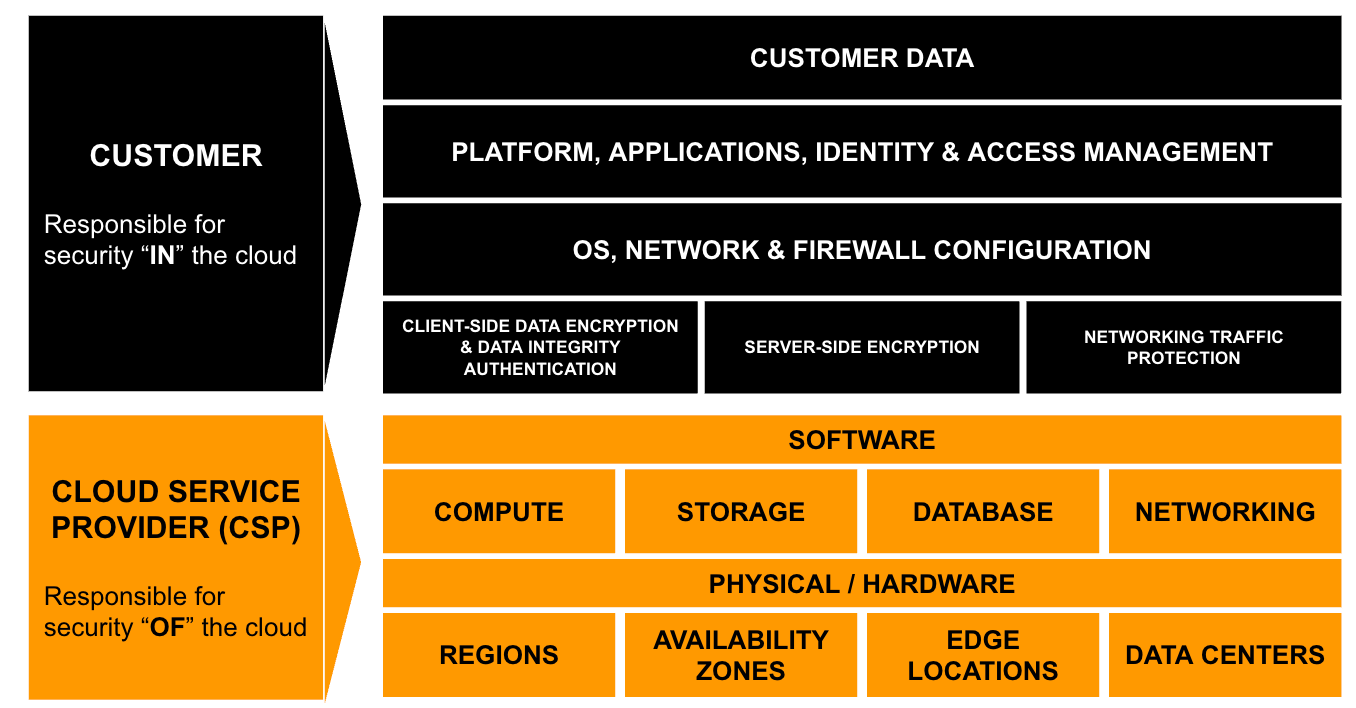
With Google Cloud Next happening this week, there’s been some recent water cooler talk - okay, informal, ad hoc Zoom calls - where discussions about what makes Google Cloud Platform (GCP) unique when it comes to security. A few specific differences have popped up here and there (default data encryption, the way IAM is handled, etc.), but, generally speaking, many of the principles that apply to all other cloud providers apply to GCP environments.
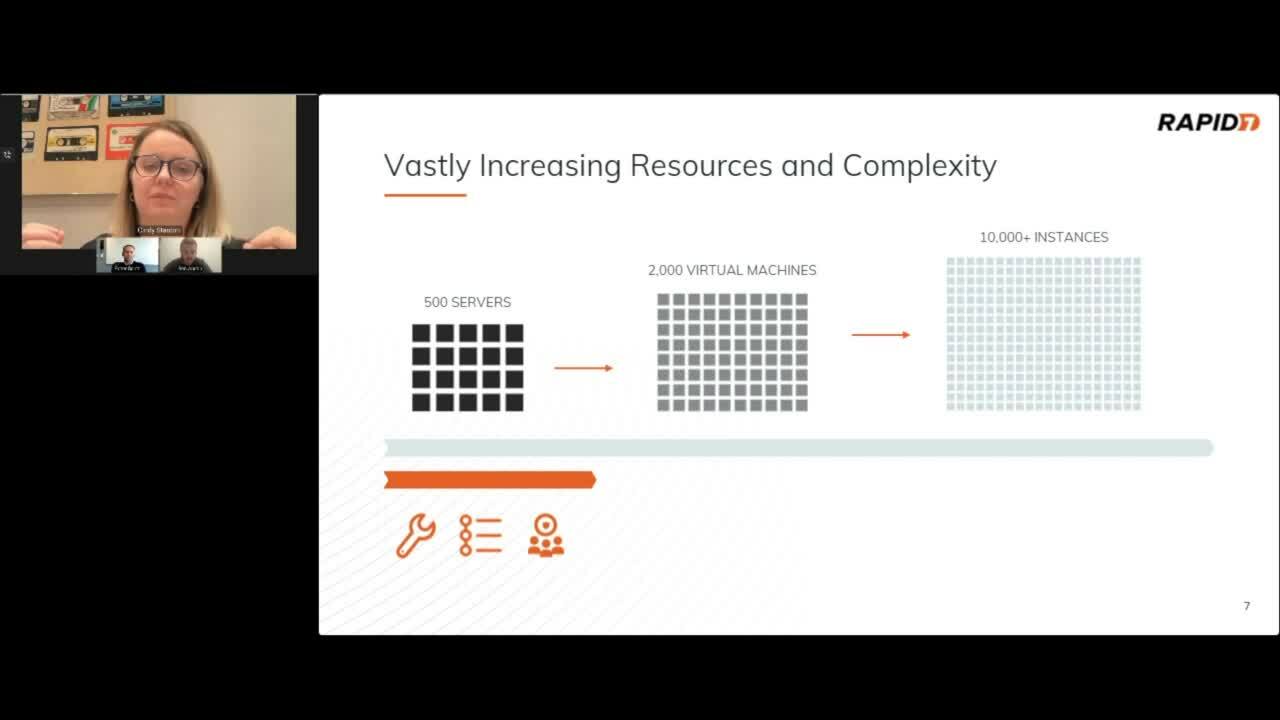
For one, due to the speed and scale of these environments, it’s simultaneously very difficult and extremely critical to maintain an up-to-date inventory of the state of all resources in your environment. This means constantly monitoring your environment for resources being created, deleted, or modified in as close to real time as possible.
And in an effort to avoid ambiguity or hide behind marketing buzz terms, when I’m referring to “real time” here, I’m talking about sub 5-minute intervals based on activity happening in the environment. This is not to be confused with “near real time” approaches some vendors tout, which, in reality, still only pulls in data once or twice a day based on a static schedule.
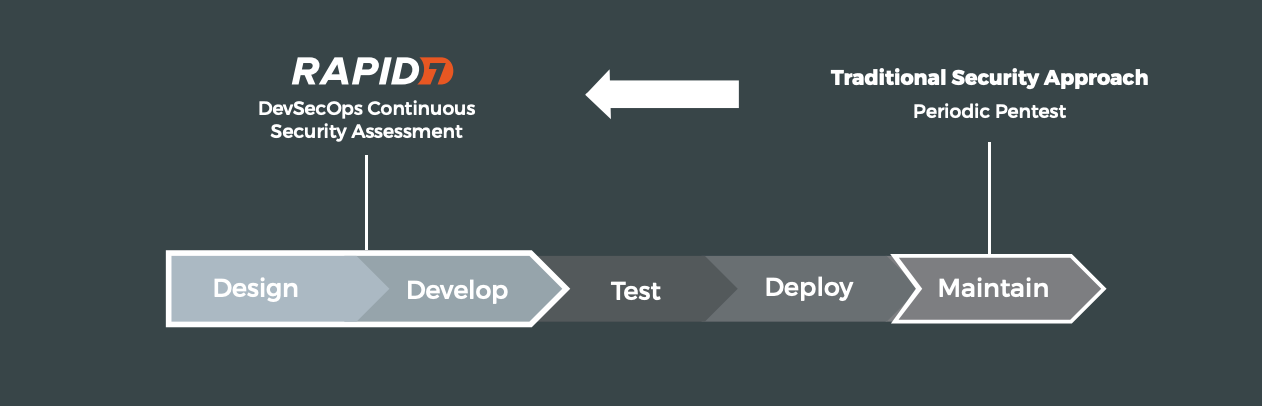
In GCP, like in AWS, Azure, and all other cloud environments, simply getting a snapshot once a day to identify misconfigurations, vulnerabilities, or suspicious behaviors like you might with an on-prem data center just isn’t a scalable strategy. It’s a common cliche, but the ephemeral nature and rate of change in public cloud environments makes that kind of scanning strategy extremely ineffective when it comes to monitoring, analyzing, and eliminating actual risk in a cloud environment.
Let me lay out a couple examples where this kind of real-time monitoring can provide significant, potentially necessary, value to security teams working to make their cloud risk management programs more effective.
Identification of high-risk resources
As an example, say a developer is in a GCP project associated with your company’s revenue-generating application and they spin up a Cloud Storage instance that is, whether mistakenly or maliciously, open to the public internet.
If your security team is reliant on a scan to happen 12 hours later to get visibility into this activity, your organization will constantly be left open to significant risk. Take away the hyperbole here and assume it’s a much smaller risk or compliance violation. Even in that situation, your team is still working from behind and, presumably, almost always facing some level of stress about what issues are out there in the environment that they won’t know about for another 12-18 hours.
Worst of all, with this type of scanning you’re generally just getting a point-in-time snapshot of the environment and usually don’t know who made the change or how long ago it happened. This makes it much more difficult and time consuming for your team to actually assess the risk or get their hands on the right information to make an informed decision about how the situation should be addressed.
When a team is working with real-time data, however, they can be much more diligent and confident that they’re prioritizing the right issues at any given moment, with all the necessary context about who made the change and when it occurred. This not only helps teams stay ahead of issues and reduce the risk of a breach in their environment, but also helps keep individuals and teams feeling positive about the impact that the program is having on the organization.
Building off of the previous example, it’s not only that teams can’t respond to risk they haven’t been notified of, it’s also that any automated response workflows your team may have built out to be more efficient are significantly less effective when they’re triggered by hours-old data. A 12-hour delay in an automation workflow all but eliminates the value of the automation itself, and it can actually cause headaches and confusion that detract from your team’s efficiency, rather than improving it (more on this in the next example).
In contrast, if you’re able to detect risky changes to your environment as they happen, you can automatically respond to that issue as it happens. In the case of this all being a mistake caused by a developer working a little too quickly, you’re able to automatically notify them of their error within a matter of minutes, likely while they’re still working within that project. Giving your development team this kind of feedback in the moment, rather than forcing them to context switch and go back into the project to fix the error a day later, is an excellent way to build stronger relationships and rapport with that team.
In the more rare case that this is indeed a malicious internal or external actor, enabling your automated remediation workflows to kick into gear within seconds and potentially stop the behavior could mean the difference between a minor incident and a breach requiring public disclosure from your organization.
Minimizing false positives and cross-team friction
Speaking of relationships with the development team (sorry, #DevSecOps), I can almost guarantee that working with data from scans or snapshots that occur every 12 or 24 hours in your cloud will cause friction between your two teams. Whether it’s tied to manual identification of risky resources or automated workflows notifying them of a non-compliant asset, working with stale data will inevitably lead to false positives that will both annoy and distract your already overburdened development team.
Take the example highlighted above, but instead, let’s say the developer actually spun up that Cloud Storage instance for a short amount of time in a dev instance with no actual customer data as part of a testing exercise. By the time your team gets visibility into this and either reaches out manually or has some automated notification sent to the developer, that instance could have already been deleted for hours. Now your team is looking at one set of old data and seeing an issue, meanwhile the developer is insisting that the storage container doesn’t even exist anymore. As mentioned above, this is going to cause headaches and frustration for both parties, and cause your team to lose credibility with the dev team.
At this point, you can probably guess where this is going next. With real-time monitoring in your environment this situation can be avoided altogether because your team will be looking at the same up-to-date information, and your team will be able to see that the storage container was shut down or removed from the project rather than spending time chasing down a false positive.
Earlier this month we released event-driven harvesting for GCP in InsightCloudSec. This agentless, real-time monitoring helps your security team achieve every one of the benefits outlined above while also avoiding API rate limiting. In addition, we’ve recently added GCP CIS Benchmarks v1.3.0, added GCP threat findings into our console, and added support for Google Directory to give visibility into IAM factors such as user last login, MFA status, group association and more.
If you want to learn more about how Rapid7 can help you secure Google Cloud Platform, or any other public cloud environment, sign up for our live bi-weekly demo of InsightCloudSec.