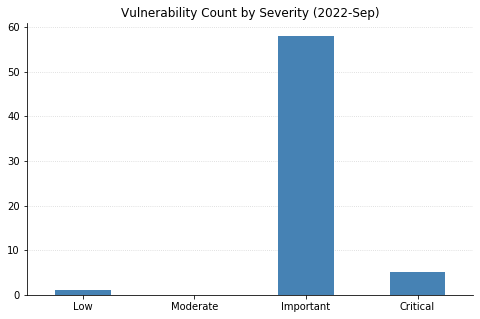
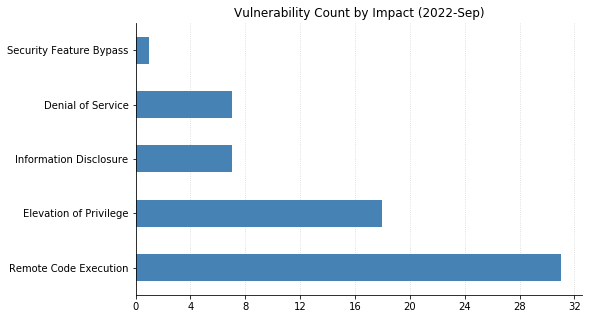
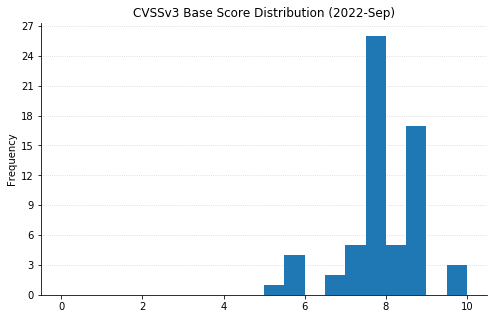
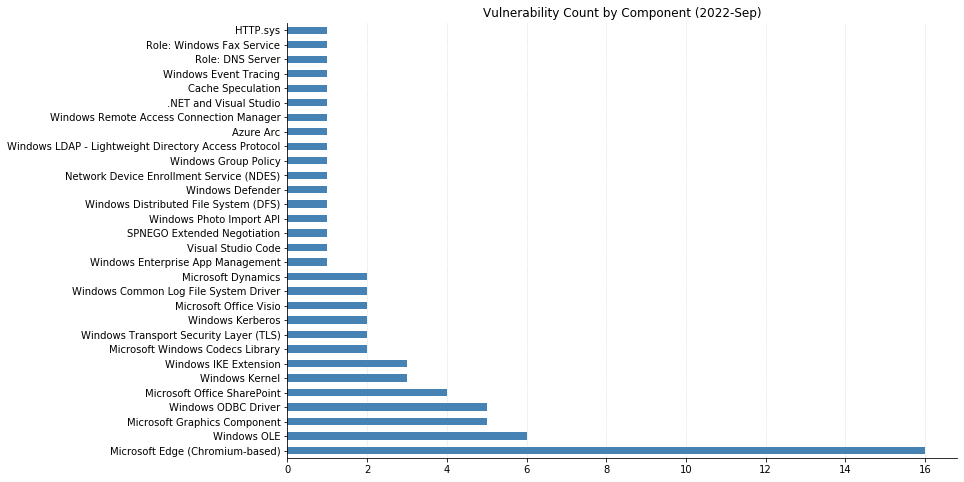
This month’s Patch Tuesday is on the lighter side, with 79 CVEs being fixed by Microsoft (including 16 CVEs affecting Chromium, used by their Edge browser, that were already available). One zero-day was announced: CVE-2022-37969 is an elevation of privilege vulnerability affecting the Log File System Driver in all supported versions of Windows, allowing attackers to gain SYSTEM-level access on an asset they’ve already got an initial foothold in. Interestingly, Microsoft credits four separate researchers/organizations for independently reporting this, which may be indicative of relatively widespread exploitation. Also previously disclosed (in March), though less useful to attackers, Microsoft has released a fix for CVE-2022-23960 (aka Spectre-BHB) for Windows 11 on ARM64.
Some of the more noteworthy vulnerabilities this month affect Windows systems with IPSec enabled. CVE-2022-34718 allows remote code execution (RCE) on any Windows system reachable via IPv6; CVE-2022-34721 and CVE-2022-34722 are RCE vulnerabilities in the Windows Internet Key Exchange (IKE) Protocol Extensions. All three CVEs are ranked Critical and carry a CVSSv3 base score of 9.8. Rounding out the Critical RCEs this month are CVE-2022-35805 and CVE-2022-34700, both of which affect Microsoft Dynamics (on-premise) and have a CVSSv3 base score of 8.8. Any such systems should be updated immediately.
SharePoint administrators should also be aware of four separate RCEs being addressed this month. They’re ranked Important, meaning Microsoft recommends applying the updates at the earliest opportunity. Finally, a large swath of CVEs affecting OLE DB Provider for SQL Server and the Microsoft ODBC Driver were also fixed. These require some social engineering to exploit, by convincing a user to either connect to a malicious SQL Server or open a maliciously crafted .mdb (Access) file.
Over the years, our recommendations and best practices for the InsightVM console have changed with the improvements and updates we’ve made to the system. Here are some of the most common improvements to help you get the most out of your InsightVM console in 2022.
Ensure everything is up to date
The first step to ensuring the health of your console is ensuring it is up to date. For InsightVM product updates, the typical release schedule is weekly on Wednesday, with the occasional out-of-band update. To stay on the latest version, you can set the update frequency to every 24 hours and set it to off-hours to perform that check. This will ensure the latest update is being applied and the console isn’t rebooting in the middle of the workday.
The InsightVM content updates include new vulnerabilities updated every 2 hours. As these don’t require a system reboot, it is recommended to leave them set to automatically update.
Make sure your scan engines are properly updated as well. As long as the scan engine has enough storage space and can reach the InsightVM console, it should be able to receive the latest update.
Unless you are on a Rapid7-hosted console, you are also in charge of updating the underlying operating system. That means not just applying the latest security patch, but also making sure the OS version itself is not end-of-life.
Lastly, you want to make sure you’re running the latest version of the InsightVM postgreSQL database — version 11.7. If you are still running version 9.4, this can cause some potential issues with the database, as well as general slowdown in the console and running reports.
With the latest InsightVM product updates, we also have a database auto-tune feature which automatically tunes based on the amount of RAM on the console server. This feature does not work if you are still on version 9.4. If you are on version 11.7, to activate it, go to Administration -> Run and then run the command tune assistant to make sure everything is tuned correctly. This will have a greater impact if you have 64GB RAM or above.
Check out this doc on tuning the PostgreSQL database for more detail. If you don’t feel comfortable tuning your own database, you can always contact Rapid7 support for assistance.
Reduce the number of sites
One of the largest improvements to the console is the increase in scan efficiency. Before October 2020, the discovery portion of the scan would only hit 1,024 assets simultaneously. Now, we are running discovery against 65,535 IPs at once. This leads to much faster discovery of larger IP ranges. Because of this, we recommend having fewer sites with larger IP scopes, such as /16 or /8 CIDR ranges.
The best way to organize these new, larger sites is based around function or geographical region – for example, having a separate site for all stores and one for all corporate ranges. Another example would be to break up the sites based on continents, or as large of a geographical region as possible.
Having fewer sites with a larger scope will help reduce the micromanagement of schedules and allow for ease of scalability when scanning more devices. For granular reporting, use asset groups, which are much more flexible than IP ranges and are designed to let you set the scope for reports and access management.
Prevent scan overlap
Besides having too many sites, the next-largest problem most consoles face is when scans overlap on the same scan engine. Having fewer sites helps with having fewer scheduled scans, but you should still be aware what scan engine is being used for those sites. Running a scan uses up RAM on the scan engine, and having too many scans running at once can cause scan slowdown or potentially engine crashes due to lack of memory.
The best-case scenario is to have one scan engine per site. That way, your sites can be scanned at the same time without any chance of them overloading a single engine. If you have some sites or locations that are much larger than others, you can always deploy more engines to that location and pool them together for even greater scan efficiency.
And remember, if you’re scanning more than 2,000 devices or have a segmented network, you should not be using the local scan engine, as that takes away resources from the console and PostgreSQL database.
Optimize scan templates
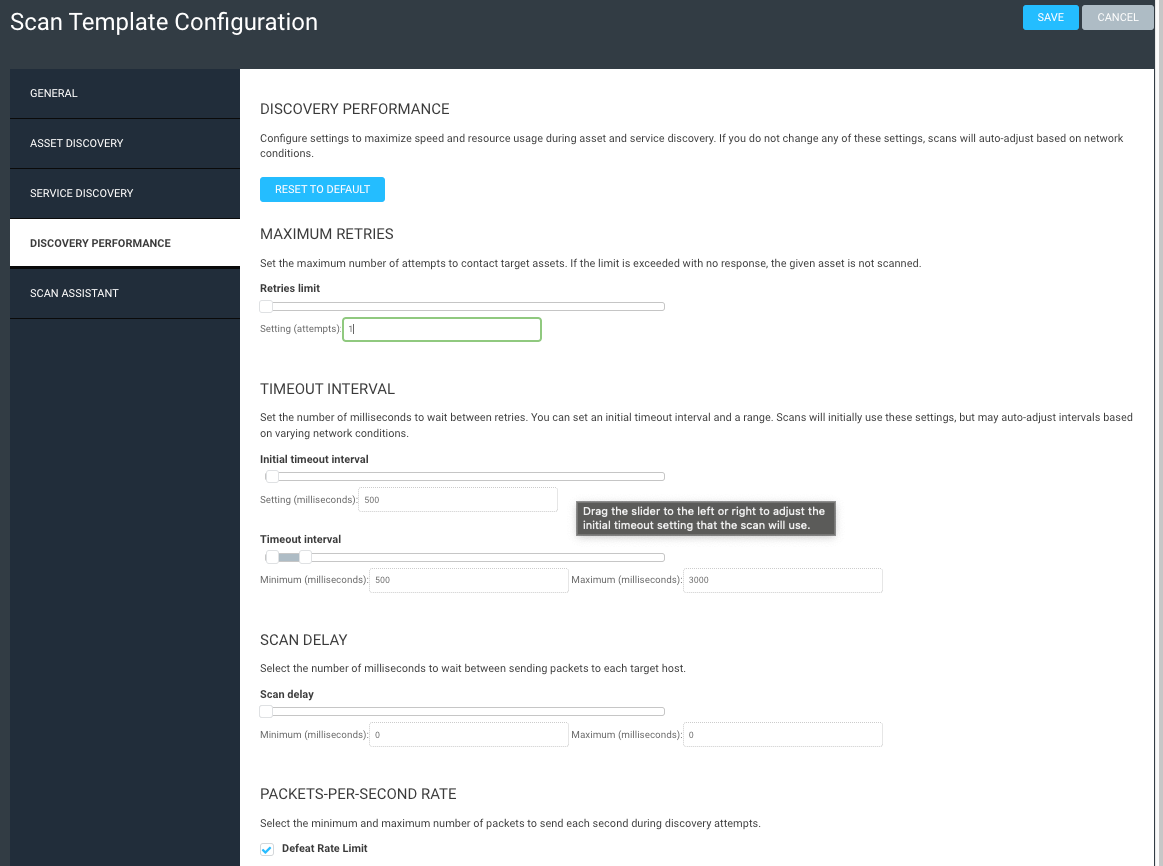
After making sure your scans aren’t overlapping on the same engine, the next step is to speed up the scans by optimizing your scan template. My colleague Landon Dalke wrote a great blog post documenting the best practices for your scan templates. Here are a few highlights from his post:
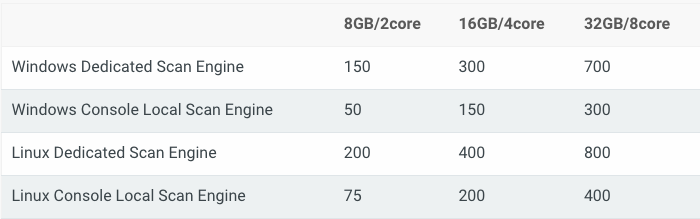
Assets scanned simultaneously per scan engine: Please use the following table for reference depending on how much CPU and RAM your scan engines have. Make sure your engines have a 1:4 ratio of CPU to memory for the best performance. Also, if your scan engines are virtual, make sure to reserve the allocated memory to avoid insufficient memory issues.
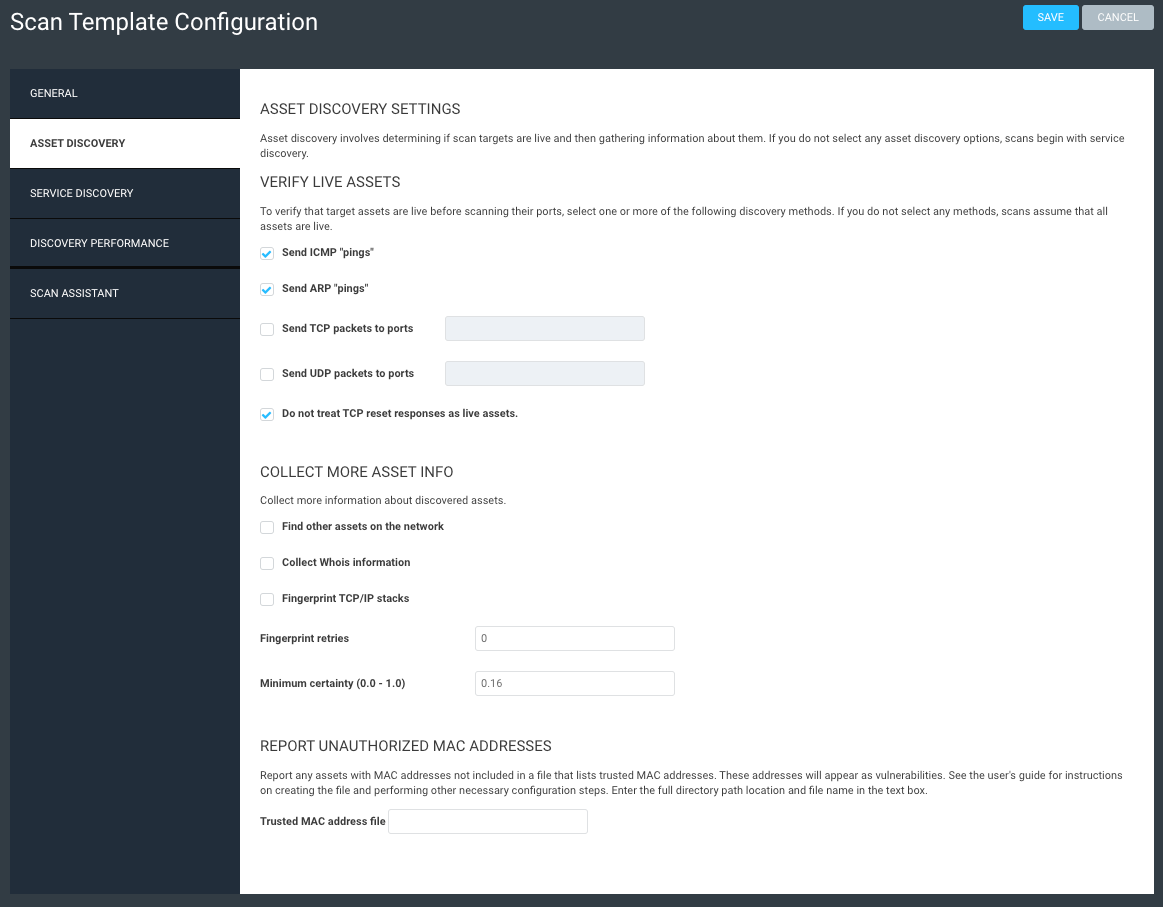
Send UDP packets to ports: We recommend disabling. It’s unlikely a device will be reachable that doesn’t respond to ICMP, ARP, or TCP but is somehow found only using UDP.
Do not treat TCP reset responses as live assets: We recommend enabling. This will help prevent “ghost assets” with no hostname or operating system from appearing, as some routers or IDS/IPS send TCP reset responses.
Nmap Services Detection: We recommend disabling this, as it can cause scans to take five to 10 times longer to run. Having a credential or agent on a device gives the same information.
Skip checks performed by the Insight Agent: We recommend enabling. If the agent is detected on a device, it will skip the vulnerability checks the agent is already performing, reducing scan time.
If all of your scan engines have the same resources, you can get away with needing one optimized scan template, reducing potential confusion and further simplifying your scan configurations.
After following these steps, your console should be in a much better place to reduce micromanagement and improve overall efficiency. If you need continued help and support, don’t hesitate to reach out to Rapid7 Support or your Customer Success Manager.
Trying to deal with a large network can be difficult. All too often, engineers and admins don't know the full scope of their environment and have trouble defining the actual subnets and the systems that exist on those subnets. They know of a couple /24 subnets here or there, but it's very possible they're missing a few. Once you get over a couple thousand assets, it can get fairly unruly pretty quick. Different teams own different servers and different network ranges. With regards to InsightVM, how do you know what sites create if you don't even know what you own?
Luckily, in InsightVM, we can use a little bit of SQL, an overarching site with a ping sweep, and a nifty little tag to help get a handle on things – all outside any third-party software or other management tools you may acquire to help you wrangle in your IP space. This method in InsightVM lets you find all live assets and identify all network spaces being used in your environment. Then, we can correlate this list against our known subnets and begin building out defined sites for scanning. As we create our known sites, we can start whittling down the number of unknown or undefined subnets.
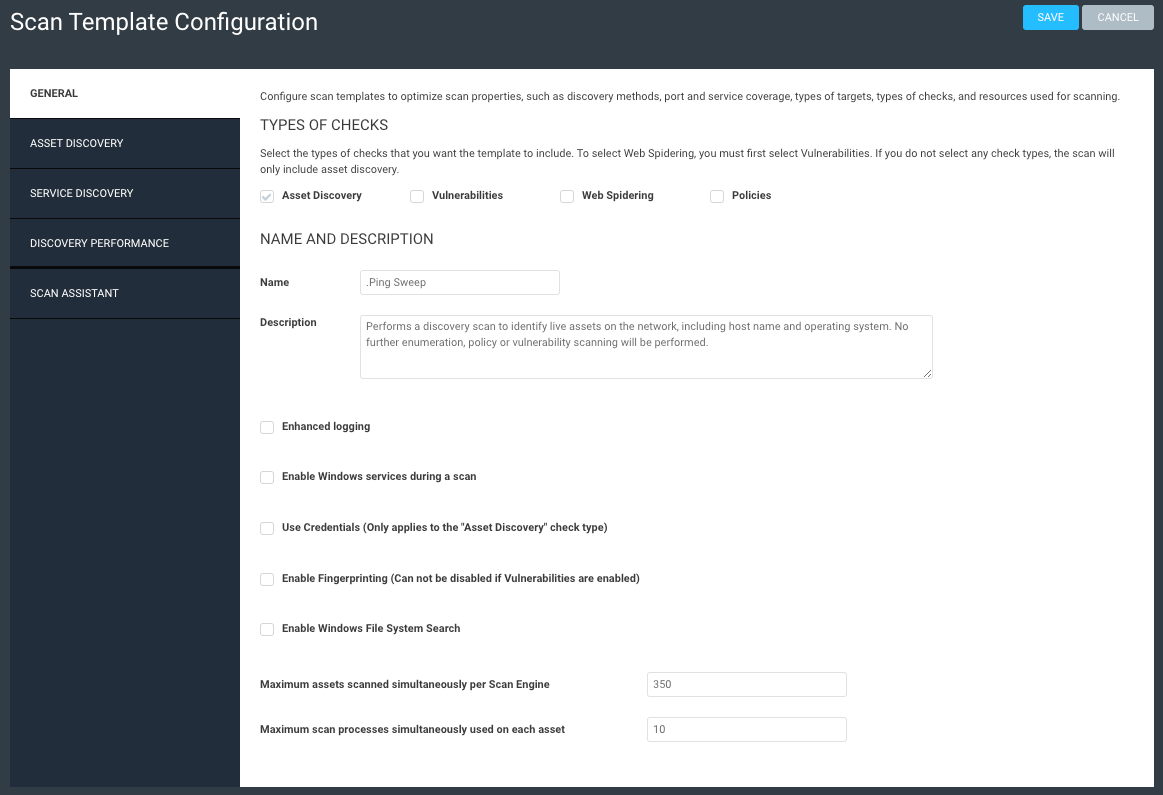
1. Ping Sweep template
The first step is to create a new scan template dedicated solely to a ping sweep. This template isn't scanning for any other services or ports, fingerprinting, or performing any other action – it is simply sending pings to see what is alive. If we get a response back, we assume there is a live asset there, and this will help build out our known networks.
Create your template using these screenshots as guidance. Note that pretty much everything is off except ICMP and ARP pings, and we're not treating TCP resets as live assets (we don't want firewalls throwing us off). This scan should take just a few minutes to complete, as it's not doing all the other functions that a typical scan can do.
2. Overarching site
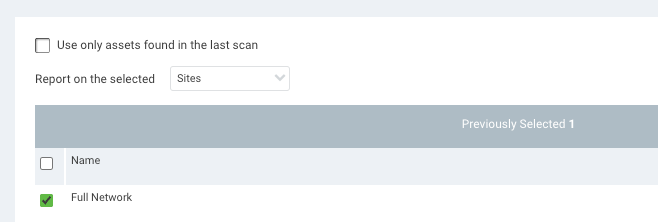
The second step in this process is to create an overarching site. Give it a simple name like "Full Network" or whatever floats your boat. What's important is that, within this site, you define as large of a network range as you know of. Think /16 here, or even a couple /16 networks. I don't know your network, so use your judgment as to what you think exists. The idea is to be as broad as possible.
Now, within this site, set the default scan template as your ".Ping Sweep" template, as in my example above. Set your default scan engine or pool, and then save and scan.
What you should get back now is a full list of every live IP that exists within the defined network. If your defined network includes all the possible IP space, and we are assuming that all assets are online and able to respond, then you should have a pretty robust list of found assets.
3. Known Networks report
The next step is to go to the Reports tab and create a SQL Query Export. Throw the following SQL query in the definition, and scope the query from the GUI to your "Full Network" site.
WITH a AS (
SELECT
asset_id,
CONCAT(split_part(ip_address,'.',1),'.',split_part(ip_address,'.',2),'.',split_part(ip_address,'.',3),'.0/24') AS Network
FROM dim_asset
)
SELECT DISTINCT Network
FROM a
ORDER BY Network ASC
Save and run this report, and you will get a CSV output of all the /24 networks that have at least one live IP in them. You can use this CSV to compare to your known list of networks and start defining the actual sites within your environment. For example, if this report lists out 10.0.0.0/24 and you know that network as your main corporate server’s VLAN, then you can include that network into a separate site for vulnerability scanning.
4. Dynamic tagging
Now that we've started defining our known networks into sites, we need to create a dynamic tag that gets applied to all assets within any site. Now, in my example, I exclude the Rapid7 Insight Agents site, because depending on your environment and whether people are working from home, the Insight Agent may report the IP of their computer when logged onto their home network. We obviously can't scan home networks, so we want to exclude this site to deter any of that bad data.
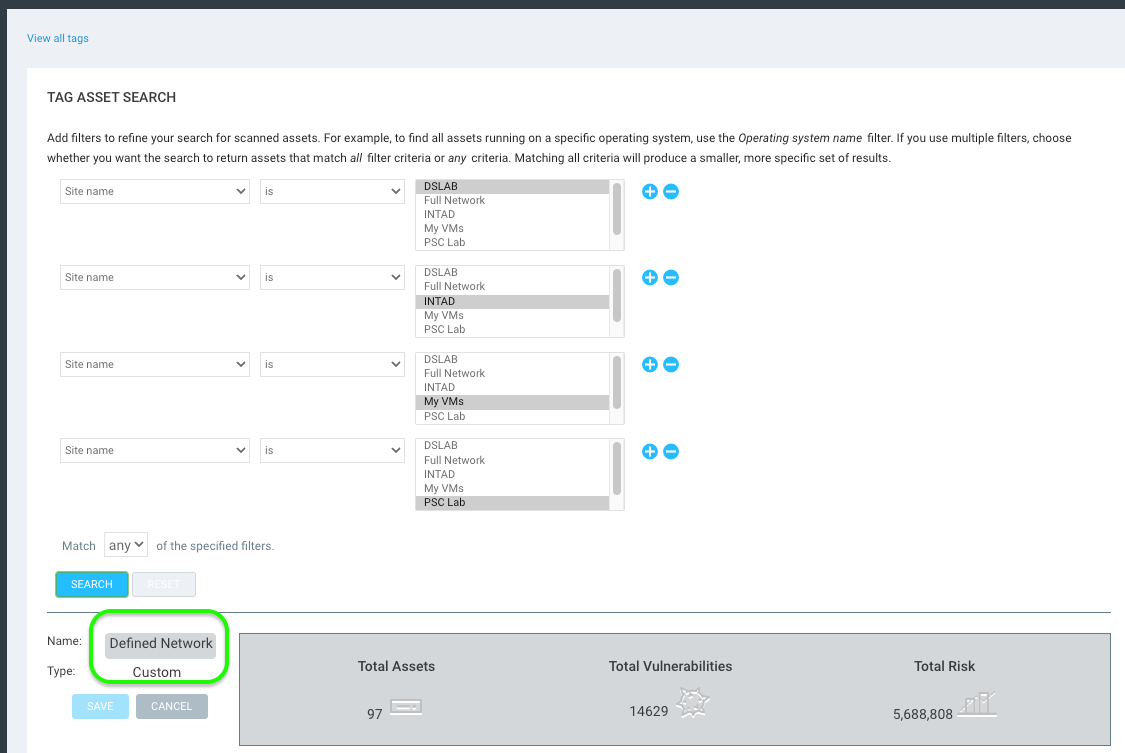
Create a dynamic tag with several lines to include each site. Note that if your site structure is large enough that you have hundreds of sites, you may want to use the API for this part, but we won't go into that here – that's a whole other conversation.
In my example below, I only have four sites – keep in mind I did not select the Rapid7 Insight Agents or my Full Network site. Make sure the operator is set to match ANY of the specified filters. Apply a tag called "Defined Network" to this criteria to tag all assets within a defined site.
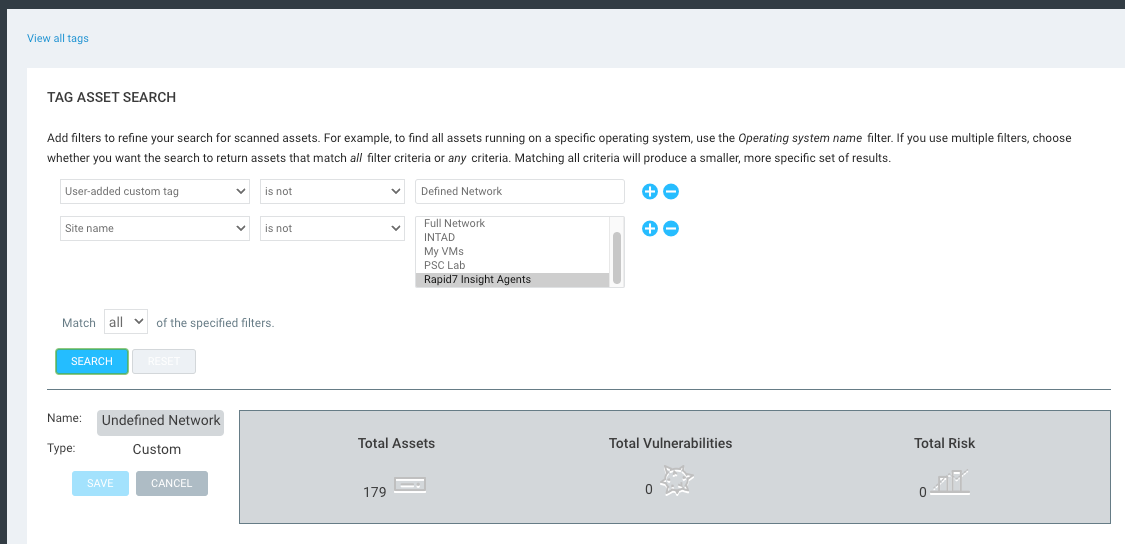
You could also optionally create a secondary tag for "Undefined Networks," but it's not exactly necessary for this process. The below query would get you the Undefined Network assets. Basically, the query is just looking for any assets that don't have the Defined Network tag and are not in the Rapid7 Insight Agents sites.
5. Undefined Networks report
Now, we can set up our secondary SQL report to show us all networks that are not defined within the scope of a site. Once again, go to the Reports tab, create a SQL Query Export report, and throw this query into the definition.
WITH a AS (
SELECT
asset_id,
CONCAT(split_part(ip_address,'.',1),'.',split_part(ip_address,'.',2),'.',split_part(ip_address,'.',3),'.0/24') AS Network
FROM dim_asset
)
SELECT DISTINCT Network
FROM a
WHERE a.asset_id NOT IN (
SELECT DISTINCT asset_id
FROM dim_asset
LEFT JOIN dim_tag_asset USING (asset_id)
LEFT JOIN dim_tag USING (tag_id)
WHERE tag_name = 'Defined Network'
)
ORDER BY Network ASC
Save and run this report, and you will get a new CSV that lists out all /24 networks where there was at least one live asset found but the assets are within a /24 that has not been defined within the scope of a created site. You can use this CSV to work your way through those networks to determine what they are and who owns them and then ensure they are included in future or current sites.
Large environments with unknown network components can be difficult to manage and monitor for vulnerabilities. These five steps in InsightVM help make the process easier and more intuitive, so you can maintain better oversight and a stronger security posture within your environment.
Most of us already know the basic principle of authentication, which, in its simplest form, helps us to identify and verify a user, process, or account. In an Active Directory environment, this is commonly done through the use of an NTLM hash. When a user wants to access a network resource, such as a file […]… Read More
Cybersecurity is becoming more of a common term in today’s industry. It is being passed around executive meetings along with financial information and projected marketing strategies. Within the cybersecurity lexicon, there are some attack methods that are repeated enough to become part of a “common tongue”. These terms are infrastructure agnostic; it does not really […]… Read More
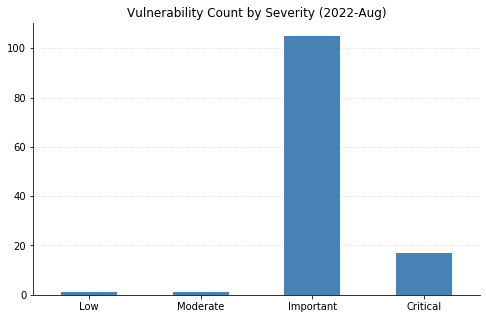
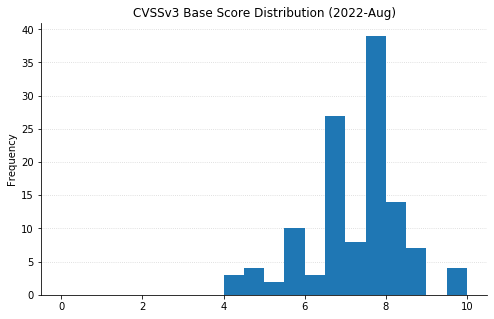
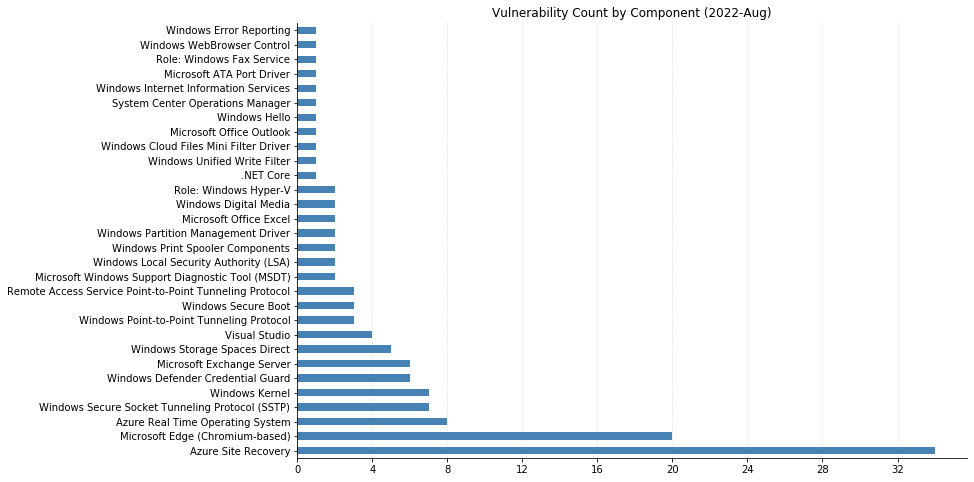
It's the week of Hacker Summer Camp in Las Vegas, and Microsoft has published fixes for 141 separate vulnerabilities in their swath of August updates. This is a new monthly record by raw CVE count, but from a patching perspective, the numbers are slightly less dire. 20 CVEs affect their Chromium-based Edge browser, and 34 affect Azure Site Recovery (up from 32 CVEs affecting that product last month). As usual, OS-level updates will address a lot of these, but note that some extra configuration is required to fully protect Exchange Server this month.
There is one 0-day being patched this month. CVE-2022-34713 is a remote code execution (RCE) vulnerability affecting the Microsoft Windows Support Diagnostic Tool (MSDT) – it carries a CVSSv3 base score of 7.8, as it requires convincing a potential victim to open a malicious file. The advisory indicates that this CVE is a variant of the “Dogwalk” vulnerability, which made news alongside Follina (CVE-2022-30190) back in May.
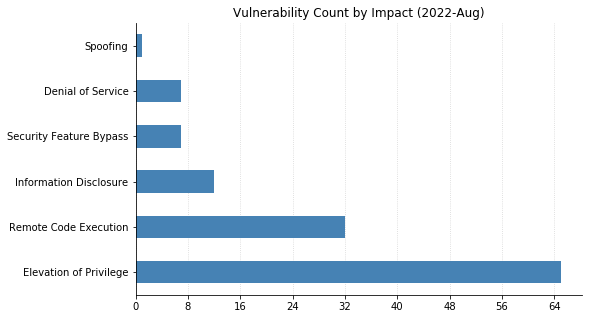
Publicly disclosed, but not (yet) exploited is CVE-2022-30134, an Information Disclosure vulnerability affecting Exchange Server. In this case, simply patching is not sufficient to protect against attackers being able to read targeted email messages. Administrators should enable Extended Protection in order to fully remediate this vulnerability, as well as thefiveothervulnerabilitiesaffecting Exchange this month. Details about how to accomplish this are available via the Exchange Blog.
Microsoft also patched several flaws affecting Remote Access Server (RAS). The most severe of these (CVE-2022-30133 and CVE-2022-35744) are related to Windows Point-to-Point Tunneling Protocol and could allow RCE simply by sending a malicious connection request to a server. Seven CVEs affecting the Windows Secure Socket Tunneling Protocol (SSTP) on RAS were also fixed this month: six RCEs and one Denial of Service. If you have RAS in your environment but are unable to patch immediately, consider blocking traffic on port 1723 from your network.
Vulnerabilities affecting Windows Network File System (NFS) have been trending in recent months, and today sees Microsoft patching CVE-2022-34715 (RCE, CVSS 9.8) affecting NFSv4.1 on Windows Server 2022.
This is the worst of it. One last vulnerability to highlight: CVE-2022-35797 is a Security Feature Bypass in Windows Hello – Microsoft’s biometric authentication mechanism for Windows 10. Successful exploitation requires physical access to a system, but would allow an attacker to bypass a facial recognition check.
The Vulnerability Management team kicked off Q2 by remediating the instances of Spring4Shell (CVE-2022-22965) and Spring Cloud (CVE-2022-22963) vulnerabilities that impacted cybersecurity teams worldwide. We also made several investments to both InsightVM and Nexpose throughout the second quarter that will help improve and better automate vulnerability management for your organization. Let’s dive in!
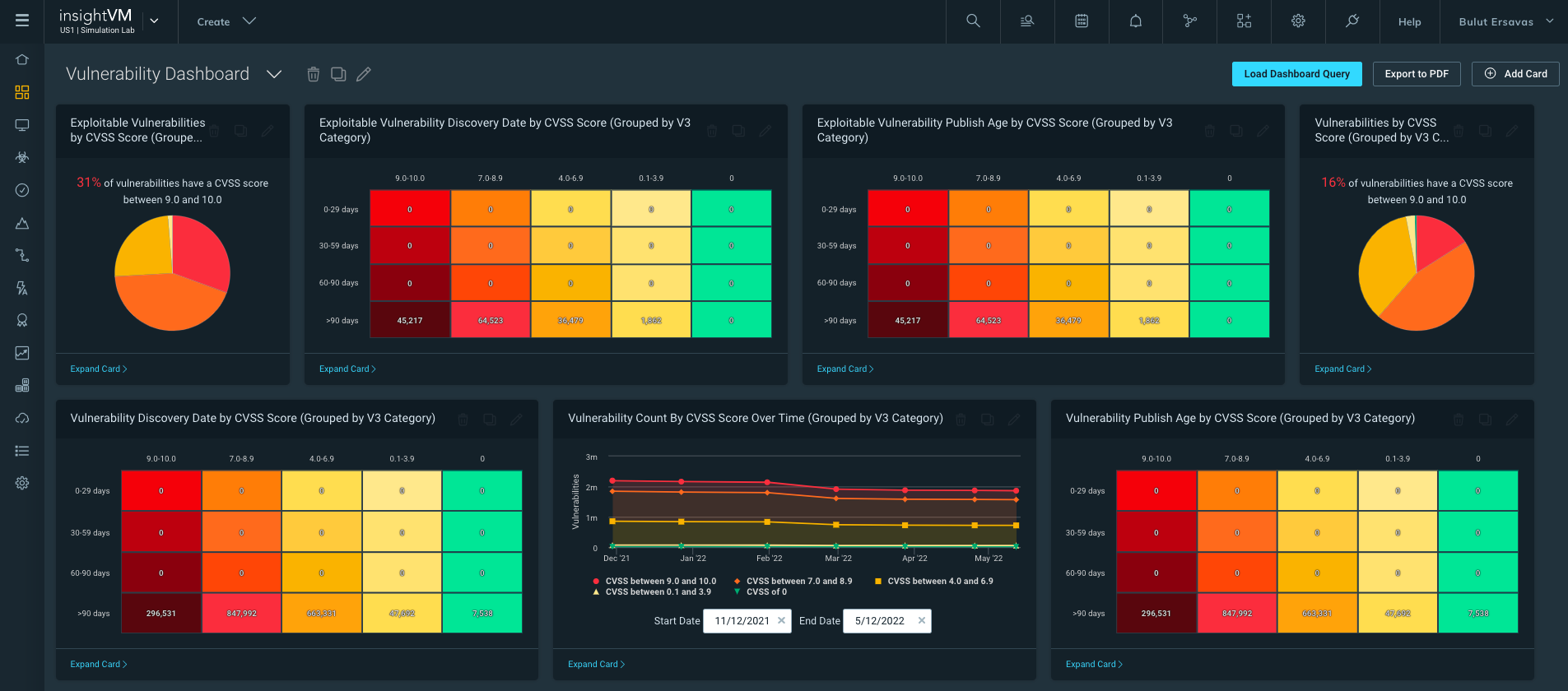
New dashboard cards based on CVSS v3 Severity (InsightVM)
CVSS (Common Vulnerability Scoring System) is an open standard for scoring the severity of vulnerabilities; it’s a key metric that organizations use to prioritize risk in their environments. To empower organizations with tools to do this more effectively, we recently duplicated seven CVSS dashboard cards in InsightVM to include a version that sorts the vulnerabilities based on CVSS v3 scores.The v3 CVSS system made some changes to both quantitative and qualitative scores. For example, Log4Shell had a score of 9.3 (high) in v2 and a 10 (critical) in v3.
Having both V2 and V3 version dashboards available allows you to prioritize and sort vulnerabilities according to your chosen methodology. Security is not one-size-fits all, and the CVSS v2 scoring might provide more accurate vulnerability prioritization for some customers. InsightVM allows customers to choose whether v2 or v3 scoring is a better option for their organizations’ unique needs.
The seven cards now available for CVSS v3 are:
Exploitable Vulnerabilities by CVSS Score
Exploitable Vulnerability Discovery Date by CVSS Score
Exploitable Vulnerability Publish Age by CVSS Score
Vulnerability Count By CVSS Score Over Time
Vulnerabilities by CVSS Score
Vulnerability Discovery Date by CVSS Score
Vulnerability Publish Age by CVSS Score
Asset correlation for Citrix VDI instances (InsightVM)
You asked, and we listened. By popular demand, InsightVM can now identify agent-based assets that are Citrix VDI instances and correlate them to the user, enabling more accurate asset/instance tagging.
Previously, when a user started a non-persistent VDI, it created a new AgentID, which then created a new asset in the console and consumed a user license. The InsightVM team is excited to bring this solution to our customers for this widely persistent problem.
Through the Improved Agent experience for Citrix VDI instances, when User X logs into their daily virtual desktop, it will automatically correlate to User’s experience, maintain the asset history, and consume only one license. The result is a smoother, more streamlined experience for organizations that deploy and scan Citrix VDI.
Scan Assistant made even easier to manage (Nexpose and InsightVM)
In December 2021, we launched Scan Assistant, a lightweight service deployed on an asset that uses digital certificates for handshake instead of account-based credentials; This alleviates the credential management headaches VM teams often encounter. The Scan Assistant is also designed to drive improved vulnerability scanning performance in both InsightVM and Nexpose, with faster completion times for both vulnerability and policy scans.
We recently released Scan Assistant 1.1.0, which automates Scan Assistant software updates and digital certificate rotation for customers seeking to deploy and maintain a fleet of Scan Assistants. This new automation improves security – digital certificates are more difficult to compromise than credentials – and simplifies administration for organizations by enabling them to centrally manage features from the Security Console.
Currently, these enhancements are only available on Windows OS. To opt into automated Scan Assistant software updates and/or digital certificate rotation, please visit the Scan Assistant tab in the Scan Template.
Rapid7 is committed to providing ongoing monitoring and coverage for a number of software products and services. The Vulnerability Management team continuously evaluates items to add to our recurring coverage list, basing selections on threat and security advisories, overall industry adoption, and customer requests.
We recently added several notable software products/services to our list of recurring coverage, including:
AlmaLinux and Rocky Linux. These free Linux operating systems have grown in popularity among Rapid7 Vulnerability Management customers seeking a replacement for CentOS. Adding recurring coverage for both AlmaLinux and Rocky Linux enables customers to more safely make the switch and maintain visibility into their vulnerability risk profile.
Oracle E-Business Suite. ERP systems contain organizations’ “crown jewels” – like customer data, financial information, strategic plans, and other proprietary data – so it’s no surprise that attacks on these systems have increased in recent years. Our new recurring coverage for the Oracle E-Business Suite is one of the most complex pieces of recurring coverage added to our list, providing coverage for several different components to ensure ongoing protection for Oracle E-Business Suite customers’ most valuable information.
VMware Horizon. The VMware Horizon platform enables the delivery of virtual desktops and applications across a number of operating systems. VDI is a prime target for bad actors trying to access customer environments, due in part to its multiple entry points; once a hacker gains entry, it’s fairly easy for them to jump into a company’s servers and critical files. By providing recurring coverage for both the VMware server and client, Rapid7 gives customers broad coverage of this particular risk profile.
Remediation Projects (InsightVM)
Remediation Projects help security teams collaborate and track progress of remediation work (often assigned to their IT ops counterparts). We’re excited to announce a few updates to this feature:
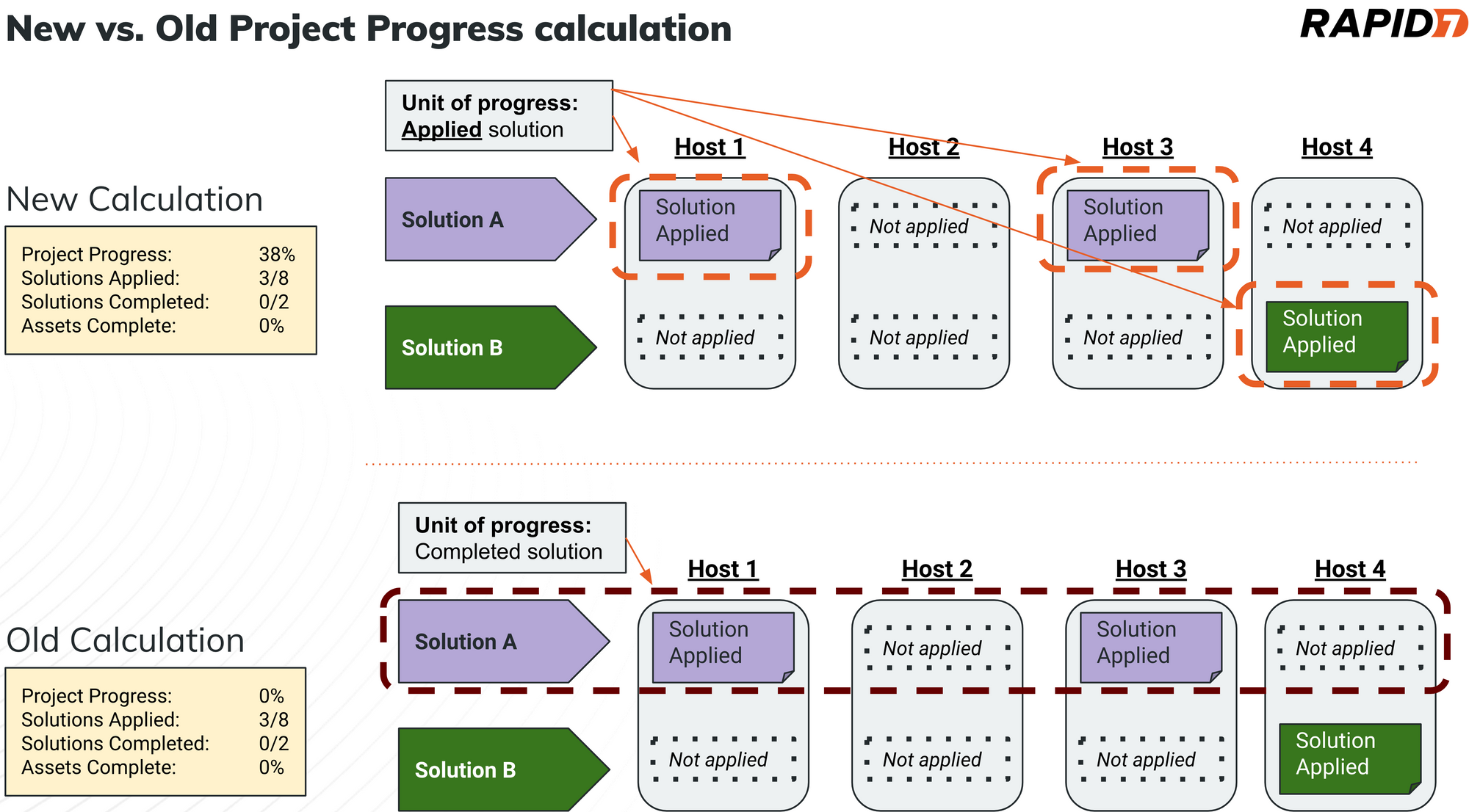
Better way to track progress for projects
The InsightVM team has updated the metric that calculates progress for Remediation Projects. The new metric will advance for each individual asset remediated within a “solution” group. Yes, this means customers no longer have to wait for all the affected assets to be remediated to see progress. Security teams can thus have meaningful discussions about progress with assigned remediators or upper management. Learn more.
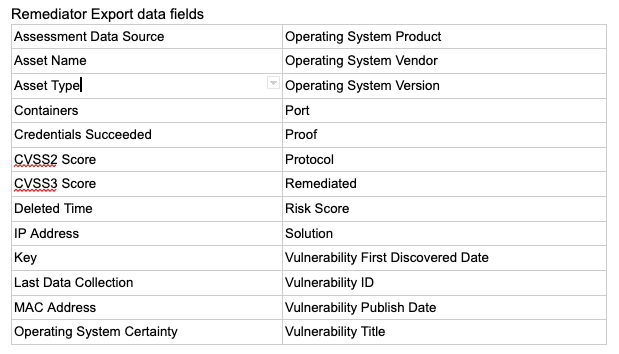
Remediator Export
We added a new and much requested solution-based CSV export option to Remediation Projects. Remediator Export contains detailed information about the assets, vulnerabilities, proof data, and more for a given solution. This update makes it easy and quick for the Security teams to share relevant data with the Remediation team. It also gives remediators all of the information they need.On the other hand, the remediators will have all the information they need. We call this a win-win for both teams! Learn more.
Project search bar for Projects
Our team has added a search bar on the Remediation Projects page. This highly requested feature empowers customers to easily locate a project instead of having to scroll down the entire list.
We're here with the final installment in our Pain Points: Ransomware Data Disclosure Trendsreport blog series, and today we're looking at a unique aspect of the report that clarifies not just what ransomware actors choose to disclose, but who discloses what, and how the ransomware landscape has changed over the last two years.
Firstly, we should tell you that our research centered around the concept of double extortion. Unlike traditional ransomware attacks, where bad actors take over a victim's network and hold the data hostage for ransom, double extortion takes it a step further and extorts the victim for more money with the threat (and, in some cases, execution) of the release of sensitive data. So not only does a victim experience a ransomware attack, they also experience a data breach, and the additional risk of that data becoming publicly available if they do not pay.
According to our research, there have been a handful of major players in the double extortion field starting in April 2020, when our data begins, and February 2022. Double extortion itself was in many ways pioneered by the Maze ransomware group, so it should not surprise anyone that we will focus on them first.
The rise and fall of Maze and the splintering of ransomware double extortion
Maze's influence on the current state of ransomware should not be understated. Prior to the group's pioneering of double extortion, many ransomware actors intended to sell the data they encrypted to other criminal entities. Maze, however, popularized another revenue stream for these bad actors, leaning on the victims themselves for more money. Using coercive pressure, Maze did an end run around one of the most important safeguards organizations can take against ransomware: having safely secured and regularly updated backups of their important data.
Throughout most of 2020 Maze was the leader of the double extortion tactic among ransomware groups, accounting for 30% of the 94 reported cases of double extortion between April and December of 2020. This is even more remarkable given the fact that Maze itself was shut down in November of 2020.
Other top ransomware groups also accounted for large percentages of data disclosures. For instance, in that same year, REvil/Sodinokibi accounted for 19%, Conti accounted for 14%, and NetWalker 12%. To give some indication of just how big Maze's influence was and offer explanation for what happened after they were shut down, Maze and REvil/Sodinokibi accounted for nearly half of all double extortion attacks that year.
However, once Maze was out of the way, double extortion still continued, just with far more players taking smaller pieces of the pie. Conti and REvil/Sodinokibi were still major players in 2021, but their combined market share barely ticked up, making up just 35% of the market even without Maze dominating the space. Conti accounted for 19%, and REvil/Sodinokibi dropped to 16%.
But other smaller players saw increases in 2021. CL0P's market share rose to 9%, making it the third most active group. Darkside and RansomEXX both went from 2% in 2020 to 6% in 2021. There were 16 other groups who came onto the scene, but none of them took more than 5% market share. Essentially, with Maze out of the way, the ransomware market splintered with even the big groups from the year before being unable to step in and fill Maze's shoes.
What they steal depends on who they are
Even ransomware groups have their own preferred types of data to steal, release, and hold hostage. REvil/Sodinokibi focused heavily on releasing customer and patient data (present in 55% of their disclosures), finance and accounting data (present in 55% of their disclosures), employee PII and HR data (present in 52% of their disclosures), and sales and marketing data (present in 48% of their disclosures).
CL0P on the other hand was far more focused on Employee PII & HR data with that type of information present in 70% of their disclosures, more than double any other type of data. Conti overwhelmingly focused on Finance and Accounting data (present in 81% of their disclosures) whereas Customer & Patient Data was just 42% and Employee PII & HR data at just 27%.
Ultimately, these organizations have their own unique interests in the type of data they choose to steal and release during the double extortion layer of their ransomware attacks. They can act as calling cards for the different groups that help illuminate the inner workings of the ransomware ecosystem.
Thank you for joining us on this unprecedented dive into the world of double extortion as told through the data disclosures themselves. To dive even deeper into the data, download the full report.
An enterprise vulnerability management program can reach its full potential when it is built on well-established foundational goals. These goals should address the information needs of all stakeholders, tie back to the business goals of the enterprise, and reduce the organization’s risk. Existing vulnerability management technologies can detect risk, but they require a foundation of […]… Read More
Think of an endeavor in your life where your success is entirely dependent on the success of others. What’s the first example that comes to mind? It’s common in team sports – a quarterback and a wide receiver, a fullback and their goalie, an equestrian and their horse.
What if you narrow the scope to endeavors or activities at work? A little more difficult, right? A large project is an easy candidate, but those are generally distributed across many people over a long time period, which allows for mitigation and planning.
For those that make a living in cybersecurity, the example that immediately comes to mind is vulnerability management (VM). VM, which really falls under the heading of risk management, requires deft handling of executive communications, sometimes blurred to abstract away the tedious numbers and present a risk statement. At the same time, judicious management of vulnerability instances and non-compliant configurations that exceed organization thresholds – i.e., all the numbers – requires very detailed and often painstaking focus on the minutiae of a VM program. Then, layer in the need for situational awareness to answer context-specific questions like, “Are we vulnerable, and if so, do we need to act immediately?" or “Why did the security patch fail on only 37 of the 2184 target systems?" It becomes glaringly apparent that communication and alignment among all stakeholders – security team, IT operations, and business leadership – are paramount to achieve “dependent” success.
Based on customer feedback and directional input, we’re pleased to release two updates that are aimed at not only improving VM program success but also reducing the effort to get you there.
Remediation Project progress
In what may be the most exciting and warmly received update for some, we are releasing a new method to calculate and display progress for Remediation Projects. Historically, credit for patching and subsequent reporting of "percent complete" toward closing any one Remediation Project was only given when all affected assets for a single solution were remediated. So we’ve updated the calculation to account for "partial" credit. Now, remediation teams will see incremental progress as individual assets for specific solutions (i.e. patches) are applied. This is a much more accurate representation of the work and effort invested. It is also a much more precise indication of what additional effort is needed to close out the last few pesky hosts that have so far resisted your best remediation efforts.
For some, the scope and scale of risk management in the world of VM has outgrown original designs – more assets, more vulns. We’ve acted on the sage wisdom of many who have suggested such an update and made that available in Version 6.6.150
This update will affect all Remediation Projects, so we encourage teams to leverage this blog post to share the details behind this release as a heads-up and possibly improve relations with your teammates. It’s only by partnering and aligning on the effort involved that this “success dependency” becomes a power-up, rather than a power drain.
Remediator Export
I am particularly excited about this seemingly minor but mighty update, because I can remember having to script around or find automation to stitch together different source documents to produce what we have elected to refer to as a Remediator Export. The number of stakeholders and the diversity of teams involved in modern VM programs necessitate on-demand access to the supporting data and associated context. This export is for – you guessed it – the teams that have the heaviest lift in any VM program: the folks that push patches, update configs, apply mitigating controls, and are usually involved in all the necessary testing – the Remediators. Whether the catalyst for such a detailed export (26 data fields in all) is to troubleshoot a failed install or to simply have more direct access to vulnerability proof data the Remediator Export will offer improvements for nearly every remediation team.
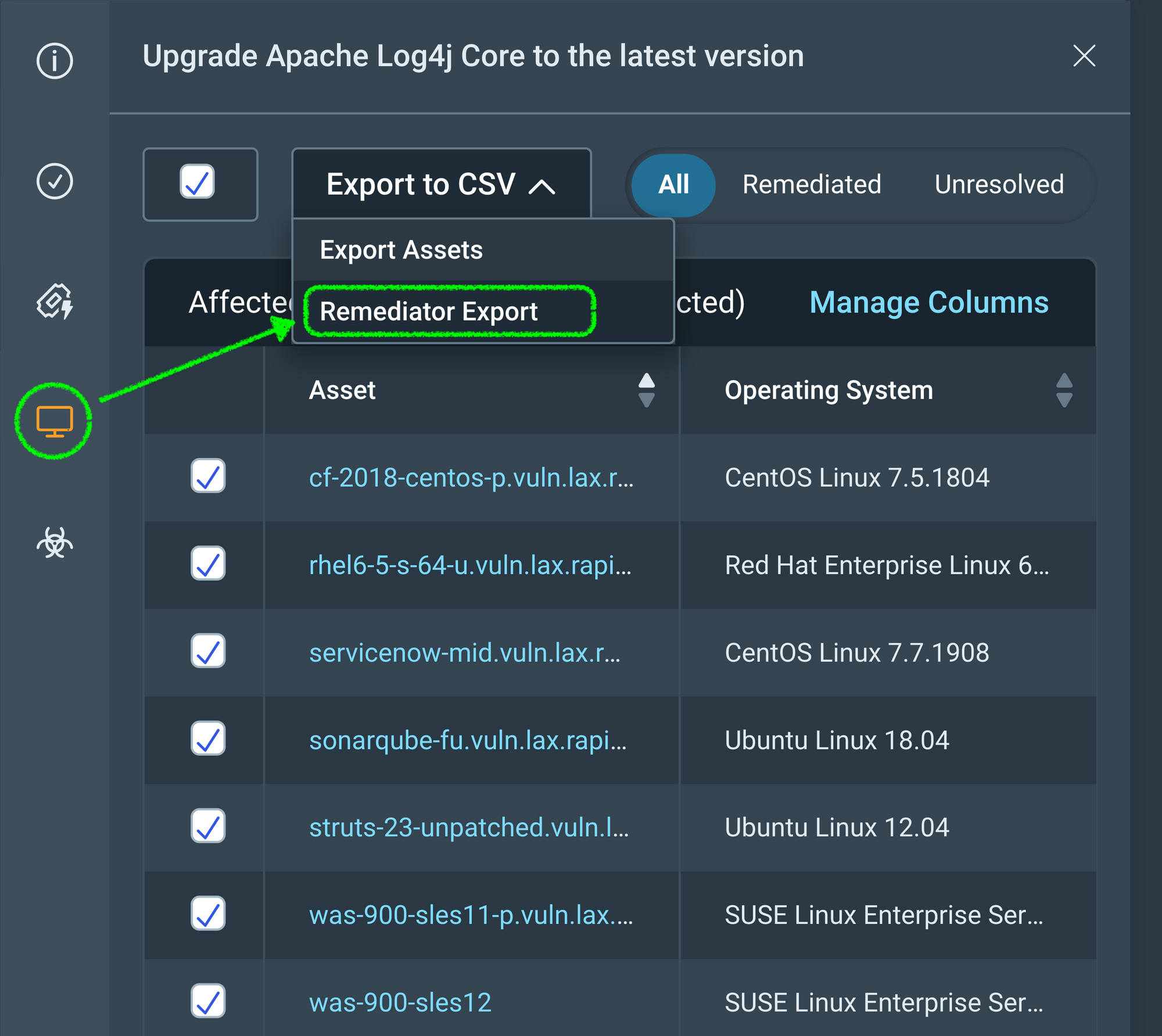
You can access this upcoming solution based export from any Remediation Project peek panel. The Export to CSV dropdown now has an additional option that includes the data fields cited above and helps meet team’s needs where they are today.
The Remediator CSV file is accessible to anyone with permission to Remediation Projects, Goals, and SLAsand carries the following naming convention: "Project-Name_Solution-UUID.csv." We are already thinking about options to provide similar capability at the Remediation Project level.