistent logging of the actual queries themselves, but APIM makes it easy to understand both the volume of queries and how many of them are successful versus failed, namely because they exceed the existing rate limit or were made with an invalid (likely expired) key. So, that's what I need to work out over the next couple of weeks when I'll launch everything and write it up, as always, in detail 🙂
Summary
The HIBP API has become an increasingly important part of all sorts of different tools and systems that use the data to help protect people impacted by data breaches. The changes I've pushed out over the last week help make the service more accessible and easier to manage, but it's the coming changes I'm most excited about. These are the ones that will make life so much easier on so many people integrating the service and, I sincerely hope, will enable them to do things that make a much more profound impact on all of us who've been pwned before.
Continuing the rollout of Have I Been Pwned (HIBP) to national governments around the world, today I'm very happy to welcome Poland to the service! The Polish CSIRT GOV is now the 34th onboard the service and has free and open access to APIs allowing them to query their government domains.
Seeing the ongoing uptake of governments using HIBP to do useful things in the wake of data breaches is enormously fulfilling and I look forward to welcoming many more national CSIRTs in the future.
Four and a half years ago now, I rolled out version 2 of HIBP's Pwned Passwords that implemented a really cool k-anonymity model courtesy of the brains at Cloudflare. Later in 2018, I did the same thing with the email address search feature used by Mozilla, 1Password and a handful of other paying subscribers. It works beautifully; it's ridiculously fast, efficient and above all, anonymous. Yet from time to time, I get messages along the lines of this:
Why are you using SHA-1? It's insecure and deprecated.
Or alternatively:
Our [insert title of person who fills out paperwork but has no technical understanding here] says that k-anonymity involves sending you PII.
Both these positions make no sense whatsoever when you peel back the covers and understand what's happening underneath, but I get how on face value these conclusions can be drawn. So, let's settle it here in a more complete fashion than what I can do via short tweets or brief emails.
SHA-1 is Just Fine for k-Anonymity
Let's begin with the actual problem SHA-1 presents. Actually, the multiple problems, the first of which is that it's just way too fast for storing user passwords in an online system. More than a decade ago now, I wrote about how Our Password Hashing Has no Clothes and in that post, showed the massive rate at which consumer-grade hardware can calculate these hashes and consequently "crack" the password. Since that time, Moore's Law has done its thing many times over making the proposition of SHA-1 (or SHA-256 or SHA-512) even worse than before. For a modern day reference of how you should be storing passwords, check out OWASP's Password Storage Cheat Sheet.
The other problem relates to how SHA-1 is used for integrity checks. Hashing algorithms provide an efficient means of comparing two files and establishing if their contents is the same due to the deterministic nature of the algorithm (the same input always produces the same output). If a trustworthy source says "the hash of the file is 3713..42" (shown in abbreviated form) then any file with that same hash is assumed to be the same as the one described by the trustworthy source. We use hashes all over the place for precisely this purpose; for example, if I wanted to download Windows 11 Business Editions from my MSDN subscription, I can refer to the hash Microsoft provides on the download page:
After download, I can then use a utility such as PowerShell's Get-FileHash to verify that the file I downloaded is indeed the same one listed above. (There's another rabbit hole we can go down about how you trust the hash above, but I'll leave that for another post.)
We also use hashes when implementing subresource integrity (SRI) on websites to ensure external dependencies haven't been modified. Every time this very blog loads Font Awesome from Cloudflare's CDN, for example, it's verified against the hash in the integrity attribute of the script tag (view source for yourself).
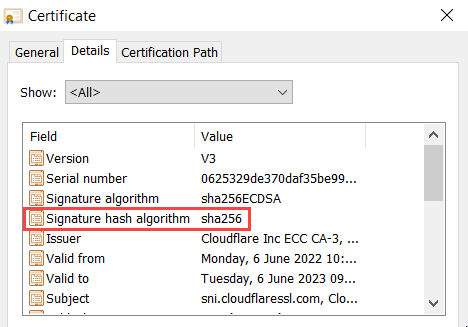
And finally (although not exhaustively - there are many other places we use hashing algorithms in tech), we use hashing algorithms on digital certificate signatures. To pick another example from this blog, the certificate issued by Cloudflare uses SHA-256 as the signature hash algorithm:
But ponder this: if a hashing algorithm always produces a fixed length output (in the case of SHA-1, it's 40 hexadecimal bytes), then there are a finite number of hashes in the world. In that SHA-1 example, the finite number is 16^40 as there are 16 possible values (0-9 and a-f) and 40 positions for them. But how many different input strings are there in the world? Infinite! So, there must be multiple input strings that produce the same output, and this is what we refer to as a "hash collision". It's possible for this to occur naturally, although it's exceedingly unlikely simply due to the massive number of possibilities 16^40 presents. However, what if you could manufacture a hash collision? I mean what if you could take an existing hash for an existing document and say "I'm going to create my own document that's different but when passed through SHA-1, produces the same hash!"?
Half a decade ago now, Google researchers demonstrated precisely this with their SHAttered attack. Their simple infographic tells the story:
And this is the heart of the integrity problem with SHA-1: it's simply past its used by date as an algorithm we can be confident in. That's why the signature hash algorithm of the TLS cert on this blog uses SHA-256 instead, among other examples of where we've eschewed the weaker algorithm in favour of stronger variants.
So, now that you understand the problem with SHA-1, let's look at how it's used in HIBP and why it isn't a problem there. There are actually 2 reasons, and I'll start with a sample of passwords used in Pwned Passwords:
P@ssw0rd
abc123
635,someone@example.com,+61430978216,37 example street
money
qwerty
That middle line isn't a password, it's a parsing problem. Not necessarily my parsing problem, it just turns out that you can't always trust hackers to dump breached data in a clean format 🤷♂️ So, instead of providing passwords to people in plain text format, I provide them as SHA-1 hashes:
4 of those hashes are easily cracked (Google is great at that, just try searching for the first one) and that's just fine; nobody is put at risk by learning that some unidentified party used a common password. The 1 hash that won't yield any search results (until Google indexes this blog post...) is the middle one. The fact that SHA-1 is fast to calculate and has proven hash collision attacks against its integrity doesn't diminish the purpose it serves in protecting badly parsed data.
The second reason is best explained by walking through the process of how the API is queried. Let's take an example of someone signing up to a website with the following password:
P@ssw0rd
This will pass many password complexity criteria (uppercase, lowercase, number, non-alphanumeric character, 8 chars long) but is clearly terrible. Because they're signing up to a responsible website that checks Pwned Passwords on registration, that website now creates a SHA-1 hash of the provided password:
21BD12DC183F740EE76F27B78EB39C8AD972A757
Let's pause here for a sec: whether it's a hash of a password or a hash of an email address, what we're looking at is a pseudonymous representation of the original data. There's no anonymity of substance achieved here because in the specific case above, you can simply Google the hash and in the case of an email address, you can determine with near certainty (hash collisions aside), if a given plain text email address is the one used to generate the hash.
This, however, is a different story:
21BD1
This is the first 5 bytes only of the hash and it's passed to the Pwned Passwords API as follows:
What we're looking at here is the hash suffix of every hash that begins with 21BD1 followed by the number of times that password has been seen. Turns out that "P@ssw0rd" ain't a great choice as it's the one in the middle that's been seen over 83k times. The consumer of the Pwned Passwords service knows it's this one because when combined with the prefix, it's a perfect match to the full hash of the password. I'll touch more on the mathematical properties of this in a moment, for now I want to explain the second reason why SHA-1 is used:
SHA-1 makes it very easy to segment the entire corpus of hashes into roughly equal equivalent sized chunks that can be queried by prefix. As I already touched on, there are 16^5 different possible hash prefixes which is specifically 1,048,576 or "roughly a million". Not every hash prefix has 788 associated suffixes, some have more and others less but if we take that as an average, that explains how the approximately 850M passwords in the service are divided down into a million smaller collections.
Why the first 5 bytes? Because if it was the first 4 then each response would be 16 times larger and it would start hurting response times. If it was the first 6 then each response would be 16 times smaller and it would start hurting anonymity. 5 characters was the sweet spot between the two.
Why not SHA-256? Instead of 40 bytes each hash would be 64 bytes and whilst I could have achieved the same anonymity properties by still just using the first 5 characters of the hash, each suffix in the response would be an additional 24 bytes and multiplying that 788 times over adds multiple kb to each response, even when compressed on the transport layer. It's also a slower hashing algorithm; still totally unsuitable for storing user passwords in an online system, but it can have a hit on the consuming service if doing huge amounts of calculations. And for what? Integrity doesn't matter because there's no value in modifying the source password to forge a colliding hash. You'd further increase the anonymity by 16^24 more possibilities, but then why not use SHA-512 which is 128 bytes therefore another 16^64 possibilities than even SHA-256? Because, as you'll read in the next section, even SHA-1 provides way more practical anonymity than you'll ever need anyway.
In summary, think of the choice of SHA-1 simply being to obfuscate poorly parsed input data to protect inadvertently included info, and as a means of dividing the collection of data down into nice easily segmentable and queryable collections. If your position is "SHA-1 is broken", then you simply don't understand its purpose here.
PII and the Protection Provided by k-Anonymity
Let's turn the discussion more to the privacy aspects of the email address search I mentioned earlier on. The principles are identical to the password search but for one difference in the technical implementation: queries are done on the first 6 bytes of a SHA-1 hash, not the first 5. The reason is simple: there are a lot more email addresses in the system than passwords, about 5 billion in total. Querying via the first 6 bytes of a SHA-1 hash means there are 16 more possibilities than with the password search, therefore 16^6 or just over 16M. Let's take this email address:
test@example.com
Which hashes down to this value with SHA-1:
567159D622FFBB50B11B0EFD307BE358624A26EE
And similar to the password search, it's only the prefix that is sent to HIBP when performing a query:
567159
So, putting the privacy hat on, what's the risk when a service sends this data to HIBP? Mathematically, with the next 34 characters unknown, there are 16^34 different possible hashes that this prefix could belong to. Just to really labour the point, given a 6 byte SHA-1 hash prefix you could take a 1 in 87,112,285,931,760,200,000,000,000,000,000,000,000,000 guess as to what the full hash prefix is. And then due to the infinite number of potential input strings, multiply that number out to... well... infinity. That's the total number of possible email addresses it could represent. By any definition of the term, those first 6 bytes tell you absolutely nothing useful about what email address is being searched for.
But we're left with a more semantic, possibly philosophical question: is "567159" personally identifiable information? In practice, no, for all intents and purposes it's impossible to tell who this belongs to without the remaining 34 characters and even then, you still need to be able to crack that hash which is most likely only going to happen if you have a dictionary of email address to work through in which the given one appears. But it's derived from pseudonymous PII, and this is where the occasional [insert title of person who fills out paperwork but has no technical understanding here] loses their mind.
To explain this in more colloquial terms, it's like saying that the "t" at the beginning of the email address I used above is personally identifying. Really? My own email address begins with a "t", so it must be mine! It's a nonsense argument.
I'll wrap up with a definition and I like NIST's the best, not just because it's clear and concise but because they're a great authoritative source on this sort of thing (it was actually their guidance on prohibiting passwords from previous breach corpuses that led me to create Pwned Passwords in the first place):
Any representation of information that permits the identity of an individual to whom the information applies to be reasonably inferred by either direct or indirect means.
Phone numbers are PII. Physical addresses are PII. IP addresses are PII. The first 6 bytes of a SHA-1 hash of someone's email address is not PII.
Summary
None of the misunderstandings I've explained above have dented the adoption of these services. Pwned Passwords is now doing in excess of 2 billion queries a month and has an ongoing feed of new passwords directly from the FBI. The k-anonymity search for email addresses sees over 100M queries a month and is baked into everything from browsers to password managers to identity theft services. The success of these services isn't due to any technical genius on my part (hat-tip again to Cloudflare), but rather to their simple yet effective implementations that (almost) everyone can easily understand 😊
For many years now, I've lamented about how much of my time is spent attempting to disclose data breaches to impacted companies. It's by far the single most time-consuming activity in processing breaches for Have I Been Pwned (HIBP) and frankly, it's about the most thankless task I can imagine. Finding contact details is hard. Getting responses is hard. Not having an organisation just automatically assume you're trying to shake them down for cash is hard. So hard, in fact, I thought I'd record the process end-to-end and share it publicly to help demonstrate just how painful the process is.
I'd filed the (alleged) Avvo breach away in the "too hard" basket a long time ago and it was only after seeing this tweet last week that a distant bell rang in my head:
@troyhunt Looks like @avvo has had a breach of their user list -- I'm getting those "you've been hacked" scam emails on my Avvo-specific address. No passwords, so I'm guessing they're hashed.
On a hunch that this wasn't going to be an easy process, I started recording and kicked off my usual disclosure process. It failed - completely - but at least now I have a complete blow-by-blow of everything I've done, who I've contacted and who I've even engaged with yet still, to no avail. Here's the whole thing:
The Avvo data breach is now searchable in HIBP. By the time I sent out notifications, they went to 20,183 individuals monitoring their accounts and a further 9,637 people monitoring domains with impacted email addresses. I'll update this post with any further relevant information if it comes up in the future.
This is just one of many initiatives I'm pursuing to help those impacted by data breaches and I look forward to welcoming many more national governments in the future.